Langkah 4: Evaluasi prediktor
Alur kerja khas dalam machine learning terdiri dari pelatihan serangkaian model atau kombinasi model pada set pelatihan dan penilaian keakuratannya pada set data penahanan. Bagian ini membahas cara membagi data historis, dan metrik mana yang digunakan untuk mengevaluasi model dalam prakiraan deret waktu. Untuk prakiraan, teknik backtesting adalah alat utama untuk menilai akurasi prakiraan.
Backtesting
Kerangka kerja backtesting dan evaluasi yang tepat adalah salah satu faktor terpenting dalam meraih kesuksesan aplikasi machine learning. Anda dapat mengandalkan backtest yang sukses dengan model Anda untuk mendapatkan keyakinan atas kekuatan prediktif masa depan model. Selain itu, Anda dapat menyesuaikan model melalui hyper-parameter optimization (HPO), mempelajari kombinasi model, dan mengaktifkan meta-learning dan AutoML.
Waktu karakteristik prakiraan deret waktu membuatnya berbeda, dalam hal metodologi backtesting dan evaluasi, dari bidang lain machine learning terapan. Biasanya dalam tugas ML, untuk menilai kesalahan prediktif dalam backtest, Anda membagi set data berdasarkan item. Misalnya, untuk validasi silang dalam tugas terkait gambar, Anda melakukan pelatihan di beberapa persentase gambar, kemudian menggunakan bagian lain untuk pengujian dan validasi. Dalam prakiraan, Anda perlu membagi terutama berdasarkan waktu (dan pada tingkat yang lebih rendah berdasarkan item) untuk memastikan bahwa Anda tidak membocorkan informasi dari set pelatihan ke set pengujian atau validasi, dan bahwa Anda mensimulasikan kasus produksi semirip mungkin.
Pembagian berdasarkan waktu harus dilakukan dengan hati-hati karena Anda tidak ingin memilih satu titik waktu, tetapi beberapa titik waktu. Jika tidak, akurasi terlalu bergantung pada tanggal mulai prakiraan, seperti yang ditetapkan oleh titik pembagian. Evaluasi prakiraan bergulir, di mana Anda melakukan serangkaian pembagian selama beberapa titik waktu dan hasil rata-rata yang dikeluarkan memberikan hasil backtest yang lebih kuat dan dapat diandalkan. Gambar berikut menggambarkan empat pembagian backtest yang berbeda.

Ilustrasi empat skenario backtesting yang berbeda dengan peningkatan ukuran set pelatihan, tetapi ukuran pengujian konstan
Pada gambar sebelumnya, semua skenario backtesting memiliki data yang tersedia selama seluruh durasi untuk dapat mengevaluasi nilai yang diperkirakan terhadap aktual.
Alasan di balik beberapa jendela backtest diperlukan adalah bahwa sebagian besar deret waktu dalam dunia nyata biasanya non-stasioner. Bisnis e-commerce dalam studi kasus berkantor pusat di Amerika Utara dan sebagian besar permintaan produknya didorong oleh puncak Q4, dengan puncak tertentu pada waktu sekitar Thanksgiving dan sebelum Natal. Dalam musim belanja Q4, variabilitas deret waktu lebih tinggi daripada waktu lain sepanjang tahun ini. Dengan memiliki beberapa jendela backtest, Anda dapat mengevaluasi model prakiraan dalam pengaturan yang lebih seimbang.
Untuk setiap skenario backtest, gambar berikut menunjukkan unsur-unsur dasar dalam terminologi Amazon Forecast. Amazon Forecast secara otomatis membagi data menjadi set data pelatihan dan pengujian. Amazon Forecast memutuskan cara membagi data input dengan menggunakan BackTestWindowOffset parameter yang ditetapkan sebagai parameter dalam create_predictor API atau menggunakan nilai defaultnya ForecastHorizon.
Pada gambar berikut, Anda melihat kasus sebelumnya yang lebih umum ketika parameter BackTestWindowOffset dan ForecastHorizon tidak sama. Parameter BackTestWindowOffset menetapkan tanggal mulai prakiraan virtual, yang ditampilkan sebagai garis vertikal putus-putus pada gambar berikut. Ini dapat digunakan untuk menjawab pertanyaan hipotetis berikut: Jika model diterapkan pada hari ini, apakah prakiraannya? ForecastHorizon menetapkan jumlah langkah waktu dari tanggal mulai prakiraan virtual ke prediksi.

Ilustrasi skenario backtest tunggal dan konfigurasinya di Amazon Forecast
Amazon Forecast dapat mengekspor nilai prakiraan dan metrik akurasi yang dihasilkan selama backtesting. Data yang diekspor dapat digunakan untuk mengevaluasi item tertentu pada kuantil dan titik waktu tertentu.
Kuantil prediksi dan metrik akurasi
Kuantil prediksi dapat memberikan batas atas dan bawah untuk prakiraan. Misalnya, menggunakan jenis prakiraan 0,1 (P10), 0,5 (P50), dan 0,9 (P90) memberikan rentang nilai yang disebut sebagai interval kepercayaan 80% di sekitar prakiraan P50. Dengan menghasilkan prediksi pada P10, P50, dan P90, Anda dapat mengharapkan nilai sebenarnya ada di antara batas tersebut 80% dari waktu.
Laporan resmi ini lebih lanjut membahas kuantil pada Langkah 5.
Amazon Forecast menggunakan metrik akurasi Weighted Quantile Loss (wQL), Root Mean Square Error (RMSE), dan Weighted Absolute Persentase Error (WAPE) untuk mengevaluasi prediktor selama backtesting.
Weighted Quantile Loss (wQL)
Metrik kesalahan Weighted Quantile Loss (wQL) mengukur akurasi prakiraan model pada kuantil yang ditentukan. Metrik ini sangat berguna ketika ada biaya yang berbeda untuk prediksi yang kurang dan prediksi berlebih. Mengatur bobot (τ) fungsi wQL secara otomatis menyertakan hukuman yang berbeda untuk prediksi yang kurang dan prediksi berlebih.
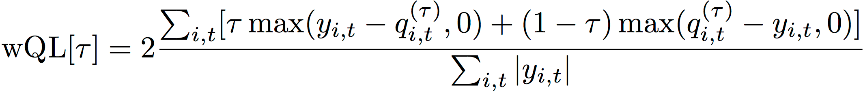
fungsi wQL
Di mana:
-
τ — Kuantil dalam set {0,01, 0,02, ..., 0,99}
-
qi,t(τ) — Kuantil τ yang diprediksi model.
-
yi,t — Nilai yang teramati di titik (i,t)
Weighted Absolute Percentage Error (WAPE)
Weighted Absolute Persentase Error (WAPE) adalah metrik yang umum digunakan untuk mengukur akurasi model. Metrik ini mengukur deviasi keseluruhan nilai yang diperkirakan dari nilai yang diamati.
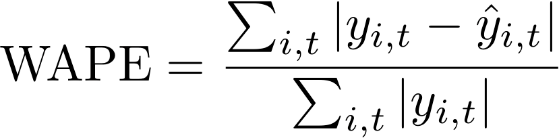
WAPE
Di mana:
-
yi,t - Nilai yang teramati di titik (i,t)
-
ŷi,t - Nilai yang diprediksi di titik (i,t)
Prakiraan menggunakan prakiraan rata-rata sebagai nilai yang diprediksi, ŷi,t.
Root Mean Square Error (RMSE)
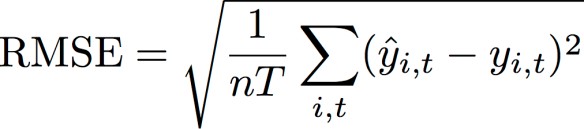
Root Mean Square Error (RMSE) adalah metrik yang umum digunakan untuk mengukur akurasi model. Seperti WAPE, metrik ini mengukur deviasi keseluruhan perkiraan dari nilai yang diamati.
Di mana:
-
yi,t - Nilai yang teramati di titik (i,t)
-
ŷi,t - Nilai yang diprediksi di titik (i,t)
-
nT - Jumlah titik data dalam set pengujian
Prakiraan menggunakan prakiraan rata-rata sebagai nilai yang diprediksi, ŷi,t. Saat menghitung metrik prediktor, nT adalah jumlah titik data dalam jendela backtest.
Masalah yang terkait dengan WAPE dan RMSE
Dalam kebanyakan kasus, prakiraan titik yang dapat dihasilkan secara internal atau dari alat prakiraan lainnya harus sesuai dengan prakiraan rata-rata atau kuantil p50. Untuk WAPE dan RMSE, Amazon Forecast menggunakan prakiraan rata-rata untuk mewakili nilai yang diprediksi (yhat).
Untuk tau = 0,5 dalam persamaan wQL[tau], kedua bobot sama, dan wQL[0,5] mengurangi hingga Weighted Absolute Percentage Error (WAPE) yang umum digunakan untuk prakiraan titik:
![Gambar persamaan wQL[0,5].](images/wql.png)
di mana yhat = q(0,5) adalah prakiraan komputasi. Faktor penskalaan 2 digunakan dalam rumus wQL untuk membatalkan faktor 0,5 guna mendapatkan ekspresi WAPE[median] yang tepat.
Perhatikan bahwa definisi WAPE di atas berbeda dari interpretasi umum untuk Mean Absolute Percentage Error (MAPE
Tidak seperti metrik weighted quantile loss untuk tau tidak sama dengan 0,5, bias yang ada pada setiap kuantil tidak dapat ditangkap dengan perhitungan seperti WAPE, di mana bobotnya sama. Kelemahan lain dari WAPE termasuk bahwa WAPE tidak simetris, melebih-lebihkan kesalahan persentase untuk jumlah kecil, dan hanya metrik untuk titik.
RMSE adalah kuadrat dari variabel kesalahan dalam WAPE dan merupakan metrik kesalahan umum dalam aplikasi ML lainnya. Metrik RMSE mendukung sebuah model, di mana kesalahan individu memiliki besar yang konsisten, karena variasi kesalahan yang besar akan meningkatkan RMSE secara berlebihan. Karena kesalahan yang dikuadratkan, beberapa nilai yang diprediksi dengan buruk dalam prakiraan yang baik dapat meningkatkan RMSE. Selain itu, karena variabel kuadrat, variabel kesalahan yang lebih kecil memiliki bobot yang lebih kecil di RMSE daripada di WAPE.
Metrik akurasi memungkinkan penilaian kuantitatif prakiraan. Khususnya untuk perbandingan skala besar (apakah metode A lebih baik daripada metode B secara keseluruhan), hal ini sangat penting. Tetapi, melengkapi ini dengan visual untuk SKU individu sering kali penting.
