Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esempio di modellazione dei dati relazionali in DynamoDB
Questo esempio descrive come modellare i dati relazionali in Amazon DynamoDB. Una progettazione di tabella DynamoDB corrisponde allo schema della voce dell'ordine relazionale visualizzato in Modellazione relazionale. Segue l'Modello di progettazione elenchi di adiacenza, che è un modo comune di rappresentare le strutture di dati relazionali in DynamoDB.
Il modello di progettazione richiede che tu definisca un set di tipi di entità che solitamente sono collegati a varie tabelle nello schema relazionale. Le voci di entità vengono aggiunte alla tabella utilizzando una chiave primaria composta (partizione e ordinamento). La chiave di partizione di queste voci di entità è l'attributo che identifica in modo univoco la voce e al quale ci si riferisce solitamente come PK in tutte le voci. L'attributo di chiave di ordinamento contiene un valore di attributo che puoi utilizzare per un indice invertito o un indice secondario globale. Solitamente viene chiamato SK.
Definisci le seguenti entità che supportano lo schema della voce dell'ordine relazionale:
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK: CountryId, SK: Nome del Paese
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
Dipartimento Risorse Umane - PK: DepartmentID, SK: DepartmentName
-
Cliente OE - PK: CustomerID, SK: ID AccountRep
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
Dopo aver aggiunto queste voci di entità alla tabella, puoi definire le relazioni tra loro aggiungendo voci edge alle partizioni della voce di entità. La tabella seguente dimostra questa fase.
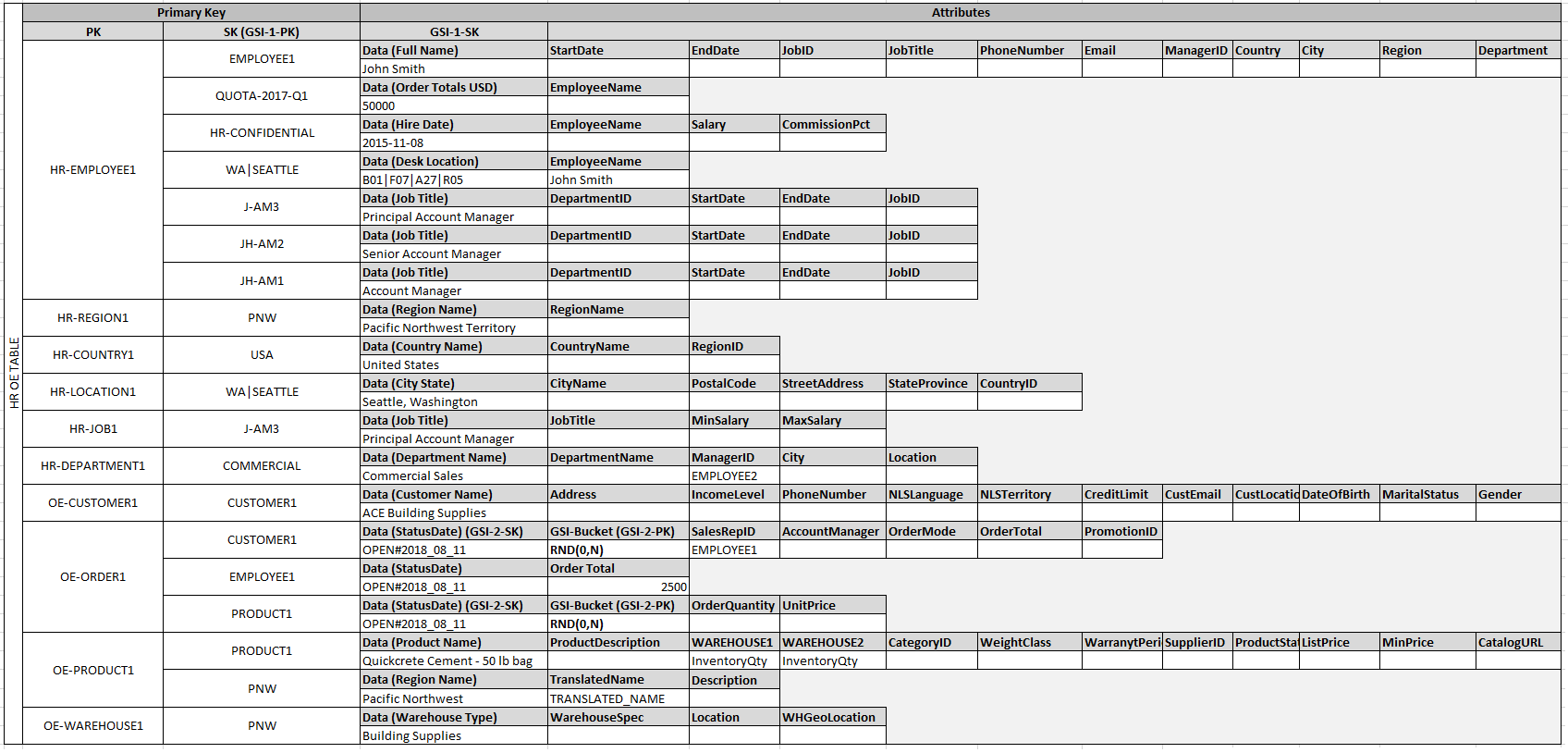
In questo esempio, le partizioni Employee, Order e Product
Entity sulla tabella hanno voci edge addizionali che contengono puntatori ad altre voci di entità sulla tabella. Successivamente, definisci alcuni indici secondari globali (GSIs) per supportare tutti i modelli di accesso definiti in precedenza. Le voci di entità non utilizzano tutte lo stesso tipo di valore per la chiave primaria o l'attributo della chiave di ordinamento. Ciò che è necessario è avere la chiave primaria e gli attributi della chiave di ordinamento presenti per essere inseriti nella tabella.
Il fatto che alcune di queste entità utilizzino nomi propri e altre entità IDs come valori delle chiavi di ordinamento consente allo stesso indice secondario globale di supportare più tipi di query. Questa tecnica si chiama overload di GSI. In effetti elimina il limite di default di 20 indici secondari globali per le tabelle che contengono più tipi di elementi. Questo viene mostrato nel seguente diagramma come GSI 1.
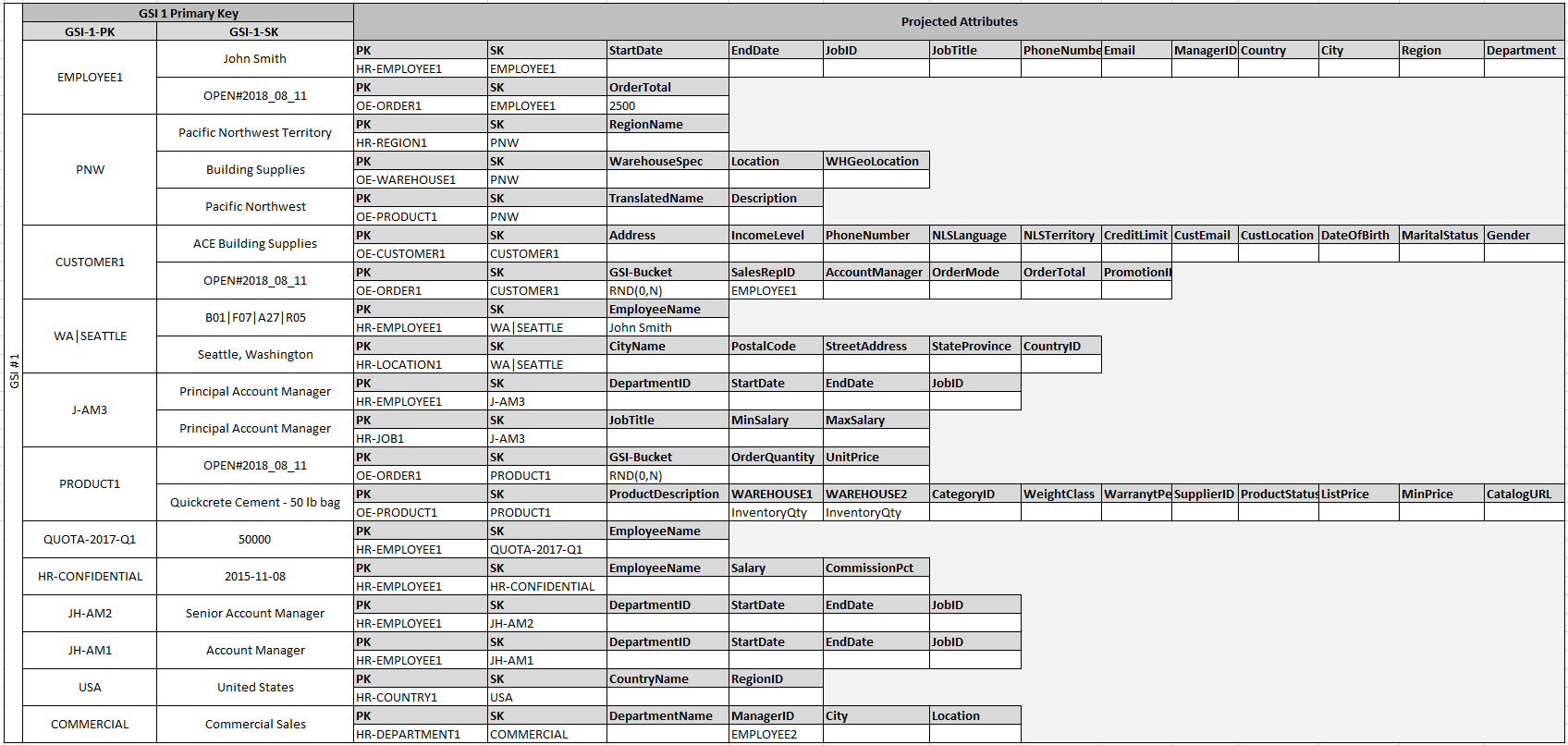
GSI 2 è progettato per supportare un modello di accesso all'applicazione abbastanza comune, che corrisponde all'inserimento di tutte le voci che hanno un certo stato sulla tabella. Per una tabella grande con una distribuzione non uniforme di voci negli stati disponibili, questo modello di accesso può risultare in un tasto di scelta rapida, a meno che le voci siano distribuite su più di una partizione logica sulla quale si può eseguire una query in parallelo. Il modello di progettazione si chiama write sharding.
Per ottenere ciò per GSI 2, l'applicazione aggiunge l'attributo della chiave primaria a ogni voce di ordine. Lo popola con un numero casuale in un intervallo 0N, dove N può essere calcolato generale utilizzando la formula riportata di seguito (a meno che ci sia una ragione specifica per non farlo).
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Ad esempio, presumi di aspettarti quanto segue:
-
Fino a due milioni di ordini saranno presenti nel sistema, aumentando fino a tre milioni in cinque anni.
-
Fino al 20 per cento di questi ordini sarà in uno stato OPEN in qualsiasi momento.
-
Il record di ordine medio è di circa 100 byte, con tre
OrderItemrecord nella partizione degli ordini di circa 50 byte ciascuno, per una dimensione media dell'entità dell'ordine di 250 byte.
Per quella tabella, il calcolo del fattore N sembrerebbe a quanto segue.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
In questo caso, devi distribuire tutti gli ordini in circa 13 partizioni logiche su GSI 2 per assicurare che una lettura di tutte le voci Order con uno stato OPEN non provochi una partizione hot sul livello di storage fisico. È buona norma aumentare questo numero per permettere anomalie nel set di dati. Quindi un modello che utilizza N = 15 probabilmente va bene. Come indicato prima, ciò si ottiene aggiungendo il valore casuale 0-N all'attributo GSI 2 PK di ogni record Order e OrderItem inserito nella tabella.
Questa suddivisione presume che il modello di accesso che richiede la raccolta di tutte le fatture OPEN accada molto raramente permettendoti di utilizzare la capacità di ottimizzazione per soddisfare la richiesta. Puoi eseguire una query sull'indice secondario globale seguente utilizzando una condizione di chiave di ordinamento per State e Date Range per produrre un sottoinsieme di tutti gli Orders in un determinato stato quando necessario.

In questo esempio, le voci sono distribuite casualmente nelle 15 partizioni logiche. Questa struttura funziona perché il modello di accesso richiede un ampio numero di voci da recuperare. Quindi è improbabile che qualsiasi dei 15 thread daranno set di risultati vuoti che potrebbero rappresentare potenzialmente una capacità sprecata. Una query utilizza sempre una unità di capacità di lettura (RCU) o una unità di capacità di scrittura (WCU) anche quando non ci sono risultati e nessun dato viene scritto.
Se il modello di accesso richiede una query ad alta velocità in questo indice secondario globale che produce un set di risultati sparse, è probabilmente meglio utilizzare un algoritmo hash per distribuire le voci piuttosto che un modello casuale. In questo caso, è possibile selezionare un attributo conosciuto quando viene eseguita la query al runtime ed eseguire l'hash di quell'attributo in uno spazio di chiave 0-14 quando vengono inseriti gli elementi. Possono poi essere letti in maniera efficace dall'indice secondario globale.
Infine, puoi rivedere i modelli di accesso definiti in precedenza. Di seguito è riportato l'elenco dei modelli di accesso e delle condizioni di query che utilizzerai con la nuova versione DynamoDB dell'applicazione per adattarli.
| S. No. | Modelli di accesso | Condizioni di query |
|---|---|---|
|
1 |
Ricerca dei dettagli dei dipendenti tramite ID dipendente |
Chiave primaria sulla tabella, ID="HR-EMPLOYEE" |
|
2 |
Esecuzione di query sui dettagli dei dipendenti tramite Nome dipendente |
Utilizzare GSI-1, PK="Employee Name" |
|
3 |
Ottenimento dei soli dettagli del lavoro corrente di un dipendente |
Chiave primaria sulla tabella, PK=HR-EMPLOYEE-1, SK inizia con "JH" |
|
4 |
Ottenimento di ordini per un cliente per un intervallo di date |
Usa GSI-1, PK=, SK="STATUS-DATE»CUSTOMER1, per ciascuno StatusCode |
|
5 |
Mostra tutti gli ordini in stato OPEN per un intervallo di date per tutti i clienti |
Utilizzare GSI-2, PK=query in parallelo per l'intervallo [0..N], SK tra OPEN-Date1 e OPEN-Date2 |
|
6 |
Tutti i dipendenti assunti di recente |
Utilizzare GSI-1, PK="HR-CONFIDENTIAL', SK > date1 |
|
7 |
Trova tutti i dipendenti in un magazzino specifico |
Usa GSI-1, PK= WAREHOUSE1 |
|
8 |
Ottenimento di tutti gli Orderitems per un prodotto, inclusi gli inventari della posizione del magazzino |
Usa GSI-1, PK= PRODUCT1 |
|
9 |
Ottenimento dei clienti per rappresentante account |
Utilizzare GSI-1, PK=ACCOUNT-REP |
|
10 |
Ottenimento di ordini per rappresentante account e data |
Usa GSI-1, PK=ACCOUNT-REP, SK="STATUS-DATE», per ogni StatusCode |
|
11 |
Ottenimento di tutti i dipendenti con una mansione specifica |
Utilizza GSI-1, PK=JOBTITLE |
|
12 |
Ottenimento dell'inventario per prodotto e magazzino |
Chiave primaria sulla tabella, PK=OE-PRODUCT1, SK= PRODUCT1 |
|
13 |
Ottenimento dell'inventario totale dei prodotti |
Chiave primaria sulla tabella, PK=OE-, SK= PRODUCT1 PRODUCT1 |
|
14 |
Ottenimento dei rappresentanti dell'account classificati in base al totale degli ordini e al periodo di vendita |
Usa GSI-1, PK=YYYY-Q1, =False scanIndexForward |
