Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per eseguire query e scansioni dei dati in DynamoDB
In questa sezione vengono illustrate alcune best practice per l'utilizzo delle operazioni Query e Scan in Amazon DynamoDB.
Considerazioni sulle prestazioni per le scansioni
In generale, le operazioni Scan sono meno efficienti rispetto ad altre operazioni in DynamoDB. Un'operazione Scan esegue sempre la scansione dell'intera tabella o dell'indice secondario. Quindi filtra i valori per fornire il risultato desiderato, aggiungendo essenzialmente il passaggio aggiuntivo di rimozione dei dati dal set di risultati.
Se possibile, è preferibile evitare di utilizzare un'operazione Scan su una tabella o un indice di grandi dimensioni con un filtro che rimuove molti risultati. Inoltre, man mano che una tabella o un indice cresce, l'operazione Scan rallenta. L'operazione Scan esamina ogni elemento per i valori richiesti e può utilizzare la velocità effettiva assegnata per una tabella o un indice di grandi dimensioni in un'unica operazione. Per tempi di risposta più rapidi, progettare tabelle e indici in modo che le applicazioni possano utilizzare Queryinvece di Scan. (Per le tabelle, puoi anche prendere in considerazione l'utilizzo di GetItem and BatchGetItem APIs.)
In alternativa, puoi progettare l'applicazione in modo da utilizzare operazioni Scan e ridurre al minimo l'impatto sulla percentuale di frequenza delle richieste. Ciò può includere la modellazione quando potrebbe essere più efficiente utilizzare un indice secondario globale anziché un'operazione Scan. Ulteriori informazioni su questo processo sono disponibili nel seguente video.
Come evitare picchi improvvisi nell'attività di lettura
Quando si crea una tabella, si impostano i requisiti di unità di capacità di lettura e scrittura. Per le letture, le unità di capacità sono espresse come il numero di richieste di lettura dati fortemente coerenti da 4 KB al secondo. Per letture a consistenza finale, un'unità di capacità di lettura è due richieste di lettura da 4 KB al secondo. Un'operazione Scan esegue letture a consistenza finale per impostazione predefinita e può restituire fino a 1 MB (una pagina) di dati. Pertanto, una singola richiesta Scan può consumare (1 MB di dimensione della pagina/4 KB dimensione elemento)/2 (letture a consistenza finale) = 128 operazioni di lettura. Se invece si richiedono letture fortemente consistenti, il metodo Scan consumerebbe il doppio della velocità effettiva assegnata, ovvero 256 operazioni di lettura.
Questo rappresenta un picco improvviso di utilizzo rispetto alla capacità di lettura configurata per la tabella. Questo utilizzo di unità di capacità da parte di una scansione impedisce ad altre richieste potenzialmente più importanti per la stessa tabella di utilizzare le unità di capacità disponibili. Di conseguenza, è probabile che si ottenga una eccezione ProvisionedThroughputExceeded per tali richieste.
Il problema non è solo l'improvviso aumento delle unità di capacità utilizzate da Scan. È inoltre probabile che la scansione utilizzi tutte le unità di capacità dalla stessa partizione, poiché le richieste della scansione leggono gli elementi che si trovano uno accanto all'altro nella partizione. Ciò significa che la richiesta considera la stessa partizione, causando l'utilizzo di tutte le unità di capacità e la limitazione di altre richieste a tale partizione. Se la richiesta di lettura dei dati è distribuita su più partizioni, l'operazione non riduce una partizione specifica.
Il diagramma seguente illustra l'impatto di un improvviso picco di utilizzo delle unità di capacità da parte delle operazioni Query e Scan e il suo impatto sulle altre richieste sulla stessa tabella.
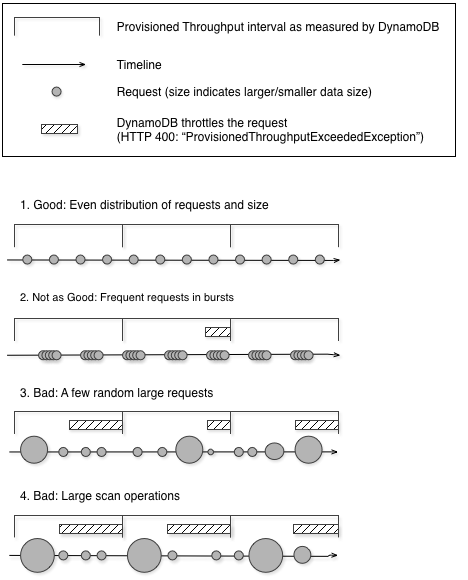
Come illustrato di seguito, il picco di utilizzo può influire sulla velocità effettiva assegnata della tabella in diversi modi:
-
Buono: distribuzione uniforme delle richieste e delle dimensioni
-
Non tanto buono: richieste frequenti a raffica
-
Cattivo: alcune richieste casuali di grandi dimensioni
-
Cattivo: operazioni di scansione di grandi dimensioni
Invece di usare un'operazione Scan di grandi dimensioni, è possibile utilizzare le seguenti tecniche per ridurre al minimo l'impatto di una scansione sulla velocità effettiva assegnata di una tabella.
-
Riduzione delle dimensioni delle pagine
Poiché un'operazione di scansione legge un'intera pagina (per impostazione predefinita, 1 MB), è possibile ridurre l'impatto dell'operazione di scansione impostando una dimensione di pagina più piccola. L'operazione
Scanfornisce un parametro Limit che può essere utilizzato per impostare le dimensioni della pagina per la richiesta. Ogni richiestaQueryoScanche ha una dimensione di pagina più piccola utilizza meno operazioni di lettura e crea una "pausa" tra ogni richiesta. Si supponga, ad esempio, che ogni elemento sia di 4 KB e di impostare la dimensione della pagina su 40 elementi. Una richiestaQueryutilizzerebbe quindi solo 20 operazioni di lettura a consistenza finale o 40 operazioni di lettura fortemente consistenti. Un numero maggiore di operazioniQueryoScanpiù piccole permetterebbe alle altre richieste critiche di avere successo senza limitazioni. -
Isolamento delle operazioni di scansione
DynamoDB è progettato per una facile scalabilità. Di conseguenza, un'applicazione può creare tabelle per scopi distinti, possibilmente anche duplicando il contenuto su più tabelle. Si desidera eseguire scansioni su una tabella che non utilizza traffico "mission-critical". Alcune applicazioni gestiscono questo carico ruotando il traffico ogni ora tra due tabelle, una per il traffico critico e una per la contabilità. Altre applicazioni possono farlo eseguendo ogni scrittura su due tabelle: una tabella "mission-critical" e una tabella "shadow".
Configurare l'applicazione in modo da riprovare qualsiasi richiesta che riceve un codice di risposta che indica che è stato superata la velocità effettiva assegnata. In alternativa, aumentare la velocità effettiva assegnata per la tabella utilizzando l'operazione UpdateTable. Se nel carico di lavoro sono presenti picchi temporanei che causano il superamento della velocità effettiva, occasionalmente, oltre il livello assegnato, riprovare la richiesta con backoff esponenziale. Per ulteriori informazioni sull'implementazione del backoff esponenziale, consulta Ripetizione dei tentativi in caso di errore e backoff esponenziale.
Vantaggi delle scansioni parallele
Molte applicazioni possono trarre vantaggio dall'utilizzo di operazioni Scan anziché delle scansioni sequenziali. Ad esempio, un'applicazione che elabora una tabella di dati cronologici di grosse dimensioni può eseguire una scansione parallela molto più velocemente di una scansione sequenziale. Più thread di lavoro in un processo "sweeper" in background possono eseguire la scansione di una tabella con priorità bassa senza influire sul traffico di produzione. In ciascuno di questi esempi, viene utilizzata una Scanparallela in modo tale da non privare altre applicazioni delle risorse di velocità effettiva assegnata.
Sebbene le scansioni parallele possano essere utili, possono porre una forte domanda sulla velocità effettiva assegnata. Con una scansione parallela, l'applicazione dispone di più worker che eseguono tutti simultaneamente le operazioni Scan. In questo modo, possono consumare rapidamente tutta la capacità di lettura assegnata della tabella. In tal caso, le applicazioni che devono poter accedere alla tabella potrebbero essere limitate.
Una scansione parallela può essere la scelta giusta se sono soddisfatte le seguenti condizioni:
La dimensione della tabella è pari o superiore a 20 GB.
La velocità effettiva di lettura assegnata della tabella non viene utilizzata completamente.
Le operazioni
Scansequenziali sono troppo lente.
Scelta TotalSegments
La migliore impostazione per TotalSegments dipende dai dati specifici, dalle impostazioni della velocità effettiva assegnata della tabella e dai requisiti di prestazioni. Per trovare la migliore impostazione potrebbe essere necessario sperimentare un po'. Si consiglia di iniziare con un rapporto semplice, ad esempio un segmento per 2 GB di dati. Ad esempio, per una tabella da 30 GB, è possibile impostare TotalSegments su 15 (30 GB/2 GB). L'applicazione utilizzerebbe quindi 15 worker, con ogni worker che esegue la scansione di un segmento diverso.
È possibile anche selezionare un valore per TotalSegments basato sulle risorse client. È possibile impostare TotalSegments su qualsiasi numero compreso tra 1 e 1.000.000 e DynamoDB consentirà la scansione di quel numero di segmenti. Ad esempio, se il client limita il numero di thread che possono essere eseguiti contemporaneamente, è possibile aumentare gradualmente TotalSegments fino a ottenere le migliori prestazioni Scan con l'applicazione.
Monitorare le scansioni parallele per ottimizzare l'utilizzo della velocità effettiva assegnata, assicurandosi al contempo che le altre applicazioni non siano private delle risorse. Aumentare il valore per TotalSegments se non si consuma tutta la velocità effettiva assegnata, ma si verifica comunque una limitazione nelle richieste Scan. Riduci il valore per TotalSegments se le richieste Scan consumano una velocità effettiva assegnata superiore a quella che desideri utilizzare.
