Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan filter kosakata khusus
Setelah filter kosakata kustom Anda dibuat, Anda dapat memasukkannya ke dalam permintaan transkripsi Anda; lihat bagian berikut untuk contoh.
Bahasa filter kosakata kustom yang Anda sertakan dalam permintaan Anda harus cocok dengan kode bahasa yang Anda tentukan untuk media Anda. Jika Anda menggunakan identifikasi bahasa dan menentukan beberapa opsi bahasa, Anda dapat menyertakan satu filter kosakata khusus per bahasa tertentu. Jika bahasa filter kosakata kustom Anda tidak cocok dengan bahasa yang diidentifikasi dalam audio Anda, filter Anda tidak diterapkan ke transkripsi Anda dan tidak ada peringatan atau kesalahan.
Menggunakan filter kosakata khusus dalam transkripsi batch
Untuk menggunakan filter kosakata khusus dengan transkripsi batch, lihat contoh berikut ini:
-
Masuk ke AWS Management Console
. -
Di panel navigasi, pilih Pekerjaan transkripsi, lalu pilih Buat pekerjaan (kanan atas). Ini membuka halaman Tentukan detail pekerjaan.
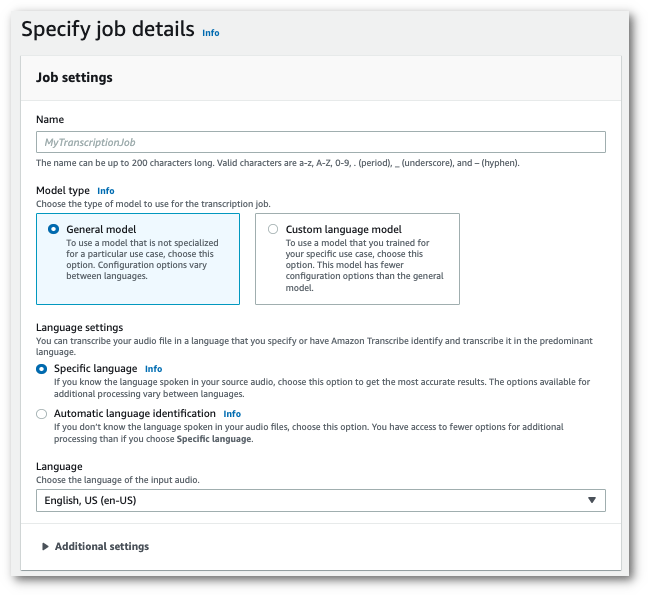
Beri nama pekerjaan Anda dan tentukan media masukan Anda. Secara opsional sertakan bidang lain, lalu pilih Berikutnya.
-
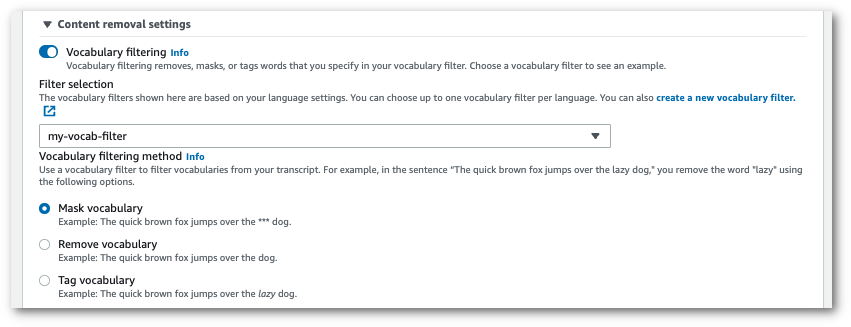
Pada halaman Configure job, di panel Penghapusan konten, aktifkan pemfilteran Kosakata.
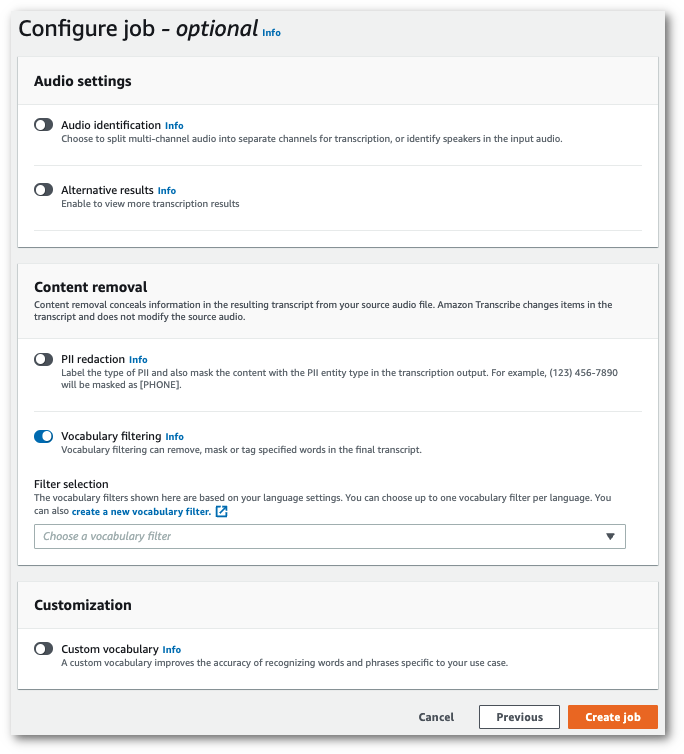
-
Pilih filter kosakata kustom Anda dari menu tarik-turun dan tentukan metode filtrasi.
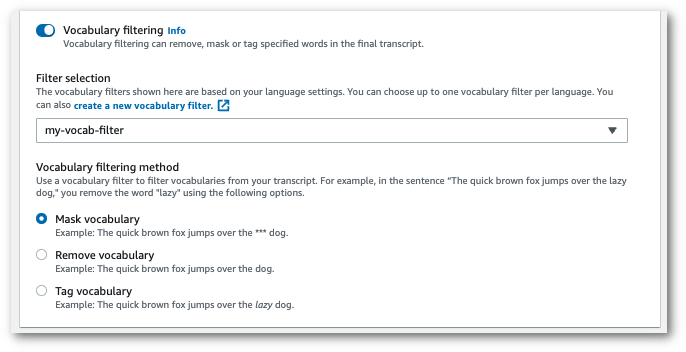
-
Pilih Buat pekerjaan untuk menjalankan pekerjaan transkripsi Anda.
Contoh ini menggunakan start-transcription-jobSettings parameter dengan VocabularyFilterName dan VocabularyFilterMethod sub-parameter. Untuk informasi selengkapnya, silakan lihat StartTranscriptionJob dan Settings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings VocabularyFilterName=my-first-vocabulary-filter,VocabularyFilterMethod=mask
Berikut contoh lain menggunakan start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-vocabulary-filter-job.json
File my-first-vocabulary-filter-job.json berisi badan permintaan berikut.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "VocabularyFilterName": "my-first-vocabulary-filter", "VocabularyFilterMethod": "mask" } }
Contoh ini menggunakan AWS SDK untuk Python (Boto3) untuk menyertakan filter kosakata khusus menggunakan Settings argumen untuk metode start_transcription_jobStartTranscriptionJob dan Settings.
Untuk contoh tambahan menggunakan AWS SDKs, termasuk contoh khusus fitur, skenario, dan lintas layanan, lihat bagian ini. Contoh kode untuk Amazon Transcribe menggunakan AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'VocabularyFilterName': 'my-first-vocabulary-filter', 'VocabularyFilterMethod': 'mask' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Menggunakan filter kosakata khusus dalam transkripsi streaming
Untuk menggunakan filter kosakata khusus dengan transkripsi streaming, lihat contoh berikut ini:
-
Masuk ke AWS Management Console
. -
Di panel navigasi, pilih Transkripsi waktu nyata. Gulir ke bawah ke pengaturan penghapusan konten dan perluas bidang ini jika diminimalkan.
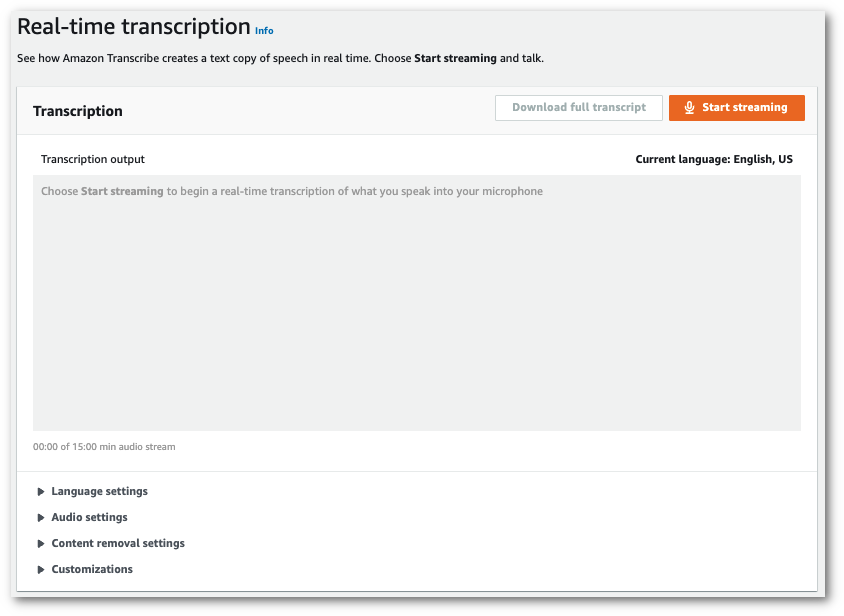
-
Beralih pada pemfilteran Kosakata. Pilih filter kosakata khusus dari menu tarik-turun dan tentukan metode filtrasi.
Sertakan pengaturan lain yang ingin Anda terapkan ke streaming Anda.
-
Anda sekarang siap untuk mentranskripsikan aliran Anda. Pilih Mulai streaming dan mulai berbicara. Untuk mengakhiri dikte Anda, pilih Hentikan streaming.
Contoh ini membuat permintaan HTTP/2 yang menyertakan filter kosakata kustom dan metode filter Anda. Untuk informasi lebih lanjut tentang menggunakan streaming HTTP/2 dengan Amazon Transcribe, lihat. Menyiapkan aliran HTTP/2 Untuk detail selengkapnya tentang parameter dan header khusus untuk Amazon Transcribe, lihat StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-vocabulary-filter-name:my-first-vocabulary-filterx-amzn-transcribe-vocabulary-filter-method:masktransfer-encoding: chunked
Definisi parameter dapat ditemukan di Referensi API; parameter yang umum untuk semua operasi AWS API tercantum di bagian Parameter Umum.
Contoh ini membuat URL presigned yang menerapkan filter kosakata kustom Anda ke aliran. WebSocket Jeda baris telah ditambahkan untuk keterbacaan. Untuk informasi selengkapnya tentang penggunaan WebSocket stream dengan Amazon Transcribe, lihatMenyiapkan WebSocket aliran. Untuk detail lebih lanjut tentang parameter, lihat StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&vocabulary-filter-name=my-first-vocabulary-filter&vocabulary-filter-method=mask
Definisi parameter dapat ditemukan di Referensi API; parameter yang umum untuk semua operasi AWS API tercantum di bagian Parameter Umum.
