Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengukur ketersediaan
Seperti yang kita lihat sebelumnya, membuat model ketersediaan berwawasan ke depan untuk sistem terdistribusi sulit dilakukan dan mungkin tidak memberikan wawasan yang diinginkan. Apa yang dapat memberikan lebih banyak utilitas adalah mengembangkan cara yang konsisten untuk mengukur ketersediaan beban kerja Anda.
Definisi ketersediaan sebagai uptime dan downtime mewakili kegagalan sebagai opsi biner, baik beban kerja sudah habis atau tidak.
Namun, ini jarang terjadi. Kegagalan memiliki tingkat dampak dan sering dialami dalam beberapa bagian dari beban kerja, mempengaruhi persentase pengguna atau permintaan, persentase lokasi, atau persentil latensi. Ini semua adalah mode kegagalan sebagian.
Dan sementara MTTR dan MTBF berguna dalam memahami apa yang mendorong ketersediaan sistem yang dihasilkan, dan karenanya, bagaimana memperbaikinya, utilitas mereka bukan sebagai ukuran ketersediaan empiris. Selain itu, beban kerja terdiri dari banyak komponen. Misalnya, beban kerja seperti sistem pemrosesan pembayaran terdiri dari banyak antarmuka pemrograman aplikasi (API) dan subsistem. Jadi, ketika kita ingin mengajukan pertanyaan seperti, “apa ketersediaan seluruh beban kerja?” , itu sebenarnya pertanyaan yang kompleks dan bernuansa.
Di bagian ini, kita akan memeriksa tiga cara ketersediaan dapat diukur secara empiris: tingkat keberhasilan permintaan sisi server, tingkat keberhasilan permintaan sisi klien, dan waktu henti tahunan.
Tingkat keberhasilan permintaan sisi server dan sisi klien
Dua metode pertama sangat mirip, hanya berbeda dari sudut pandang pengukuran yang diambil. Metrik sisi server dapat dikumpulkan dari instrumentasi dalam layanan. Namun, mereka tidak lengkap. Jika klien tidak dapat mencapai layanan, Anda tidak dapat mengumpulkan metrik tersebut. Untuk memahami pengalaman klien, alih-alih mengandalkan telemetri dari klien tentang permintaan yang gagal, cara yang lebih mudah untuk mengumpulkan metrik sisi klien adalah dengan mensimulasikan lalu lintas pelanggan dengan burung kenari, perangkat lunak yang secara teratur menyelidiki layanan Anda dan mencatat metrik.
Kedua metode ini menghitung ketersediaan sebagai fraksi dari total unit kerja valid yang diterima layanan dan yang berhasil diprosesnya (ini mengabaikan unit kerja yang tidak valid, seperti permintaan HTTP yang menghasilkan kesalahan 404).

Persamaan 8
Untuk layanan berbasis permintaan, unit kerja adalah permintaan, seperti permintaan HTTP. Untuk layanan berbasis acara atau berbasis tugas, unit pekerjaan adalah acara atau tugas, seperti memproses pesan dari antrian. Ukuran ketersediaan ini bermakna dalam interval waktu singkat, seperti jendela satu menit atau lima menit. Hal ini juga paling cocok pada perspektif granular, seperti pada tingkat per API untuk layanan berbasis permintaan. Gambar berikut memberikan pandangan tentang apa ketersediaan dari waktu ke waktu mungkin terlihat seperti ketika dihitung dengan cara ini. Setiap titik data pada grafik dihitung menggunakan Persamaan (8) selama jendela lima menit (Anda dapat memilih dimensi waktu lain seperti interval satu menit atau sepuluh menit). Misalnya, titik data 10 menunjukkan ketersediaan 94,5%. Itu berarti selama menit t+45 hingga t+50 jika layanan menerima 1.000 permintaan, hanya 945 di antaranya yang berhasil diproses.
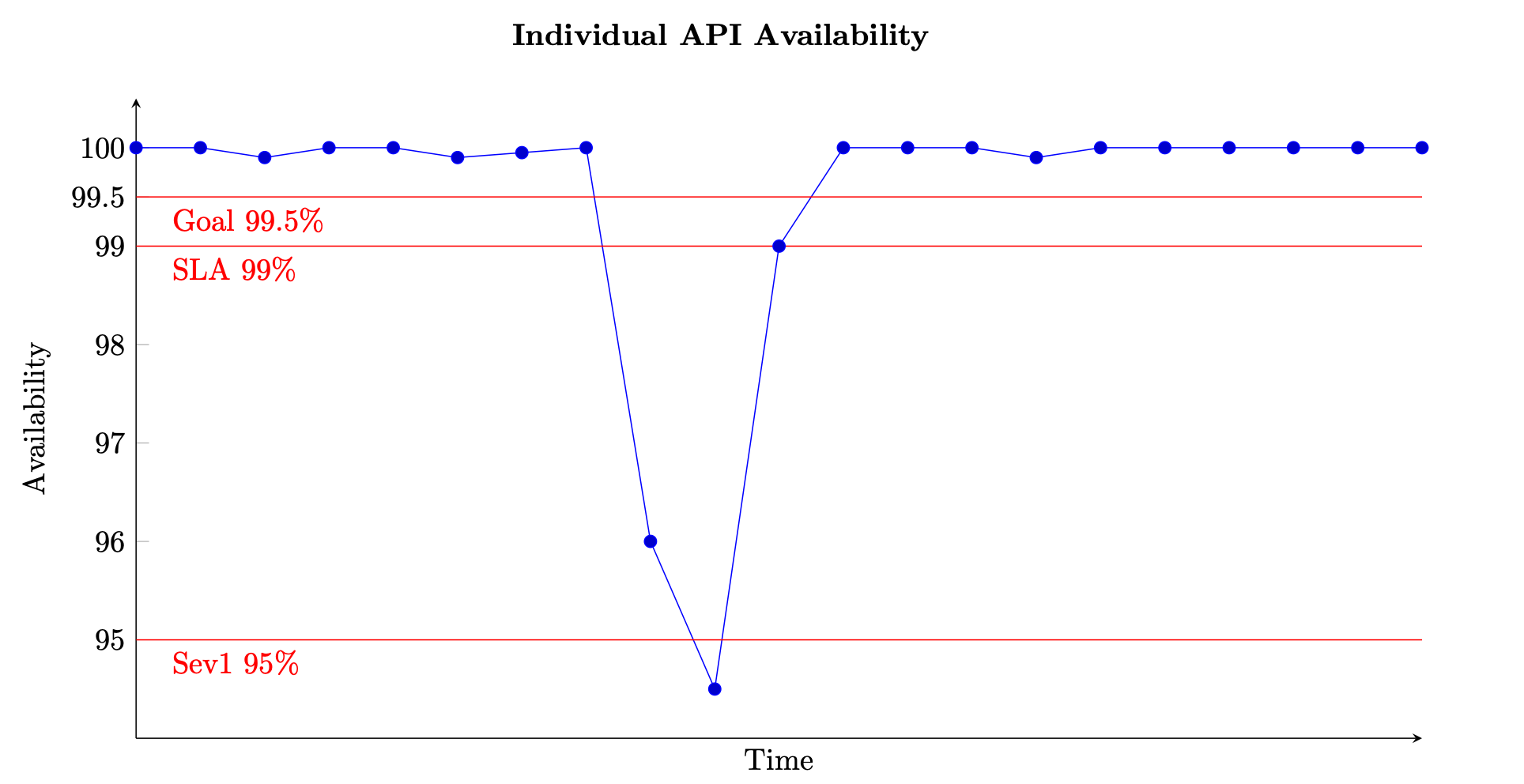
Contoh pengukuran ketersediaan dari waktu ke waktu untuk satu API
Grafik juga menunjukkan sasaran ketersediaan API, ketersediaan 99,5%, perjanjian tingkat layanan (SLA) yang ditawarkannya kepada pelanggan, ketersediaan 99%, dan ambang batas untuk alarm tingkat keparahan tinggi, 95%. Tanpa konteks ambang batas yang berbeda ini, grafik ketersediaan mungkin tidak memberikan wawasan yang signifikan tentang bagaimana layanan Anda beroperasi.
Kami juga ingin dapat melacak dan menggambarkan ketersediaan subsistem yang lebih besar, seperti bidang kontrol, atau seluruh layanan. Salah satu cara untuk melakukan ini adalah dengan mengambil rata-rata setiap titik data lima menit untuk setiap subsistem. Grafik akan terlihat mirip dengan yang sebelumnya, tetapi akan mewakili satu set input yang lebih besar. Ini juga memberikan bobot yang sama untuk semua subsistem yang membentuk layanan Anda. Pendekatan alternatif mungkin untuk menjumlahkan semua permintaan yang diterima dan berhasil diproses dari semua API dalam layanan untuk menghitung ketersediaan dalam interval lima menit.
Namun, metode terakhir ini mungkin menyembunyikan API individual yang memiliki throughput rendah dan ketersediaan buruk. Sebagai contoh sederhana, pertimbangkan layanan dengan dua API.
API pertama menerima 1.000.000 permintaan dalam jendela lima menit dan berhasil memproses 999.000 dari mereka, memberikan ketersediaan 99,9%. API kedua menerima 100 permintaan dalam jendela lima menit yang sama dan hanya berhasil memproses 50 dari mereka, memberikan ketersediaan 50%.
Jika kami menjumlahkan permintaan dari setiap API bersama-sama, ada 1.000.100 total permintaan valid dan 999.050 di antaranya berhasil diproses, memberikan ketersediaan 99.895% untuk layanan secara keseluruhan. Tetapi, jika kita rata-rata ketersediaan dari dua API, metode sebelumnya, kita mendapatkan ketersediaan yang dihasilkan 74.95%, yang mungkin lebih menceritakan pengalaman sebenarnya.
Tidak ada pendekatan yang salah, tetapi ini menunjukkan pentingnya memahami apa yang diberitahukan metrik ketersediaan kepada Anda. Anda dapat memilih untuk mendukung penjumlahan permintaan untuk semua subsistem jika beban kerja Anda menerima volume permintaan serupa di masing-masing subsistem. Pendekatan ini berfokus pada “permintaan” dan keberhasilannya sebagai ukuran ketersediaan dan pengalaman pelanggan. Atau, Anda dapat memilih untuk rata-rata ketersediaan subsistem untuk sama-sama mewakili kekritisan mereka meskipun perbedaan volume permintaan. Pendekatan ini berfokus pada subsistem dan kemampuan masing-masing sebagai proxy untuk pengalaman pelanggan.
Downtime tahunan
Pendekatan ketiga adalah menghitung downtime tahunan. Bentuk metrik ketersediaan ini lebih sesuai untuk penetapan dan peninjauan tujuan jangka panjang. Hal ini membutuhkan mendefinisikan apa arti downtime untuk beban kerja Anda. Anda kemudian dapat mengukur ketersediaan berdasarkan jumlah menit bahwa beban kerja tidak dalam kondisi “pemadaman” relatif terhadap jumlah menit dalam periode tertentu.
Beberapa beban kerja mungkin dapat menentukan waktu henti sebagai sesuatu seperti penurunan di bawah 95% ketersediaan API tunggal atau fungsi beban kerja untuk interval satu menit atau lima menit (yang terjadi pada grafik ketersediaan sebelumnya). Anda mungkin juga hanya mempertimbangkan waktu henti karena berlaku untuk subset operasi bidang data penting. Misalnya, Perjanjian Tingkat Layanan Amazon Messaging (SQS, SNS)
Beban kerja yang lebih besar dan lebih kompleks mungkin perlu menentukan metrik ketersediaan di seluruh sistem. Untuk situs e-commerce besar, metrik seluruh sistem dapat menjadi sesuatu seperti tingkat pesanan pelanggan. Di sini, penurunan 10% atau lebih dalam pesanan dibandingkan dengan kuantitas yang diperkirakan selama jendela lima menit dapat menentukan waktu henti.
Dalam kedua pendekatan, Anda kemudian dapat menjumlahkan semua periode pemadaman untuk menghitung ketersediaan tahunan. Misalnya, jika selama tahun kalender, ada 27 periode waktu henti lima menit, yang didefinisikan sebagai ketersediaan API bidang data yang turun di bawah 95%, waktu henti keseluruhan adalah 135 menit (beberapa periode lima menit mungkin berturut-turut, yang lain terisolasi), mewakili ketersediaan tahunan 99,97%.
Metode pengukuran ketersediaan tambahan ini dapat memberikan data dan wawasan yang hilang dari sisi klien dan metrik sisi server. Misalnya, pertimbangkan beban kerja yang terganggu dan mengalami peningkatan tingkat kesalahan secara signifikan. Pelanggan beban kerja ini mungkin berhenti melakukan panggilan ke layanannya sama sekali. Mungkin mereka telah mengaktifkan pemutus sirkuit atau mengikuti rencana pemulihan bencana mereka
Latensi
Akhirnya, penting juga untuk mengukur latensi unit pemrosesan pekerjaan dalam beban kerja Anda. Bagian dari definisi ketersediaan adalah melakukan pekerjaan dalam SLA mapan. Jika mengembalikan respons membutuhkan waktu lebih lama dari batas waktu klien, persepsi dari klien adalah bahwa permintaan gagal dan beban kerja tidak tersedia. Namun, di sisi server, permintaan mungkin tampaknya telah diproses dengan sukses.
Mengukur latensi menyediakan lensa lain yang dapat digunakan untuk mengevaluasi ketersediaan. Menggunakan persentil dan rata-rata yang dipangkas adalah statistik yang baik untuk pengukuran ini. Mereka biasanya diukur pada persentil ke-50 (P50 dan TM50) dan persentil ke-99 (P99 dan TM99). Latensi harus diukur dengan kenari untuk mewakili pengalaman klien serta dengan metrik sisi server. Setiap kali rata-rata beberapa latensi persentil, seperti P99 atau TM99.9, berada di atas target SLA, Anda dapat mempertimbangkan bahwa downtime, yang berkontribusi pada perhitungan downtime tahunan Anda.
