Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pengantar
Keamanan adalah prioritas utama di AWS. Pelanggan AWS diuntungkan dengan pusat data dan arsitektur jaringan yang dibangun untuk membantu mendukung kebutuhan organisasi yang paling peka dalam urusan keamanan. AWS memiliki model tanggung jawab bersama: AWS mengelola keamanan dari cloud, sedangkan pelanggan bertanggung jawab atas keamanan di cloud. Artinya, Anda memiliki kendali penuh atas implementasi keamanan Anda, termasuk akses ke beberapa alat dan layanan untuk membantu memenuhi tujuan keamanan Anda. Berbagai kemampuan ini membantu Anda menetapkan garis dasar keamanan untuk aplikasi yang berjalan di AWS Cloud.
Ketika terjadi penyimpangan dari garis dasar, misalnya karena kesalahan konfigurasi atau perubahan faktor eksternal, Anda perlu merespons dan menyelidikinya. Agar bisa melakukannya dengan baik, Anda perlu memahami konsep dasar respons insiden keamanan di lingkungan AWS Anda dan persyaratan untuk mempersiapkan, mengedukasi, dan melatih tim cloud sebelum masalah keamanan terjadi. Penting untuk mengetahui kontrol dan kemampuan mana yang dapat Anda gunakan, meninjau contoh topikal untuk mengatasi masalah potensial, dan mengidentifikasi metode remediasi yang menggunakan otomatisasi untuk meningkatkan kecepatan dan konsistensi respons. Selain itu, Anda harus memahami persyaratan kepatuhan dan peraturan karena hal ini berkaitan dengan pembuatan program respons insiden keamanan untuk memenuhi persyaratan tersebut.
Respons insiden keamanan bisa menjadi hal yang kompleks, jadi kami mendorong Anda untuk menerapkan pendekatan iteratif: mulai dengan layanan keamanan inti, membangun kemampuan deteksi dan respons dasar, kemudian mengembangkan playbook untuk membuat pustaka awal mekanisme respons insiden yang dapat diiterasi dan ditingkatkan.
Sebelum Anda mulai
Sebelum Anda mulai belajar tentang respons insiden keamanan di AWS, pahami berbagai standar dan kerangka kerja yang relevan untuk keamanan AWS dan respons insiden. Fondasi ini akan membantu Anda memahami konsep dan praktik terbaik yang disajikan dalam panduan ini.
Standar dan kerangka kerja keamanan AWS
Untuk memulai, kami mendorong Anda untuk meninjau Praktik Terbaik untuk Keamanan, Identitas, dan Kepatuhan, Pilar Keamanan - Kerangka Kerja AWS Well-Architected
AWS CAF menyediakan panduan yang mendukung koordinasi antara berbagai bagian organisasi yang berpindah ke cloud. Panduan AWS CAF dibagi menjadi beberapa area fokus, yang disebut sebagai perspektif, yang relevan untuk membangun sistem IT berbasis cloud. Perspektif keamanan menjelaskan cara menerapkan program keamanan di seluruh alur kerja, salah satunya adalah respons insiden. Dokumen ini merupakan produk dari pengalaman kami bekerja dengan pelanggan untuk membantu mereka membangun kemampuan serta program respons insiden keamanan yang efektif dan efisien.
Standar dan kerangka kerja respons insiden industri
Laporan resmi ini mengikuti standar respons insiden dan praktik terbaik dari Computer Security Incident Handling Guide SP 800-61 r2
Ikhtisar respons insiden AWS
Sebagai awal, penting untuk memahami bagaimana operasi keamanan dan respons insiden merupakan hal yang berbeda di cloud. Untuk membangun kemampuan respons yang efektif di AWS, Anda perlu memahami perbedaannya dengan respons on-premise tradisional dan dampaknya terhadap program respons insiden Anda. Setiap perbedaan ini, serta prinsip desain respons insiden AWS inti, dijelaskan secara mendetail dalam bagian ini.
Aspek-aspek respons insiden AWS
Semua pengguna AWS dalam suatu organisasi harus memiliki pemahaman dasar tentang proses respons insiden keamanan, dan staf keamanan harus memahami bagaimana merespons masalah keamanan. Pendidikan, pelatihan, dan pengalaman sangat penting agar program respons insiden cloud berjalan dengan baik, dan idealnya diimplementasikan dengan baik sebelum harus menangani kemungkinan insiden keamanan. Fondasi program respons insiden yang baik di cloud adalah Persiapan, Operasi, dan Aktivitas Pascainsiden.
Untuk memahami setiap aspek ini, lihat deskripsi berikut:
-
Persiapan – Persiapkan tim respons insiden Anda untuk mendeteksi dan merespons insiden dalam AWS dengan mengaktifkan kontrol detektif dan memverifikasi akses yang sesuai ke alat dan layanan cloud yang diperlukan. Selain itu, siapkan playbook yang diperlukan, baik manual maupun otomatis, untuk memverifikasi respons yang andal dan konsisten.
-
Operasi – Beroperasi pada peristiwa keamanan dan insiden potensial setelah fase respons insiden NIST: mendeteksi, menganalisis, menahan, memberantas, dan memulihkan.
-
Aktivitas pascainsiden – Lakukan iterasi pada hasil simulasi dan peristiwa keamanan Anda untuk meningkatkan efektivitas respons Anda, sehingga respons dan investigasi yang dilakukan bisa lebih bernilai, dan mengurangi risiko lebih lanjut. Anda harus belajar dari insiden dan memiliki sikap kepemilikan yang kuat terhadap aktivitas perbaikan.
Setiap aspek ini dikupas dan dibahas secara mendetail dalam panduan ini. Diagram berikut menunjukkan alur aspek-aspek ini, selaras dengan siklus hidup respons insiden NIST yang disebutkan sebelumnya, tetapi dengan operasi yang mencakup deteksi dan analisis dengan penahanan, pemberantasan, dan pemulihan.
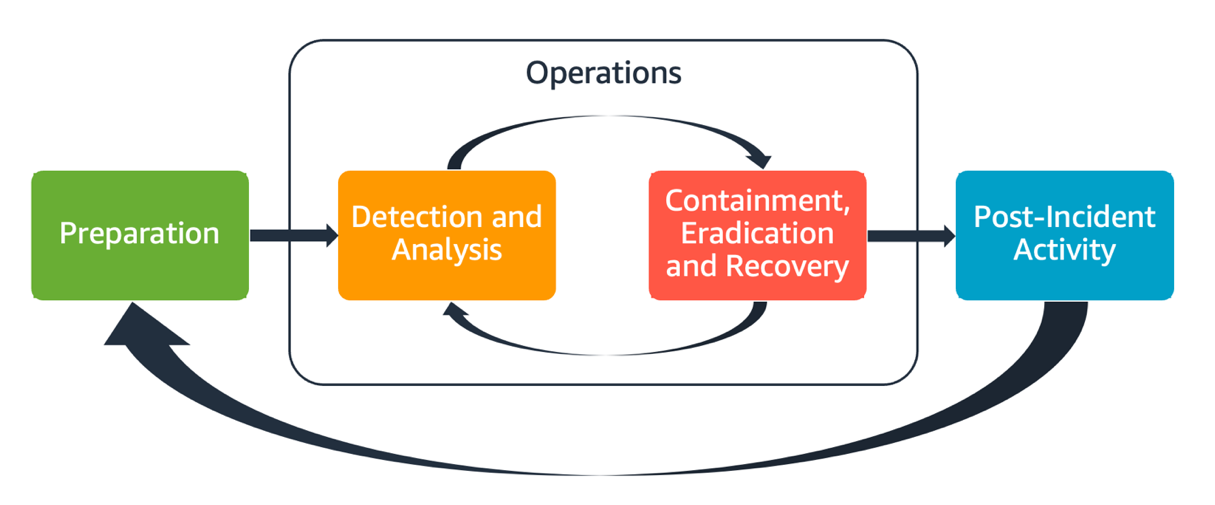
Aspek-aspek respons insiden AWS
Prinsip respons insiden AWS dan tujuan desain
Meskipun proses umum dan mekanisme respons insiden sebagaimana didefinisikan oleh NIST SP 800-61 Computer Security Incident Handling Guide
-
Menetapkan tujuan respons – Bekerja sama dengan pemangku kepentingan, penasihat hukum, dan kepemimpinan organisasi untuk menentukan tujuan dalam merespons suatu insiden. Beberapa tujuan umum termasuk menahan dan memitigasi masalah, memulihkan sumber daya yang terkena dampak, menyimpan data untuk forensik, kembali ke operasi aman yang diketahui, dan belajar dari insiden.
-
Merespons menggunakan cloud – Menerapkan pola respons di dalam cloud, tempat peristiwa dan data terjadi.
-
Ketahui apa yang Anda miliki dan apa yang Anda butuhkan – Simpan log, sumber daya, snapshot, dan bukti lainnya dengan menyalin dan menyimpannya di akun cloud terpusat khusus untuk respons. Gunakan tag, metadata, dan mekanisme yang menerapkan kebijakan retensi. Anda harus memahami layanan apa yang Anda gunakan, lalu mengidentifikasi persyaratan untuk menginvestigasi layanan tersebut. Untuk membantu Anda memahami lingkungan Anda, Anda juga dapat menggunakan tag, yang akan dibahas nanti dalam dokumen ini di bagian Mengembangkan dan menerapkan strategi pemberian tag.
-
Gunakan mekanisme deployment ulang – Jika anomali keamanan dapat dikaitkan dengan kesalahan konfigurasi, remediasinya mungkin cukup dengan menghapus varians dengan deployment ulang sumber daya menggunakan konfigurasi yang tepat. Jika teridentifikasi adanya kemungkinan penyusupan, verifikasi bahwa deployment ulang Anda mencakup mitigasi akar penyebab yang berhasil dan terverifikasi.
-
Otomatiskan jika memungkinkan – Ketika masalah muncul atau insiden berulang, bangun mekanisme untuk melakukan triase secara terprogram dan merespons peristiwa umum. Gunakan respons manusia untuk insiden unik, kompleks, atau sensitif yang tidak cukup dengan otomatisasi.
-
Pilih solusi yang dapat diskalakan – Berusahalah untuk mengimbangi skalabilitas pendekatan organisasi Anda terhadap komputasi cloud. Terapkan mekanisme deteksi dan respons yang dapat diskalakan di seluruh lingkungan Anda agar dapat memangkas waktu antara deteksi dan respons secara efektif.
-
Pelajari dan tingkatkan proses Anda – Bersikaplah proaktif ketika mengidentifikasi kesenjangan dalam proses, alat, atau orang Anda, dan terapkan rencana untuk memperbaikinya. Simulasi adalah metode yang aman untuk menemukan kesenjangan dan memperbaiki proses. Lihat bagian Aktivitas pascainsiden di dokumen ini untuk detail tentang cara melakukan iterasi proses Anda.
Sasaran desain ini merupakan pengingat untuk meninjau implementasi arsitektur Anda agar dapat melakukan respons insiden dan deteksi ancaman. Saat Anda merencanakan implementasi cloud Anda, pikirkan tentang merespons suatu insiden, idealnya dengan metodologi respons yang baik secara forensik. Dalam beberapa kasus, ini berarti Anda mungkin memiliki beberapa organisasi, akun, dan alat yang secara khusus disiapkan untuk tugas respons ini. Alat dan fungsi ini harus tersedia bagi responden insiden melalui alur deployment. Alat dan fungsi tersebut tidak boleh statis karena dapat menyebabkan risiko yang lebih besar.
Domain insiden keamanan cloud
Untuk mempersiapkan dan merespons peristiwa keamanan secara efektif di lingkungan AWS Anda, Anda perlu memahami jenis umum insiden keamanan cloud. Ada tiga domain dalam tanggung jawab pelanggan tempat insiden keamanan dapat terjadi: layanan, infrastruktur, dan aplikasi. Domain yang berbeda membutuhkan pengetahuan, alat, dan proses respons yang berbeda. Pertimbangkan domain berikut:
-
Domain layanan – Insiden dalam domain layanan dapat memengaruhi akun AWS Anda, izin AWS Identity and Access Management
(IAM), metadata sumber daya, penagihan, atau area lainnya. Peristiwa domain layanan adalah peristiwa yang Anda respons secara eksklusif dengan mekanisme AWS API, atau ketika Anda memiliki akar penyebab yang terkait dengan konfigurasi atau izin sumber daya, dan mungkin memiliki pencatatan log berorientasi layanan terkait. -
Domain infrastruktur – Insiden dalam domain infrastruktur mencakup data atau aktivitas terkait jaringan, seperti proses dan data pada instans Amazon Elastic Compute Cloud
(Amazon EC2), lalu lintas ke instans Amazon EC2 Anda dalam cloud privat virtual (VPC), dan area lainnya, seperti kontainer atau layanan lain ke depannya. Respons Anda terhadap peristiwa domain infrastruktur sering kali melibatkan perolehan data terkait insiden untuk analisis forensik. Hal ini mungkin mencakup interaksi dengan sistem operasi sebuah instans, dan, dalam berbagai kasus, mungkin juga melibatkan mekanisme AWS API. Dalam domain infrastruktur, Anda dapat menggunakan kombinasi AWS API dan alat forensik/respons insiden (DFIR) digital dalam sistem operasi tamu, seperti instans Amazon EC2 yang didedikasikan untuk melakukan analisis dan investigasi forensik. Insiden domain infrastruktur mungkin melibatkan analisis tangkapan paket jaringan, blok disk pada volume Amazon Elastic Block Store (Amazon EBS), atau memori volatil yang diperoleh dari sebuah instans. -
Domain aplikasi – Insiden dalam domain aplikasi terjadi dalam kode aplikasi atau dalam perangkat lunak yang di-deploy untuk layanan atau infrastruktur. Domain ini harus disertakan dalam playbook deteksi dan respons ancaman cloud Anda, dan dapat menyertakan respons serupa dengan yang ada di domain infrastruktur. Dengan arsitektur aplikasi yang tepat dan cermat, Anda dapat mengelola domain ini dengan alat cloud menggunakan akuisisi, pemulihan, dan deployment otomatis.
Dalam domain ini, pertimbangkan aktor yang mungkin bertindak melawan data, sumber daya, atau akun AWS. Baik internal maupun eksternal, gunakan kerangka risiko untuk menentukan risiko spesifik bagi organisasi dan melakukan persiapan sebagaimana mestinya. Selain itu, Anda harus mengembangkan model ancaman, yang dapat membantu perencanaan respons insiden dan pembangunan arsitektur yang cermat.
Perbedaan utama respons insiden di AWS
Respons insiden merupakan bagian integral dari strategi keamanan siber, baik on-premise maupun di cloud. Prinsip keamanan seperti hak istimewa paling rendah dan defense-in-depth bermaksud untuk melindungi kerahasiaan, integritas, dan ketersediaan data baik lokal maupun di cloud. Beberapa pola respons insiden yang mendukung prinsip-prinsip keamanan ini mengikuti, termasuk retensi log, pemilihan peringatan yang berasal dari pemodelan ancaman, pengembangan playbook, serta integrasi informasi keamanan dan manajemen peristiwa (SIEM). Perbedaannya dimulai ketika pelanggan mulai merancang dan merekayasa pola-pola ini di cloud. Berikut ini adalah perbedaan utama respons insiden di AWS.
Perbedaan #1: Keamanan sebagai tanggung jawab bersama
Tanggung jawab atas keamanan dan kepatuhan dibagi antara AWS dan pelanggannya. Model tanggung jawab bersama ini mengurangi beban operasional pelanggan karena AWS mengoperasikan, mengelola, dan mengontrol komponen dari sistem operasi host dan lapisan virtualisasi hingga keamanan fisik fasilitas tempat layanan beroperasi. Untuk detail lebih lanjut tentang model tanggung jawab bersama, lihat dokumentasi Model Tanggung Jawab Bersama
Saat tanggung jawab bersama Anda di cloud berubah, opsi Anda untuk respons insiden juga berubah. Merencanakan dan memahami timbal balik ini serta mencocokkannya dengan kebutuhan tata kelola Anda adalah langkah penting dalam respons insiden.
Selain hubungan langsung yang Anda miliki dengan AWS, mungkin ada entitas lain yang memiliki tanggung jawab dalam model tanggung jawab khusus Anda. Misalnya, Anda mungkin memiliki unit organisasi internal yang bertanggung jawab atas beberapa aspek operasi Anda. Anda mungkin juga memiliki partner atau pihak lain yang mengembangkan, mengelola, atau mengoperasikan beberapa teknologi cloud Anda.
Membuat dan menguji rencana respons insiden yang sesuai dan playbook yang sesuai dengan model operasi Anda sangatlah penting.
Perbedaan #2: Domain layanan cloud
Karena perbedaan tanggung jawab keamanan yang ada di layanan cloud, diperkenalkanlah domain baru untuk insiden keamanan: domain layanan, yang dijelaskan sebelumnya di bagian Domain insiden. Domain layanan mencakup akun AWS pelanggan, izin IAM, metadata sumber daya, penagihan, dan area lainnya. Domain ini berbeda untuk respons insiden karena cara meresponsnya. Respons dalam domain layanan biasanya dilakukan dengan meninjau dan mengeluarkan panggilan API, bukan respons berbasis host dan berbasis jaringan tradisional. Dalam domain layanan, Anda tidak akan berinteraksi dengan sistem operasi sumber daya yang terpengaruh.
Diagram berikut menunjukkan contoh peristiwa keamanan dalam domain layanan berdasarkan anti-pola arsitektur. Dalam peristiwa ini, pengguna yang tidak sah mendapatkan kredensial keamanan jangka panjang dari pengguna IAM. Pengguna IAM memiliki kebijakan IAM yang memungkinkan mereka mengambil objek dari bucket Amazon Simple Storage Service
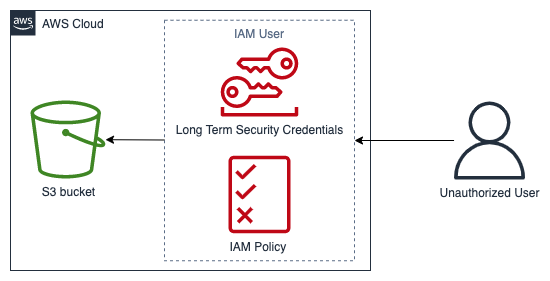
Contoh domain layanan
Perbedaan #3: API untuk penyediaan infrastruktur
Perbedaan lain berasal dari Karakteristik cloud layanan mandiri on-demand
Karena sifat AWS yang berbasis API, sumber log yang penting untuk merespons peristiwa keamanan adalah AWS CloudTrail, yang melacak panggilan API manajemen yang dibuat di akun AWS Anda dan tempat Anda dapat menemukan informasi tentang lokasi sumber panggilan API.
Perbedaan #4: Sifat dinamis cloud
Cloud bersifat dinamis; memungkinkan Anda membuat dan menghapus sumber daya dengan cepat. Dengan penskalaan otomatis, sumber daya dapat dinaikkan dan diturunkan berdasarkan peningkatan lalu lintas. Dengan infrastruktur berumur pendek dan perubahan yang serbacepat, sumber daya yang Anda selidiki mungkin sudah tidak ada lagi atau mungkin telah dimodifikasi. Memahami sifat sumber daya AWS yang fana dan bagaimana Anda dapat melacak pembuatan dan penghapusan sumber daya AWS akan menjadi hal yang penting untuk analisis insiden. Anda dapat menggunakan AWS Config
Perbedaan #5: Akses data
Akses data juga berbeda di cloud. Anda tidak dapat terhubung ke server untuk mengumpulkan data yang Anda butuhkan untuk penyelidikan keamanan. Data dikumpulkan melalui kabel dan melalui panggilan API. Anda harus berlatih dan memahami cara melakukan pengumpulan data melalui API agar siap menghadapi pergeseran ini, dan memverifikasi penyimpanan yang sesuai untuk pengumpulan dan akses yang efektif.
Perbedaan #6: Pentingnya otomatisasi
Agar pelanggan dapat sepenuhnya menyadari manfaat adopsi cloud, strategi operasional mereka harus menerapkan otomatisasi. I nfrastructure-as-code (IAc) adalah pola lingkungan otomatis yang sangat efisien di mana AWS layanan dikerahkan, dikonfigurasi, dikonfigurasi ulang, dan dihancurkan menggunakan kode yang difasilitasi oleh layanan IAc asli seperti atau solusi pihak ketiga. AWS CloudFormation
Mengatasi perbedaan-perbedaan ini
Untuk mengatasi perbedaan ini, ikuti langkah-langkah yang diuraikan di bagian berikutnya untuk memverifikasi bahwa program respons insiden Anda untuk orang, proses, dan teknologi dipersiapkan dengan baik.
