Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Riduzione al minimo dei tempi di inattività ElastiCache per Redis con Multi-AZ
Esistono diversi casi in cui ElastiCache Redis potrebbe dover sostituire un nodo primario, tra cui alcuni tipi di manutenzione pianificata e l'improbabile eventualità di un guasto del nodo primario o della zona di disponibilità.
Questa sostituzione comporta alcuni tempi di inattività per il cluster, ma se la funzione Multi-AZ è abilitata, il tempo di inattività viene ridotto al minimo. Il ruolo del nodo primario eseguirà automaticamente il failover su una delle repliche di lettura. Non è necessario creare ed effettuare il provisioning di un nuovo nodo primario, poiché ElastiCache gestirà il problema in modo trasparente. Questo failover e la promozione delle repliche garantiscono la possibilità di ricominciare a scrivere nel nuovo nodo primario non appena la promozione è terminata.
ElastiCache propaga anche il nome DNS (Domain Name Service) della replica promossa. Questo perché se l'applicazione scrive nell'endpoint primario, allora non è richiesta alcuna modifica dell'endpoint nell'applicazione. Tuttavia, poiché la lettura viene eseguita da singoli endpoint, occorre assicurarsi di modificare l'endpoint di lettura della replica promossa al nodo primario nel nuovo endpoint della replica.
In caso di sostituzioni dei nodi pianificati, iniziati a causa di aggiornamenti di manutenzione o aggiornamenti self-service, fare attenzione a quanto segue:
ElastiCache Per Redis Cluster, le sostituzioni pianificate dei nodi vengono completate mentre il cluster soddisfa le richieste di scrittura in entrata.
Per i cluster Redis con Modalità cluster disabilitata con funzione Multi-AZ abilitata e in esecuzione sul motore 5.0.6 o versioni successive, le sostituzioni nodi pianificate vengono completate mentre il cluster serve le richieste di scrittura in entrata.
Per i cluster Redis con Modalità cluster disabilitata con funzione Multi-AZ abilitata e in esecuzione sul motore 4.0.10 o versione precedente, è possibile che si verifichi una breve interruzione di scrittura, associata agli aggiornamenti DNS. Questa interruzione potrebbe richiedere fino a pochi secondi. Questo processo è molto più veloce rispetto a dover ricreare e rieseguire il provisioning di un nuovo primario, come accade nel caso in cui la funzione Multi-AZ non viene abilitata.
È possibile abilitare Multi-AZ utilizzando la console di ElastiCache gestione AWS CLI, l'o l'API. ElastiCache
L'abilitazione di ElastiCache Multi-AZ sul cluster Redis (nell'API e nella CLI, gruppo di replica) migliora la tolleranza agli errori. Questo vale in particolare nei casi in cui il cluster principale di lettura/scrittura del cluster diventa irraggiungibile o si guasta per qualche motivo. La funzione Multi-AZ è supportata solo su cluster Redis che hanno più di un nodo in ogni partizione.
Argomenti
Abilitazione della funzione Multi-AZ
È possibile abilitare Multi-AZ quando si crea o si modifica un cluster (API o CLI, gruppo di replica) utilizzando ElastiCache la console AWS CLI o l'API. ElastiCache
Puoi abilitare la funzione Multi-AZ solo su cluster Redis (modalità cluster disabilitata) in cui è abilitata almeno una replica di lettura. I cluster senza repliche di lettura non forniscono alta disponibilità o tolleranza ai guasti. Per informazioni sulla creazione di un cluster con replica, consulta Creazione di un gruppo di replica Redis. Per informazioni sull'aggiunta di una replica di lettura a un cluster con replica, consulta Aggiunta di una replica di lettura per i gruppi di replica Redis (modalità cluster disabilitata).
Argomenti
Abilitazione del Multi-AZ (console)
È possibile abilitare Multi-AZ utilizzando la ElastiCache console quando si crea un nuovo cluster Redis o modificando un cluster Redis esistente con la replica.
La funzione Multi-AZ è abilitata per impostazione predefinita nei cluster Redis (modalità cluster abilitata).
Importante
ElastiCache abiliterà automaticamente Multi-AZ solo se il cluster contiene almeno una replica in una zona di disponibilità diversa da quella principale in tutti gli shard.
Abilitazione di Multi-AZ durante la creazione di un cluster utilizzando la console ElastiCache
Per ulteriori informazioni su questo processo, consulta Creazione di un cluster Redis (modalità cluster disabilitata) (Console). Assicurati di disporre di una o più repliche e di abilitare la funzione Multi-AZ.
Abilitazione della funzione Multi-AZ in un cluster esistente (console)
Per ulteriori informazioni su questo processo, consulta Utilizzando il AWS Management Console nella sezione relativa alla modifica di un cluster.
Abilitazione di Multi-AZ (AWS CLI)
Il seguente esempio di codice utilizza AWS CLI per abilitare Multi-AZ per il gruppo di replica. redis12
Importante
Il gruppo di replica redis12 deve esistere già e disporre di almeno una replica di lettura.
Per Linux, macOS o Unix:
aws elasticache modify-replication-group \ --replication-group-idredis12\ --automatic-failover-enabled \ --multi-az-enabled \ --apply-immediately
Per Windows:
aws elasticache modify-replication-group ^ --replication-group-idredis12^ --automatic-failover-enabled ^ --multi-az-enabled ^ --apply-immediately
L'output JSON di questo comando dovrebbe essere simile a quanto segue:
{
"ReplicationGroup": {
"Status": "modifying",
"Description": "One shard, two nodes",
"NodeGroups": [
{
"Status": "modifying",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-001.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-002.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-002"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis12.v5r9dc.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ReplicationGroupId": "redis12",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabling",
"MultiAZ": "enabled",
"SnapshotWindow": "07:00-08:00",
"SnapshottingClusterId": "redis12-002",
"MemberClusters": [
"redis12-001",
"redis12-002"
],
"PendingModifiedValues": {}
}
}Per ulteriori informazioni, consulta questi argomenti nel Riferimento ai comandi AWS CLI :
-
modify-replication-group nel Riferimento ai comandi AWS CLI .
Abilitazione di Multi-AZ (API) ElastiCache
Il seguente esempio di codice utilizza l' ElastiCache API per abilitare Multi-AZ per il gruppo di replica. redis12
Nota
Per utilizzare questo esempio, il gruppo di replica redis12 deve esistere già e disporre di almeno una replica di lettura.
https://elasticache.us-west-2.amazonaws.com/ ?Action=ModifyReplicationGroup &ApplyImmediately=true &AutoFailover=true &MultiAZEnabled=true &ReplicationGroupId=redis12 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Per ulteriori informazioni, consulta questi argomenti nell'ElastiCache API Reference:
Risposte per scenari di errore relativi alla funzione Multi-AZ
Prima dell'introduzione di Multi-AZ, ElastiCache rilevava e sostituiva i nodi guasti di un cluster ricreando e rifornendo il nodo guasto. Abilitando la funzione Multi-AZ, un nodo primario non riuscito esegue il failover nella replica con il ritardo di replica minimo. La replica selezionata viene promossa automaticamente al nodo primario. Questa è un'operazione molto più rapida rispetto alla creazione e al provisioning di un nuovo nodo primario. Questo processo richiede in genere pochi secondi prima che sia possibile scrivere nuovamente nel cluster.
Quando Multi-AZ è abilitato, monitora ElastiCache continuamente lo stato del nodo primario. Se il nodo primario non riesce, viene eseguita una delle seguenti operazioni a seconda del tipo di errore.
Argomenti
Scenari di errore quando solo il nodo primario non riesce
Se il nodo primario non riesce, la replica di lettura con il tempo di replica minimo viene promossa al cluster primario. Viene quindi creata una replica di lettura sostitutiva e viene eseguito il provisioning nella stessa zona di disponibilità del nodo primario non riuscito.
Quando si verifica un errore solo nel nodo primario, ElastiCache Multi-AZ esegue le seguenti operazioni:
Il nodo primario non riuscito viene portato offline.
La replica di lettura con il tempo di replica minimo viene promossa al nodo primario.
Le scritture possono riprendere non appena il processo di promozione viene completato, in genere pochi secondi. Se l'applicazione sta scrivendo sull'endpoint primario, non è necessario modificare l'endpoint per operazioni di scrittura o lettura. ElastiCachepropaga il nome DNS della replica promossa.
Una replica di lettura sostitutiva viene avviata e sottoposta a provisioning.
La replica di lettura sostitutiva viene avviata nella zona di disponibilità in cui si trovava il nodo primario non riuscito, in modo da mantenere la distribuzione dei nodi.
Le repliche si sincronizzano con il nuovo nodo primario.
Dopo che la nuova replica è disponibile, tieni presente questi effetti:
-
Endpoint primario - Non è necessario apportare modifiche alla tua applicazione, poiché il nome DNS del nuovo nodo primario viene propagato all'endpoint primario.
-
Endpoint di lettura - L'endpoint di lettura viene aggiornato automaticamente per puntare ai nuovi nodi di replica.
Per informazioni sull'individuazione degli endpoint di un cluster, consulta i seguenti argomenti:
Scenari di errore quando il nodo primario e alcune repliche di lettura non riescono
Se il nodo primario e almeno una replica di lettura non riescono, la replica disponibile con il ritardo di replica minimo viene promossa al cluster primario. Nuove repliche di lettura vengono inoltre create e sottoposte a provisioning nelle stesse zone di disponibilità dei nodi non riusciti e della replica che è stata promossa al nodo primario.
Quando il nodo primario e alcune repliche di lettura falliscono, ElastiCache Multi-AZ esegue le seguenti operazioni:
Il nodo primario non riuscito e le repliche di lettura non riuscite vengono portate offline.
La replica disponibile con il tempo di replica minimo viene promossa al nodo primario.
Le scritture possono riprendere non appena il processo di promozione viene completato, in genere pochi secondi. Se l'applicazione sta scrivendo sull'endpoint primario, non è necessario modificare l'endpoint per le scritture. ElastiCache propaga il nome DNS della replica promossa.
Repliche sostitutive vengono create e sottoposte a provisioning.
Le repliche sostitutive vengono create nelle zone di disponibilità dei nodi non riusciti, in modo da mantenere la distribuzione dei nodi.
Tutti i cluster si sincronizzano con il nuovo nodo primario.
Dopo che i nuovi nodi sono disponibili, occorre apportare le seguenti modifiche all'applicazione:
-
Endpoint primario - Non apportare modifiche all'applicazione. Il nome DNS del nuovo nodo primario viene propagato all'endpoint primario.
-
Endpoint di lettura - L'endpoint di lettura viene aggiornato automaticamente per puntare ai nuovi nodi di replica.
Per informazioni sull'individuazione degli endpoint di un gruppo di replica, consulta i seguenti argomenti:
Scenari di fallimento quando l'intero cluster non riesce
In caso di errore generale, tutti i nodi vengono ricreati e sottoposti a provisioning nelle stesse zone di disponibilità dei nodi originali.
In questo scenario, tutti i dati nel cluster vengono persi a causa del guasto di ogni nodo nel cluster. Questa eventualità è rara.
In caso di guasto dell'intero cluster, ElastiCache Multi-AZ esegue le seguenti operazioni:
Il nodo primario e le repliche di lettura non riusciti vengono portati offline.
Un nodo primario sostitutivo viene creato e sottoposto a provisioning.
Repliche sostitutive vengono create e sottoposte a provisioning.
Le sostituzioni vengono create nelle zone di disponibilità dei nodi non riusciti, in modo da mantenere la distribuzione dei nodi.
Poiché l'intero cluster non è riuscito, i dati vengono persi e tutti i nuovi nodi vengono avviati come inattivi.
Poiché ciascuno dei nodi sostitutivi ha lo stesso endpoint del nodo che sta sostituendo, non occorre apportare modifiche all'endpoint nell'applicazione.
Per informazioni sull'individuazione degli endpoint di un gruppo di replica, consulta i seguenti argomenti:
Ti consigliamo di creare il nodo primario e le repliche di lettura in zone di disponibilità diverse per aumentare il livello di tolleranza ai guasti.
Test del failover automatico
Dopo aver abilitato il failover automatico, è possibile testarlo utilizzando la ElastiCache console AWS CLI, l' ElastiCache API.
Durante il test, tieni presente quanto segue:
-
È possibile utilizzare questa operazione per testare il failover automatico su un massimo di 15 shard (chiamati gruppi di nodi nell' ElastiCache API e AWS CLI) in qualsiasi periodo di 24 ore.
-
Se chiami questa operazione su partizioni in cluster diversi (chiamati gruppi di replica nell'API e in CLI), puoi eseguire le chiamate contemporaneamente.
-
In alcuni casi, puoi chiamare questa operazione più volte su partizioni diversi nello stesso gruppo di replica Redis (modalità cluster abilitata) In questi casi, la sostituzione del primo nodo deve essere completata prima di effettuare una chiamata successiva.
-
Per determinare se la sostituzione del nodo è completa, controlla gli eventi utilizzando la ElastiCache console Amazon AWS CLI, l'o l' ElastiCache API. Cerca i seguenti eventi correlati al failover automatico, elencati qui in ordine di occorrenza:
-
Messaggio del gruppo di replica:
Test Failover API called for node group <node-group-id> -
Messaggio del cluster di cache:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Messaggio del gruppo di replica:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Messaggio del cluster di cache:
Recovering cache nodes <node-id> -
Messaggio del cluster di cache:
Finished recovery for cache nodes <node-id>
Per ulteriori informazioni, consulta gli argomenti seguenti:
-
Visualizzazione di eventi ElastiCache C nella Guida per l'utente di ElastiCache
-
DescribeEvents nel documento di riferimento delle API ElastiCache
-
describe-events nel Riferimento ai comandi AWS CLI .
-
Questa API è progettata per testare il comportamento dell'applicazione in caso di ElastiCache failover. Non è progettato per essere uno strumento operativo per l'avvio di un failover per risolvere un problema con il cluster. Inoltre, in determinate condizioni, come eventi operativi su larga scala, AWS può bloccare questa API.
Argomenti
Test del failover automatico utilizzando il AWS Management Console
Utilizza la procedura seguente per testare il failover automatico con la console.
Per testare il failover automatico
-
Accedere AWS Management Console e aprire la ElastiCache console all'indirizzo https://console.aws.amazon.com/elasticache/
. -
Nel riquadro di navigazione, scegli Redis.
-
Dall'elenco di cluster Redis, scegli la casella a sinistra del cluster che desideri testare. Questo cluster deve disporre almeno di un nodo di replica di lettura.
-
Nell'area Dettagli, conferma che questo cluster è abilitato per Multi-AZ. Se il cluster non è abilitato per la funzione Multi-AZ, scegliere un cluster diverso o modificare questo cluster per abilitare la funzione Multi-AZ. Per ulteriori informazioni, consulta Utilizzando il AWS Management Console.
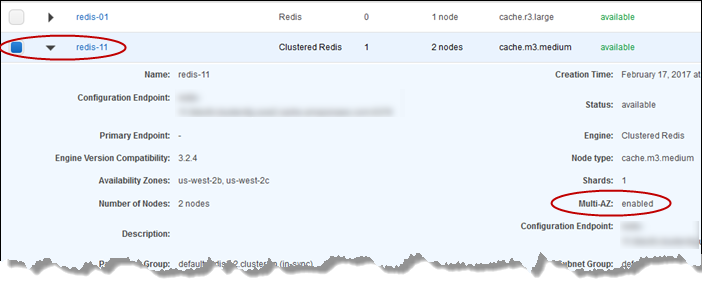
Per Redis (modalità cluster disabilitata), scegliere il nome del cluster.
Per Redis (modalità cluster abilitata), si applica quanto segue:
-
Seleziona il nome del cluster.
-
Nella pagina Shards (Partizioni), per la partizione (chiamato gruppo di nodi nell'API e in CLI) su cui desideri testare il failover, scegliere il nome della partizione.
-
-
Nella pagina dei nodi, scegli Failover Primary (Failover primario).
-
Scegli Continua per eseguire il failover nel nodo primario o Annulla per annullare l'operazione e non eseguire il failover nel nodo primario.
Durante il processo di failover, la console continua a visualizzare lo stato del nodo come disponibile. Per monitorare l'avanzamento del test di failover, scegli Eventi dal riquadro di navigazione della console. Nella scheda Eventi, cerca gli eventi che indicano che il failover è stato avviato (
Test Failover API called) e completato (Recovery completed).
Test del failover automatico utilizzando il AWS CLI
È possibile testare il failover automatico su qualsiasi cluster dotato di Multi-AZ utilizzando l' AWS CLI operazione. test-failover
Parametri
-
--replication-group-id– Obbligatorio. Il gruppo di replica (sulla console, cluster) da testare. -
--node-group-id– Obbligatorio. Il nome del gruppo di nodi sui cui testare il failover automatico. È possibile testare un massimo di 15 gruppi di nodi in un periodo continuativo di 24 ore.
L'esempio seguente lo utilizza AWS CLI per testare il failover automatico sul gruppo di nodi redis00-0003 nel cluster Redis (modalità cluster abilitata). redis00
Esempio Test del failover automatico
Per Linux, macOS o Unix:
aws elasticache test-failover \ --replication-group-idredis00\ --node-group-idredis00-0003
Per Windows:
aws elasticache test-failover ^ --replication-group-idredis00^ --node-group-idredis00-0003
L'aspetto dell'output del comando precedente è simile al seguente.
{
"ReplicationGroup": {
"Status": "available",
"Description": "1 shard, 3 nodes (1 + 2 replicas)",
"NodeGroups": [
{
"Status": "available",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2c",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-001.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-002.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-002"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-003.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-003"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis1x3.7ekv3t.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ClusterEnabled": false,
"ReplicationGroupId": "redis1x3",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabled",
"MultiAZ": "enabled",
"SnapshotWindow": "11:30-12:30",
"SnapshottingClusterId": "redis1x3-002",
"MemberClusters": [
"redis1x3-001",
"redis1x3-002",
"redis1x3-003"
],
"CacheNodeType": "cache.m3.medium",
"DataTiering": "disabled",
"PendingModifiedValues": {}
}
}Per tenere traccia dell'avanzamento del failover, utilizzate l'operazione. AWS CLI describe-events
Per ulteriori informazioni, consulta gli argomenti seguenti:
-
test-failover nel Riferimento ai comandi AWS CLI .
-
describe-events nel Riferimento ai comandi AWS CLI .
Test del failover automatico utilizzando l'API ElastiCache
È possibile testare il failover automatico su qualsiasi cluster abilitato con Multi-AZ utilizzando l'operazione ElastiCache API. TestFailover
Parametri
-
ReplicationGroupId– Obbligatorio. Il gruppo di replica (sulla console, cluster) da testare. -
NodeGroupId– Obbligatorio. Il nome del gruppo di nodi sui cui testare il failover automatico. È possibile testare un massimo di 15 gruppi di nodi in un periodo continuativo di 24 ore.
L'esempio seguente esegue il test del failover automatico sul gruppo di nodi redis00-0003 nel gruppo di replica (sulla console, cluster) redis00.
Esempio Test del failover automatico
https://elasticache.us-west-2.amazonaws.com/ ?Action=TestFailover &NodeGroupId=redis00-0003 &ReplicationGroupId=redis00 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Per tenere traccia dell'avanzamento del failover, utilizzate l'operazione ElastiCache DescribeEvents API.
Per ulteriori informazioni, consulta gli argomenti seguenti:
-
TestFailovernell'ElastiCache API Reference
-
DescribeEventsnell'ElastiCache API Reference
Limitazioni su Redis Multi-AZ
Tieni presente le seguenti limitazioni per la funzione Redis Multi-AZ:
-
La funzione Multi-AZ è supportata su Redis versione 2.8.6 e successive.
-
La funzione Redis Multi-AZ non è supportata sui tipi di nodi T1.
-
La replica Redis è asincrona. Pertanto, quando un nodo primario esegue il failover in una replica, si può verificare una piccola perdita di dati a causa del ritardo di replica.
Quando si sceglie la replica da promuovere a principale, ElastiCache per Redis sceglie la replica con il minor ritardo di replica. ovvero quella più attuale. Ciò consente di ridurre al minimo la quantità di dati persi. La replica con il ritardo di replica minimo si può trovare nella stessa zona di disponibilità del nodo primario con errore o in una zona diversa.
-
Quando promuovi manualmente una replica di lettura a nodo primario su Redis (modalità cluster disabilitata), è possibile farlo solo quando la funzione Multi-AZ e la funzione di failover automatico sono disabilitate. Per promuovere una replica di lettura a nodo primario, procedi come indicato di seguito:
-
Disabilitare la funzione Multi-AZ nel cluster.
-
Disabilitare il failover automatico nel cluster. A questo scopo, utilizza la console Redis deselezionando la casella di controllo Failover automatico per il gruppo di replica. È possibile eseguire questa operazione AWS CLI impostando la
AutomaticFailoverEnabledproprietà su quando si chiama l'operazione.falseModifyReplicationGroup -
Promuovere la replica di lettura al nodo primario.
-
Riattivare la funzione Multi-AZ.
-
-
ElastiCache per Redis Multi-AZ e append-only file (AOF) si escludono a vicenda. Se si abilita una, non si può abilitare l'altra.
-
Un guasto del nodo può essere causato dal raro evento di errore di un'intera zona di disponibilità. In questo caso, la replica che sostituisce il nodo primario in errore viene creata solo quando la zona di disponibilità viene ripristinata. Ad esempio, considerare un gruppo di replica con il nodo primario in AZ e le repliche in AZ-b e AZ-c. Se il nodo primario non riesce, la replica con il tempo di replica minimo viene promossa al cluster primario. Quindi, ElastiCache crea una nuova replica in az-A (dove si trovava il file primario guasto) solo quando Az-a è di nuovo attivo e disponibile.
-
Un riavvio di un nodo primario iniziato dal cliente non attiva il failover automatico. Altri riavvi ed guasti attivano il failover automatico.
-
Ogni volta che il nodo primario viene riavviato, i dati vengono cancellati quando ritorna online. Quando le repliche di lettura rilevano il cluster primario cancellato, cancellano la loro copia dei dati causando perdita dei dati.
-
Dopo che una replica di lettura è stata promossa, le altre repliche si sincronizzano con il nuovo nodo primario. Dopo la sincronizzazione iniziale, il contenuto delle repliche viene eliminato e vengono sincronizzati i dati dal nuovo nodo primario. Questo processo di sincronizzazione causa una breve interruzione, durante la quale le repliche non sono accessibili. Il processo di sincronizzazione causa anche un incremento di carico temporaneo sul nodo primario durante la sincronizzazione con le repliche. Questo comportamento è nativo di Redis e non è esclusivo di Multi-AZ. ElastiCache Per ulteriori informazioni su questo comportamento di Redis, consulta Replica
sul sito Web di Redis.
Importante
Per Redis versione 2.8.22 e successive, non è possibile creare repliche esterne.
Per le versioni Redis precedenti alla 2.8.22, si consiglia di non connettere una replica Redis esterna a un cluster for Redis abilitato ElastiCache per Multi-AZ. Questa configurazione non supportata può creare problemi che impediscono la corretta esecuzione del failover e del ripristino. ElastiCache Per connettere una replica Redis esterna a un ElastiCache cluster, assicurati che Multi-AZ non sia abilitato prima di effettuare la connessione.
