Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per connettere i servizi Amazon ECS in un VPC
Utilizzando le attività di Amazon ECS in un VPC, puoi suddividere le applicazioni monolitiche in parti separate che possono essere distribuite e scalate indipendentemente in un ambiente sicuro. Questa architettura si chiama architettura orientata ai servizi (SOA) o microservizi. Tuttavia, può essere difficile assicurarsi che tutte queste parti, sia all'interno che all'esterno di un VPC, possano comunicare tra loro. Esistono diversi approcci per facilitare la comunicazione, tutti con vantaggi e svantaggi diversi.
Utilizzo di Service Connect
Consigliamo Service Connect, che fornisce la configurazione di Amazon ECS per l'individuazione dei servizi, la connettività e il monitoraggio del traffico. Con Service Connect, le applicazioni possono utilizzare nomi brevi e porte standard per connettersi ai servizi nello stesso cluster, VPCs in altri cluster, anche all'interno della stessa regione. Per ulteriori informazioni, consulta Amazon ECS Service Connect.
Quando usi Service Connect, Amazon ECS gestisce tutte le parti del service discovery: crea i nomi che possono essere scoperti, gestisce dinamicamente le voci per ogni attività all'inizio e all'interruzione delle attività, esegue un agente in ogni attività configurato per scoprire i nomi. L'applicazione può cercare i nomi utilizzando la funzionalità standard per i nomi DNS e stabilendo connessioni. Se l'applicazione lo fa già, non è necessario modificarla per utilizzare Service Connect.
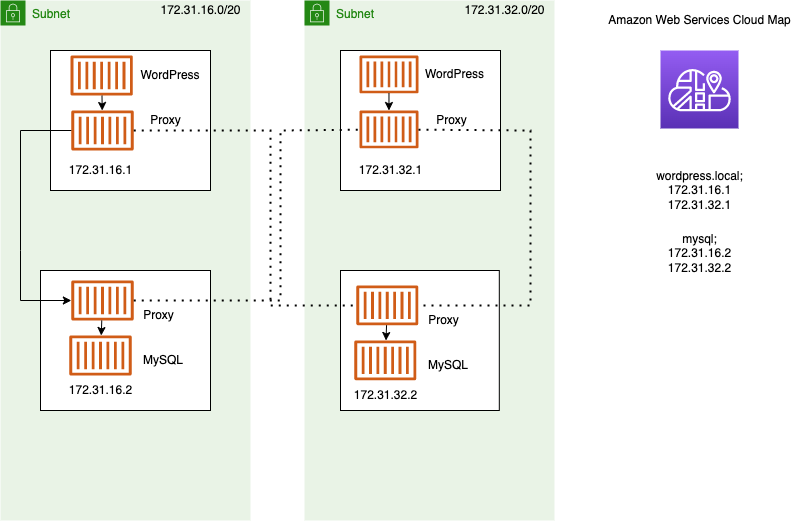
Le modifiche avvengono solo durante le distribuzioni
Fornisci la configurazione completa all'interno di ogni definizione di servizio e attività. Amazon ECS gestisce le modifiche a questa configurazione in ogni distribuzione del servizio, per garantire che tutte le attività di una distribuzione si comportino nello stesso modo. Ad esempio, un problema comune relativo al DNS as service discovery è il controllo di una migrazione. Se si modifica un nome DNS in modo che punti ai nuovi indirizzi IP sostitutivi, potrebbe essere necessario il tempo TTL massimo prima che tutti i client inizino a utilizzare il nuovo servizio. Con Service Connect, la distribuzione del client aggiorna la configurazione sostituendo le attività del client. È possibile configurare l'interruttore automatico di distribuzione e altre configurazioni di distribuzione per influire sulle modifiche di Service Connect allo stesso modo di qualsiasi altra distribuzione.
Utilizzo del rilevamento dei servizi
Un altro approccio alla service-to-service comunicazione è la comunicazione diretta tramite il service discovery. In questo approccio, puoi utilizzare l'integrazione del rilevamento dei AWS Cloud Map servizi con Amazon ECS. Utilizzando service discovery, Amazon ECS sincronizza l'elenco delle attività avviate con AWS Cloud Map, che mantiene un nome host DNS che si risolve negli indirizzi IP interni di una o più attività di quel particolare servizio. Altri servizi in Amazon VPC possono utilizzare questo nome host DNS per inviare traffico direttamente a un altro contenitore utilizzando il suo indirizzo IP interno. Per ulteriori informazioni, consulta Individuazione dei servizi.
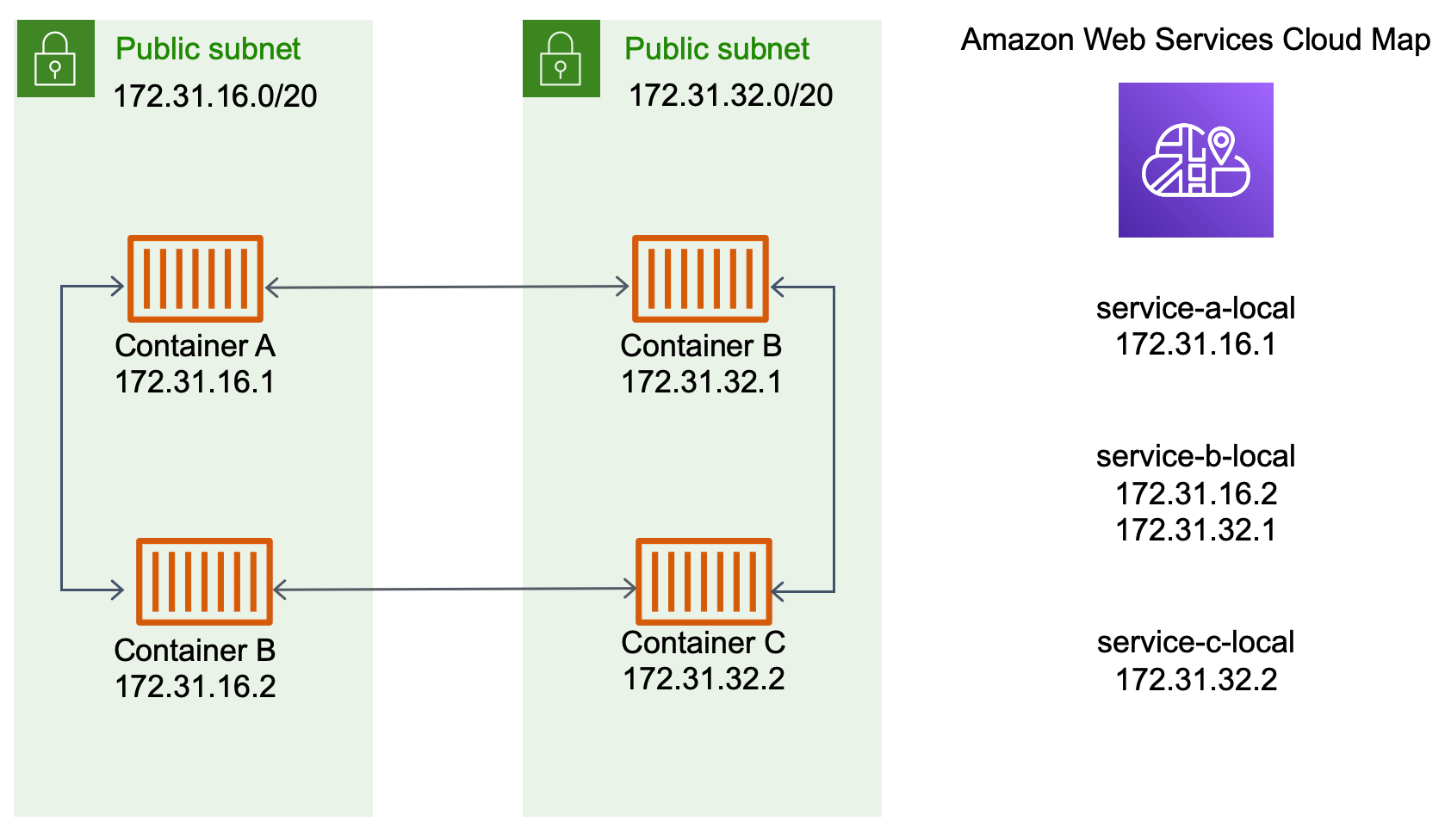
Nel diagramma precedente, sono presenti tre servizi. service-a-localha un contenitore e comunica conservice-b-local, che ha due contenitori. service-b-localdeve comunicare anche conservice-c-local, che ha un contenitore. Ogni contenitore di tutti e tre questi servizi può utilizzare i nomi DNS interni di AWS Cloud Map per trovare gli indirizzi IP interni di un contenitore del servizio a valle con cui deve comunicare.
Questo approccio alla service-to-service comunicazione offre una bassa latenza. A prima vista, è anche semplice in quanto non ci sono componenti aggiuntivi tra i contenitori. Il traffico viaggia direttamente da un container all'altro.
Questo approccio è adatto quando si utilizza la modalità awsvpc di rete, in cui ogni attività ha il proprio indirizzo IP univoco. La maggior parte dei software supporta solo l'uso di A record DNS, che si risolvono direttamente in indirizzi IP. Quando si utilizza la modalità di awsvpc rete, l'indirizzo IP per ogni operazione è un A record. Tuttavia, se utilizzi la modalità di bridge rete, è possibile che più contenitori condividano lo stesso indirizzo IP. Inoltre, le mappature dinamiche delle porte fanno sì che ai contenitori vengano assegnati in modo casuale i numeri di porta su quel singolo indirizzo IP. A questo punto, un A record non è più sufficiente per l'individuazione del servizio. È inoltre necessario utilizzare un SRV record. Questo tipo di record può tenere traccia sia degli indirizzi IP che dei numeri di porta, ma richiede la configurazione appropriata delle applicazioni. Alcune applicazioni predefinite utilizzate potrebbero non supportare SRV i record.
Un altro vantaggio della modalità di awsvpc rete è che si dispone di un gruppo di sicurezza unico per ogni servizio. È possibile configurare questo gruppo di sicurezza per consentire le connessioni in entrata solo dai servizi upstream specifici che devono comunicare con quel servizio.
Lo svantaggio principale della service-to-service comunicazione diretta tramite Service Discovery è che è necessario implementare una logica aggiuntiva per ripetere i tentativi e gestire gli errori di connessione. I record DNS hanno un periodo time-to-live (TTL) che controlla per quanto tempo vengono memorizzati nella cache. L'aggiornamento del record DNS e la scadenza della cache richiedono del tempo per consentire alle applicazioni di recuperare la versione più recente del record DNS. Pertanto, l'applicazione potrebbe finire per risolvere il record DNS in modo che punti a un altro contenitore che non è più presente. L'applicazione deve gestire i nuovi tentativi e disporre di una logica per ignorare i backend non validi.
Utilizzo di un sistema di bilanciamento del carico interno
Un altro approccio alla service-to-service comunicazione consiste nell'utilizzare un sistema di bilanciamento del carico interno. Un load balancer interno esiste interamente all'interno del tuo VPC ed è accessibile solo ai servizi all'interno del tuo VPC.
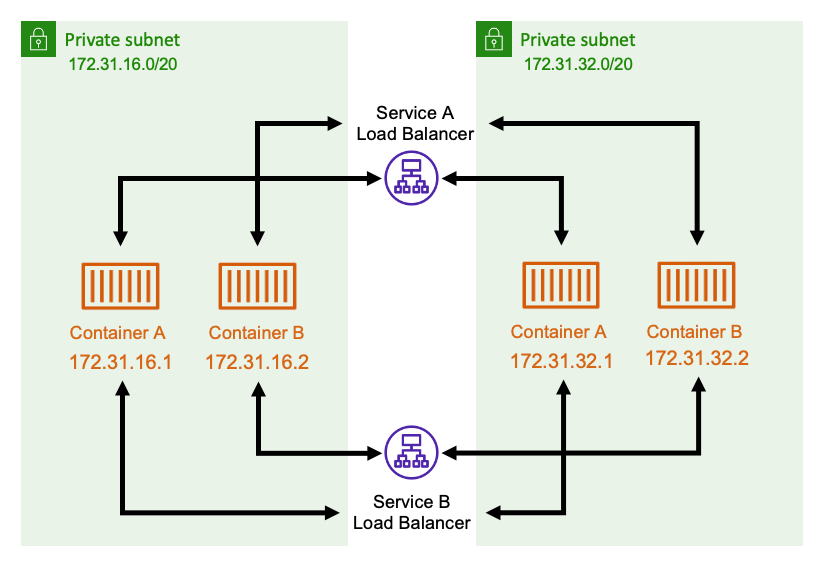
Il load balancer mantiene un'elevata disponibilità distribuendo risorse ridondanti in ogni sottorete. Quando un container from serviceA deve comunicare con un container daserviceB, apre una connessione al load balancer. Il sistema di bilanciamento del carico apre quindi una connessione a un contenitore da. service B Il load balancer funge da luogo centralizzato per la gestione di tutte le connessioni tra ciascun servizio.
Se un container si serviceB ferma, il load balancer può rimuoverlo dal pool. Il load balancer esegue inoltre controlli dello stato di salute di ogni target a valle del pool e può rimuovere automaticamente gli obiettivi danneggiati dal pool finché non tornano a funzionare di nuovo. Non è più necessario che le applicazioni siano consapevoli del numero di container a valle presenti. Si limitano ad aprire le proprie connessioni al sistema di bilanciamento del carico.
Questo approccio è vantaggioso per tutte le modalità di rete. Il load balancer può tenere traccia degli indirizzi IP delle attività quando si utilizza la modalità di awsvpc rete, nonché delle combinazioni più avanzate di indirizzi IP e porte quando si utilizza la bridge modalità di rete. Distribuisce in modo uniforme il traffico su tutte le combinazioni di indirizzi IP e porte, anche se diversi container sono effettivamente ospitati sulla stessa EC2 istanza Amazon, solo su porte diverse.
L'unico svantaggio di questo approccio è il costo. Per garantire un'elevata disponibilità, il sistema di bilanciamento del carico deve disporre di risorse in ogni zona di disponibilità. Ciò comporta costi aggiuntivi a causa del sovraccarico dovuto al pagamento del load balancer e alla quantità di traffico che attraversa il load balancer.
Tuttavia, è possibile ridurre i costi generali facendo in modo che più servizi condividano un sistema di bilanciamento del carico. Ciò è particolarmente adatto per i servizi REST che utilizzano un Application Load Balancer. È possibile creare regole di routing basate sui percorsi che indirizzano il traffico verso servizi diversi. Ad esempio, /api/user/* potrebbe indirizzare verso un contenitore che fa parte del user servizio, mentre /api/order/* potrebbe indirizzare verso il servizio associatoorder. Con questo approccio, paghi solo per un Application Load Balancer e disponi di un URL coerente per la tua API. Tuttavia, puoi suddividere il traffico verso vari microservizi sul backend.
