Amazon DocumentDB architecture
The following diagram shows the main components of Amazon DocumentDB.

Amazon DocumentDB architecture
-
Cluster — A cluster consists of one or more instances that provide the compute, and a cluster volume that manages the data for the instances. A cluster can have up to 16 instances (a primary and up to 15 read replicas). Cluster instances need not be all of the same instance size.
-
Primary instance — An instance that supports read/write workloads and performs all the data modifications to the cluster volume. Each Amazon DocumentDB cluster has one primary instance.
-
Cluster volume — The cluster volume provides SSD-backed distributed storage for your database. The primary instance and any Amazon DocumentDB replicas share the same cluster volume.
-
Replicas — An Amazon DocumentDB replica supports only read operations, and each DB cluster can have up to 15 Amazon DocumentDB replicas. In case the primary instance fails, one of the Amazon DocumentDB replicas is promoted as the primary.
High availability
Amazon DocumentDB has a number of features that make it highly available.
Highly available distributed storage
Amazon DocumentDB replicates your data six ways across three Availability Zones. The cluster volume spans three Availability Zones in a single AWS Region, and each Availability Zone contains two copies of the cluster volume data. This functionality means that Amazon DocumentDB can transparently handle the loss of up to two data copies or an Availability Zone failure without losing write availability, or the loss of up to three data copies without losing read availability.

Amazon DocumentDB tolerates loss of three copies of data
Near instant crash recovery
Amazon DocumentDB is designed to recover from a crash almost instantaneously. Unlike other databases, Amazon DocumentDB does not need to replay redo logs after a crash before making the database available for operations. The storage is organized in many small segments and Amazon DocumentDB can perform crash recovery asynchronously on parallel threads. This approach reduces database restart times to less than 30 seconds in most cases.
Automatic failover without data loss
Amazon DocumentDB uses automated checks to detect failure of the primary instance in a cluster. If the primary instance fails, Amazon DocumentDB automatically fails over to any of up to 15 Amazon DocumentDB replicas with minimal downtime and availability impact on applications (up to 30 seconds of downtime for your cluster, but often less time than that). For higher availability, when you create a cluster using the Amazon DocumentDB console, and you choose to create a replica in a different Availability Zone, Amazon DocumentDB creates two instances. It creates the primary instance in one Availability Zone and the replica instance in a different Availability Zone. Failover happens with no data loss, and redo log replay is not required, because the replicas and the primary instance share the same storage.
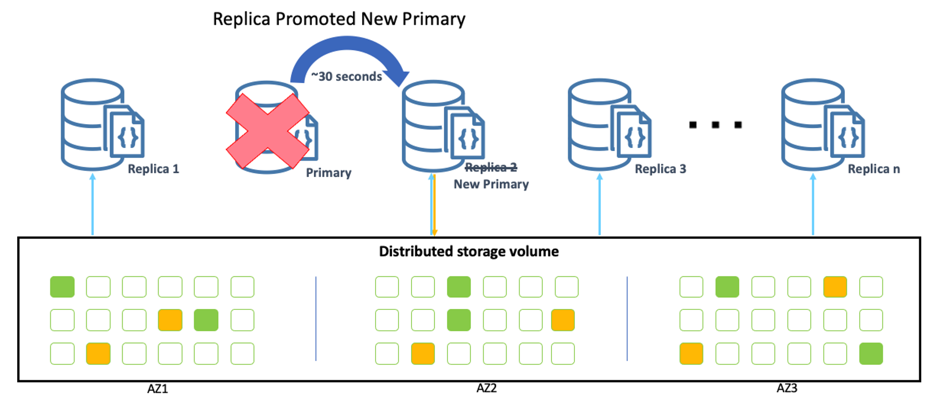
Any of 15 replicas can be promoted as the primary without data loss
The following table gives guidelines on configurations for meeting different availability goals for your Amazon DocumentDB database.
Table 1 — Typical deployment configurations
| Availability target | Total instances | Replicas | Availability Zones | Recovery time |
|---|---|---|---|---|
| 99% | 1 | 0 | 1 | 8-10 minutes |
| 99.9% | 2 | 1 | 2 | <30 seconds |
| 99.99% | 3 | 2 | 3 | <30 seconds |
| 99.99% | 4 | 3 | 3 | <30 seconds |
Failover tiers
Each Amazon DocumentDB replica instance is associated with a failover tier (0–15). When a failover occurs due to maintenance or an unlikely hardware failure, the primary instance fails over to a replica with the lowest numbered priority tier. More than one Amazon DocumentDB replica can share the same priority, resulting in promotion tiers. If two or more Amazon DocumentDB replicas share the same priority, then the replica that is largest in size is promoted to primary.
If two or more Amazon DocumentDB replicas share the same priority and size, an arbitrary replica in the same promotion tier is promoted. By setting the failover tier for a group of select replicas to 0 (the highest priority), you can ensure that a failover promotes one of the replicas in that group. Further, you can effectively prevent specific replicas from being promoted to primary if there is a failover by assigning a low-priority tier (high number) to these replicas. This is useful in cases where specific replicas are serving high reads to an application and failing over to one of them would negatively affect a critical application.
High performance
Amazon DocumentDB scales to millions of requests per second with millisecond latencies, and achieves twice the throughput of currently available MongoDB managed services. It uses a number of optimizations to achieve this.
Log structured storage
The database engine is tightly integrated with an SSD-based, virtualized storage layer purpose-built for database workloads, reducing write operations to the storage system.
Tasks related to replication, log processing, and backups are offloaded to the storage layer, reducing the load on compute instances.
Unlike traditional databases, where the compute node must periodically checkpoint data and flush dirty blocks from buffers to disk, in Amazon DocumentDB only the write-ahead log records are written to storage. This reduces unnecessary communication between the compute and storage, enabling more efficient use of network I/O.
Quorum-based reads and writes
I/O operations use distributed systems techniques such as quorums to improve performance consistency and tolerance to outliers. By default, data write operations are acknowledged as soon as they are committed by four out of six storage nodes, and individual storage nodes acknowledge the write operations as soon as the log records are persisted to disk. This behavior cannot be changed. A slow or failed storage node does not impact database performance or availability due to the use of the quorum model.
Survivable caches
In Amazon DocumentDB, the database buffer cache has been moved out of the database process. If a database restarts, the cache remains warm, and performance is not impacted due to a cold cache, as is the case with traditional databases. This approach lets you resume fully loaded operations much faster.

Cache is separate from database and survives database restart
Additionally, the buffer cache is managed independently on each instance. If a replica instance does not have the data resident in memory, the buffer cache is not polluted allowing each replica to manage their own buffer cache.
Automatic, nearly continuous backups
Amazon DocumentDB continuously backs up data to Amazon S3, which is designed for 99.999999999% durability. Amazon DocumentDB backups are automatic, incremental, and continuous, and have no impact on database performance, as the backup is offloaded to the storage layer. By default, backup and the ability to perform a point-in- time restore is enabled on all Amazon DocumentDB clusters.

Backups are offloaded to the storage layer and do not impact performance
The Amazon DocumentDB backup capability enables point-in-time recovery for your instance. This functionality allows you to restore your database to any second during your retention period (up to the last five minutes) with only a few clicks.
Scalability
Amazon DocumentDB is designed to be highly scalable. Amazon DocumentDB supports both vertical and horizontal scaling. You can scale vertically by increasing the size of your instances. You can scale horizontally by adding up to 15 read replicas, supporting millions of requests per second. The primary instance and read replicas share the same storage, and read replicas can be added in a few minutes with minimal impact on database availability. Amazon DocumentDB can automatically scale your storage up to 64 TB as your data grows and you only pay for the storage that you use.
Scaling up
Amazon DocumentDB instances are available in various sizes, starting from the db.t3.medium
instance with 2 vCPUs and 4-GiB RAM, to the db.r5.24xlarge instance with 96 vCPUs and
768-GiB RAM. The complete list of Amazon DocumentDB instance types and regional availability can be
found on the Amazon DocumentDB pricing
page
You choose an appropriate instance type based on the RAM, vCPU, and network throughput
required. You can start with a smaller instance type such as db.t3.medium or db.r5.large,
and scale up to a larger instance type as your application grows.
Compute scaling operations typically complete in a few minutes irrespective of the size of your data. Scaling does not require any copying of data because the storage and compute layers are decoupled in Amazon DocumentDB. Scaling up is useful if you want to scale your write capacity or to provision a larger read replica instance for running read-only analytics workloads.

Scale up or scale down in minutes without moving any data
Scaling out
You can scale out your cluster by adding read replicas. You can add up to 15 read replicas and scale your read capacity to millions of requests per second. The replica lag is low (usually less than 100 milliseconds) because the read replicas and the primary instance share the same storage volume. You can add replicas in minutes without any downtime or impact to database performance.

Add up to 15 replicas in minutes without downtime
Automatic scaling storage
With Amazon DocumentDB, unlike traditional databases, you do not have to provision storage space explicitly while creating the database. Amazon DocumentDB data is stored in an SSD-backed virtual volume (cluster volume) that automatically grows as the amount of data in the database increases. Every database page read operation counts as one I/O. Amazon DocumentDB issues reads against the storage layer to fetch pages not present in the buffer cache. Each page is 8KB in Amazon DocumentDB. The volume grows in increments of ten GB up to a maximum of 64 TB. This process is transparent to your application, without any impact on application availability or performance.
