Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scansione di tabelle in DynamoDB
Un'operazione Scan in Amazon DynamoDB legge ogni elemento in una tabella o in un indice secondario. Per impostazione predefinita, un'operazione Scan restituisce tutti gli attributi dei dati per ogni item nella tabella o nell'indice. Puoi usare il parametro ProjectionExpression in modo che Scan restituisca solo alcuni attributi, piuttosto che tutti.
Scan restituisce sempre un set di risultati. Se non vengono trovati item corrispondenti, il set di risultati è vuoto.
Una singola richiesta Scan può recuperare un massimo di 1 MB di dati. Facoltativamente, DynamoDB può applicare un'espressione di filtro a questi dati, limitando i risultati prima che vengano restituiti all'utente.
Argomenti
Espressioni di filtro per la scansione
Se devi perfezionare ulteriormente i risultati di Scan, opzionalmente puoi fornire un'espressione filtro. Un'espressione di filtro determina quali item all'interno dei risultati di Scan devono essere restituiti. Tutti gli altri risultati vengono scartati.
Un'espressione di filtro viene applicata al termine di un'operazione Scan, ma prima che i risultati vengano restituiti. Pertanto, un'operazione Scan consuma la stessa quantità di capacità in lettura, a prescindere dal fatto che sia presente un'espressione di filtro.
Un'operazione Scan può recuperare un massimo di 1 MB di dati. Questo limite si applica prima che l'espressione di filtro venga valutata.
Con Scan, è possibile specificare qualsiasi attributo in un'espressione filtro, inclusi gli attributi di chiave di partizione e chiave di ordinamento.
La sintassi per un'espressione di filtro è identica a quella di un'espressione di condizione. Le espressioni di filtro possono utilizzare gli stessi comparatori, funzioni e operatori logici come espressione di condizione. Per ulteriori informazioni sugli operatori logici, consulta Espressioni, operatori e funzioni di condizione e di filtro in DynamoDB.
Esempio
L'esempio seguente AWS Command Line Interface (AWS CLI) analizza la Thread tabella e restituisce solo gli ultimi elementi inviati da un determinato utente.
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
Limitazione del numero di elementi nel set di risultati
L'operazione Scan consente di limitare il numero di item restituiti nel risultato. A questo scopo, imposta il parametro Limit sul numero massimo di item che devono essere restituiti dall'operazione Scan, prima di filtrare la valutazione dell'espressione.
Ad esempio, supponi di eseguire un'operazione Scan su una tabella con un valore Limit di 6 e senza un'espressione di filtro. Il risultato Scan contiene i primi sei elementi della tabella.
Supponi ora di aggiungere un'espressione di filtro a Scan. In questo caso, DynamoDB applica l'espressione di filtro ai sei elementi che sono stati restituiti, eliminando quelli che non corrispondono. Il risultato finale dell'operazione Scan contiene al massimo 6 item, a seconda del numero di quelli che sono stati filtrati.
Paginazione dei risultati
DynamoDB esegue la paginazione dei risultati delle operazioni Scan. Con la paginazione, i risultati della Scan vengono divisi in "pagine" di dati la cui dimensione è al massimo 1 MB. Un'applicazione può elaborare la prima pagina dei risultati, quindi la seconda pagina e così via.
Una singola operazione Scan restituisce solo un set di risultati che rientra nel limite di dimensione di 1 MB.
Per determinare se ci sono più risultati e recuperarli una pagina alla volta, le applicazioni devono fare quanto segue:
-
Esamina i risultati della
Scandi livello inferiore:-
Se il risultato contiene un elemento
LastEvaluatedKey, passa alla fase 2. -
Se non è presente un item
LastEvaluatedKeynel risultato non ci sono altri item da recuperare.
-
-
Costruire una nuova richiesta
Scan, con gli stessi parametri della precedente. Tuttavia, questa volta, accettare il valoreLastEvaluatedKeydella fase 1 e usarlo come parametroExclusiveStartKeynella nuova richiesta diScan. -
Eseguire la nuova richiesta di
Scan. -
Passa alla fase 1.
In altre parole, l'item LastEvaluatedKey della risposta di uno Scan deve essere usato come item ExclusiveStartKey per la successiva richiesta di Scan. Se non è presente un elemento LastEvaluatedKey nella risposta Scan, è stata recuperata la pagina finale dei risultati. L'assenza di LastEvaluatedKey è l'unico modo per sapere che hai raggiunto la fine del set di risultati.
È possibile utilizzare il AWS CLI per visualizzare questo comportamento. AWS CLI Invia Scan richieste di basso livello a DynamoDB, ripetutamente, LastEvaluatedKey fino a quando non è più presente nei risultati. Considerate l' AWS CLI esempio seguente che analizza l'intera Movies tabella ma restituisce solo i film di un genere particolare.
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
Normalmente, AWS CLI gestisce l'impaginazione automaticamente. Tuttavia, in questo esempio, il AWS CLI --page-size parametro limita il numero di elementi per pagina. Il parametro --debug consente di stampare le informazioni di livello inferiore relative alle richieste e alle risposte.
Nota
I risultati dell'impaginazione varieranno anche in base ai parametri di input che vengono passati.
-
L’utilizzo di
aws dynamodb scan --table-name Prices --max-items 1restituisce unNextToken -
L’utilizzo di
aws dynamodb scan --table-name Prices --limit 1restituisce unLastEvaluatedKey.
Inoltre, tieni presente che l'uso di --starting-token in particolare richiede il valore NextToken.
Se si esegue l'esempio, l'aspetto della prima risposta da DynamoDB sarà simile al seguente.
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
L'item LastEvaluatedKey nella risposta indica che non tutti gli elementi sono stati recuperati. AWS CLI Quindi invia un'altra Scan richiesta a DynamoDB. Questo modello di richiesta e risposta continua fino alla risposta finale.
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
L'assenza di LastEvaluatedKey indica che non ci sono più item da recuperare.
Nota
AWS SDKs Gestiscono le risposte DynamoDB di basso livello (inclusa la presenza o l'assenza di) e forniscono varie astrazioni per l'impaginazione LastEvaluatedKey dei risultati. Scan Ad esempio, l'interfaccia del documento SDK per Java fornisce il supporto java.util.Iterator per poter esaminare i risultati uno alla volta.
Per esempi di codice in vari linguaggi di programmazione, consulta la Guida alle operazioni di base di Amazon DynamoDB e la documentazione dell'SDK AWS per il linguaggio in uso.
Conteggio degli elementi nei risultati
Oltre agli elementi che corrispondono ai tuoi criteri, la risposta Scan contiene i seguenti elementi:
-
ScannedCount: il numero di elementi valutati, prima di qualsiasiScanFilterapplicato. Un valoreScannedCountelevato con pochi o nessun risultatoCountindica un'operazioneScaninefficiente. Se non hai utilizzato un filtro nella richiesta, alloraScannedCounteCountavranno lo stesso valore. -
Count: il numero di elementi che rimangono dopo aver applicato un'espressione di filtro (se presente).
Nota
Se non si utilizza un'espressione di filtro, ScannedCount e Count hanno lo stesso valore.
Se la dimensione del set di risultati di Scan è maggiore di 1 MB, ScannedCount e Count rappresentano solo un conteggio parziale degli elementi totali. Devi eseguire più operazioni Scan per recuperare tutti i risultati (consulta Paginazione dei risultati).
Ogni risposta di Scan contiene ScannedCount e Count per gli elementi che sono stati elaborati da quella particolare richiesta Scan. Per ottenere i totali generali per tutte le richieste Scan, puoi mantenere in esecuzione il conteggio per entrambi gli elementi ScannedCount e Count.
Unità di capacità utilizzate dalla scansione
È possibile effettuare la Scan di qualsiasi tabella o indice secondario. Le operazioni Scan consumano le unità di capacità di lettura come riportato di seguito:
Se si esegue Scan per un... |
DynamoDB utilizza le unità di capacità in lettura da... |
|---|---|
| Tabella | La capacità di lettura assegnata della tabella. |
| Indice secondario globale | La capacità di lettura assegnata dell'indice. |
| Indice secondario locale | La capacità di lettura assegnata della tabella di base. |
Nota
L’accesso multi-account per le operazioni di scansione degli indici secondari non è attualmente supportato dalle policy basate su risorse.
Per impostazione predefinita, un'operazione Scan non restituisce alcun dato sulla capacità di lettura che consuma. Tuttavia, puoi specificare il parametro ReturnConsumedCapacity in una richiesta di Scan per ottenere queste informazioni. Le seguenti sono le impostazioni valide per ReturnConsumedCapacity:
-
NONE: non vengono restituiti dati relativi alla capacità utilizzata. Questa è l'impostazione predefinita. -
TOTAL: la risposta include il numero aggregato di unità di capacità di lettura utilizzate. -
INDEXES: la risposta mostra il numero aggregato di unità di capacità di lettura utilizzate, insieme alla capacità utilizzata per ogni tabella e indice a cui è stato effettuato l'accesso.
DynamoDB calcola il numero di unità di capacità di lettura utilizzate in base al numero di elementi e alla dimensione di quegli elementi, non alla quantità di dati restituiti a un’applicazione. Per questo motivo, il numero di unità di capacità consumate è lo stesso sia che tu richieda tutti gli attributi (il comportamento predefinito) o solo alcuni di essi (usando un'espressione di proiezione). Il numero è lo stesso anche indipendentemente dal fatto che si utilizzi o meno un’espressione di filtro. Scan utilizza un’unità di capacità di lettura minima per eseguire un’operazione a elevata consistenza di lettura al secondo o due letture a coerenza finale al secondo per un elemento di un massimo di 4 KB. Se è necessario leggere un elemento che è più grande di 4 KB, DynamoDB necessità di unità di richiesta di lettura aggiuntive. Le tabelle vuote e le tabelle molto grandi che hanno una quantità limitata di chiavi di partizione potrebbero comportare costi aggiuntivi RCUs oltre alla quantità di dati scansionati. Ciò copre il costo di evasione della richiesta Scan anche in assenza di dati.
Consistenza di lettura per la scansione
Un'operazione Scan esegue letture consistenti finali per impostazione predefinita. Ciò significa che i risultati di Scan potrebbero non riflettere le modifiche dovute alle operazioni PutItem o UpdateItem completate di recente. Per ulteriori informazioni, consulta Coerenza di lettura di DynamoDB.
Se hai bisogno di letture fortemente consistenti, dal momento in cui inizia lo Scan, imposta il parametro ConsistentRead su true nella richiesta di Scan. Ciò garantisce che tutte le operazioni di scrittura completate prima dell'inizio dell'operazione Scan sono incluse nella risposta Scan.
L'impostazione di ConsistentRead su true può essere utile negli scenari di backup o replica delle tabelle, insieme a DynamoDB Streams. Per prima cosa, usa Scan con ConsistentRead impostato su true, per ottenere una copia coerente dei dati nella tabella. Durante l'operazione Scan, DynamoDB Streams registra qualsiasi attività di scrittura aggiuntiva che si verifica sulla tabella. Al termine dell'operazione Scan, puoi applicare l'attività di scrittura dal flusso alla tabella.
Nota
Un'operazione Scan con ConsistentRead impostato su true consuma il doppio delle unità di capacità in lettura, rispetto a lasciare ConsistentRead sul valore predefinito (false).
Scansione parallela
Per impostazione predefinita, l'operazione Scan elabora i dati in sequenza. Amazon DynamoDB restituisce i dati all'applicazione in incrementi di 1 MB e un'applicazione esegue ulteriori operazioni Scan per recuperare il successivo 1 MB di dati.
Più grande è la tabella o l'indice da sottoporre a scansione, più tempo richiederà Scan per il completamento. Inoltre, un'operazione Scan sequenziale potrebbe non essere sempre in grado di utilizzare completamente la capacità effettiva di trasmissione di lettura assegnata: anche se DynamoDB distribuisce i dati di una tabella di grandi dimensioni su più partizioni fisiche, un'operazione Scan può leggere solo una partizione alla volta. Per questo motivo, la velocità effettiva di una Scan è vincolata dalla velocità effettiva massima di una singola partizione.
Per risolvere questi problemi, l'operazione Scan può dividere in modo logico una tabella o un indice secondario in più segmenti, con più worker dell'applicazione che eseguono la scansione dei segmenti in parallelo. Ogni worker può essere un thread (in linguaggi di programmazione che supportano il multithreading) o un processo del sistema operativo. Per eseguire una scansione parallela, ogni worker emette la propria richiesta Scan con i seguenti parametri:
-
Segment: un segmento che deve essere sottoposto a scansione da un particolare worker. Ogni worker deve utilizzare un valore diverso perSegment. -
TotalSegments: il numero totale dei segmenti per la scansione parallela. Il valore deve essere identico al numero di worker che saranno utilizzati dall'applicazione.
Nel diagramma riportato di seguito viene illustrato come un'applicazione multithread esegue una Scan parallela con tre gradi di parallelismo.
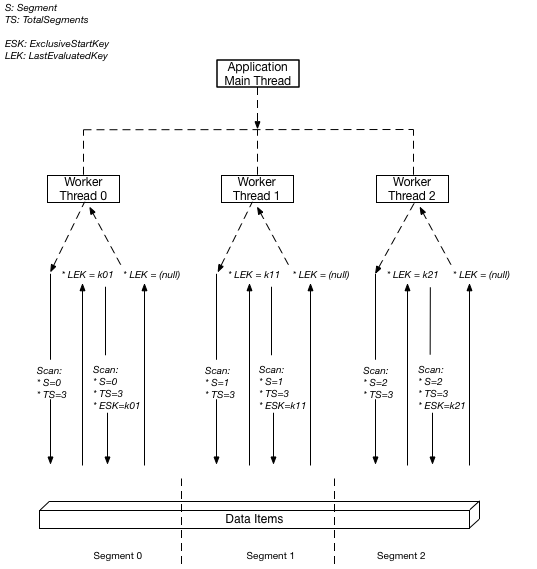
In questo diagramma, l'applicazione genera tre thread e assegna a ogni thread un numero. (Il primo numero dei segmenti è sempre 0.) Ogni thread emette una richiesta Scan, impostando Segment sul suo numero designato e TotalSegments su 3. Ogni thread esegue la scansione del segmento designato, recuperando i dati 1 MB alla volta e restituisce i dati al thread principale dell'applicazione.
DynamoDB assegna gli elementi ai segmenti applicando una funzione hash alla chiave di partizione di ciascun elemento. Per un determinato TotalSegments valore, tutti gli elementi con la stessa chiave di partizione vengono sempre assegnati allo stesso valore. Segment Ciò significa che in una tabella in cui Item 1, Item 2 e Item 3 condividono tutti pk="account#123" (ma hanno chiavi di ordinamento diverse), questi elementi verranno elaborati dallo stesso lavoratore, indipendentemente dai valori delle chiavi di ordinamento o dalla dimensione della raccolta di elementi.
Poiché l'assegnazione dei segmenti si basa esclusivamente sull'hash della chiave di partizione, i segmenti possono essere distribuiti in modo non uniforme. Alcuni segmenti potrebbero non contenere elementi, mentre altri potrebbero contenere molte chiavi di partizione con raccolte di elementi di grandi dimensioni. Di conseguenza, l'aumento del numero totale di segmenti non garantisce prestazioni di scansione più rapide, in particolare quando le chiavi di partizione non sono distribuite uniformemente nello spazio delle chiavi.
I valori per Segment e TotalSegments si applicano alle singole richieste Scan ed è possibile usare valori diversi in qualsiasi momento. Potrebbe essere necessario fare diverse prove con questi valori e il numero di worker utilizzati fino a quando l'applicazione non raggiunge le prestazioni migliori.
Nota
Una scansione parallela con un numero elevato di worker può facilmente utilizzare tutta la velocità effettiva assegnata per la tabella o l'indice da sottoporre a scansione. È preferibile evitare tali scansioni se la tabella o l'indice subiscono anche un'intensa attività di lettura o scrittura da altre applicazioni.
Per controllare la quantità di dati restituiti per ogni richiesta, utilizza il parametro Limit. Ciò consente di evitare situazioni in cui un worker utilizza tutta la velocità effettiva assegnata a spese di tutti gli altri worker.
