This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
MLOps
MLOps is the discipline of integrating ML workloads into release management, Continuous Integration / Continuous Delivery (CI/CD), and operations.
One of the major hurdles facing government organizations is the ability to create a repeatable process for deployment that is consistent with their organizational best practices. Using ML models in software development makes it difficult to achieve versioning, quality control, reliability, reproducibility, explainability, and audibility in that process. This is due to the number of changing artifacts to be managed in addition to the software code, such as the datasets, the ML models, the parameters and hyperparameters used by such models, and the size and portability of such artifacts can be orders of magnitude higher than the software code. In addition, different teams might own different parts of the process; data engineers might be building pipelines to make data accessible, while data scientists can be researching and exploring better models. ML engineers or developers have to work on integrating the models and releasing them to production. When these groups work independently, there is a high risk of creating friction in the process and delivering suboptimal results.
AWS Cloud provides a number of different options that solve these challenges, either by building an MLOps pipeline from scratch or by using managed services.
Amazon SageMaker AI Projects
A SageMaker project is an Service Catalog provisioned product that enables creation of an end-to-end ML solution. By using a SageMaker project, teams of data scientists and developers can work together on ML business problems. SageMaker projects use MLOps templates that automate the model building and deployment pipelines using CI/CD. SageMaker-provided templates can be used to provision the initial setup required for a complete end-to-end MLOps system including model building, training, and deployment. Custom templates can also be used to customize the provisioning of resources.
Amazon SageMaker AI Pipelines
SageMaker Pipelines
AWS CodePipeline and AWS Lambda
For AWS programmers and teams that are already working with CodePipeline for deployment of other workloads, the option exists to utilize the same workflows for ML. Figure 3 below represents a reference pipeline for deployment on AWS.
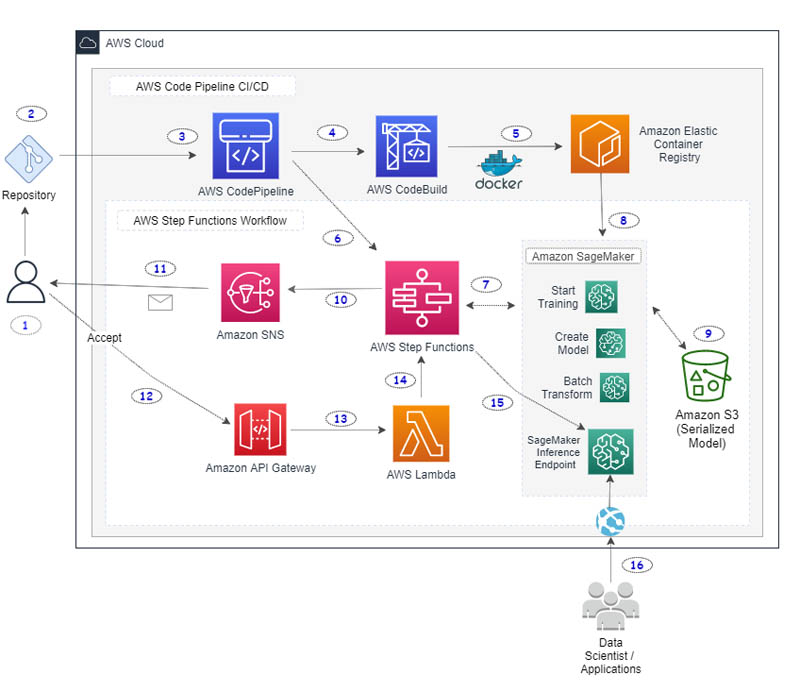
Figure 3: Reference Architecture CI/CD Pipeline for ML on AWS
See Build a CI/CD pipeline for deploying custom machine learning models using AWS
services
AWS Step Functions Data Science Software Development Kit (SDK)
The AWS Step Functions Data Science SDK is an open-source Python library that allows data
scientists to create workflows that process and publish ML models using SageMaker and Step
Functions. This can be used by teams that are already comfortable using Python and
AWS Step Functions. The SDK provides the ability to copy workflows, experiment with new options, and
then put the refined workflow in production. The SDK can also be used to create and
visualize end-to-end data science workflows that perform tasks such as data pre-processing
on AWS Glue and model training, hyperparameter tuning, and endpoint creation on Amazon SageMaker AI.
Workflows can be reused in production by exporting AWS CloudFormation
AWS MLOps Framework
Figure 4 below illustrates an AWS solution that provides an extendable framework with a standard interface for managing ML pipelines.

Figure 4: AWS MLOps Framework
The solution provides a ready-made template to upload trained models (also referred to as a bring your own model), configure the orchestration of the pipeline, and monitor the pipeline's operations.
Deploy Custom Deep Learning Models
In addition to Amazon SageMaker AI, AWS also provides the option to deploy custom code on
virtual machines using Amazon EC2
Deploy ML at the edge
Training your ML models requires powerful compute infrastructure available in the cloud. However, making inferences against these models typically requires far less computational power. In some cases, such as with edge devices, inferencing needs to occur even when there is limited or no connectivity to the cloud. Mining fields are an example of this type of use case. To make sure that an edge device can respond quickly to local events, it is critical that you can get inference results with low latency.
AWS IoT Greengrass
Performing inference locally on connected devices running AWS IoT Greengrass reduces latency and
cost. Instead of sending all device data to the cloud to perform ML inference and make a
prediction, you can run inference directly on the device. As predictions are made on these
edge devices, you can capture the results and analyze them to detect outliers. Analyzed data
can then be sent back to the cloud, where it can be reclassified and tagged to improve the
ML model. For example, you can build a predictive model in Amazon SageMaker AI for scene detection
analysis, optimize it to run on any camera, and then deploy it to send an alert when
suspicious activity occurs. Data gathered from the inference running on AWS IoT Greengrass can be sent
back to Amazon SageMaker AI, where it can be tagged and used to continuously improve the quality of the
ML models. See Machine Learning at the Edge: Using and Retraining Image Classification Models with
AWS IoT Greengrass (Part 1)
