Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un data lake SDK Amazon Chime
Il data lake di analisi delle chiamate SDK di Amazon Chime ti consente di trasmettere informazioni dettagliate basate sull'apprendimento automatico e tutti i metadati da Amazon Kinesis Data Stream al tuo bucket Amazon S3. Ad esempio, utilizzando il data lake per accedere alle registrazioni. URLs Per creare il data lake, distribuisci un set di AWS CloudFormation modelli dalla console Amazon Chime SDK o utilizzando programmaticamente il. AWS CLI Il data lake ti consente di interrogare i metadati delle chiamate e i dati di analisi vocale facendo riferimento alle tabelle di dati AWS Glue in Amazon Athena.
Argomenti
Prerequisiti
È necessario disporre dei seguenti elementi per creare un lake Amazon Chime SDK:
-
Un flusso di dati Amazon Kinesis. Per ulteriori informazioni, consulta Creating a Stream tramite la Console di gestione AWS nella Amazon Kinesis Streams Developer Guide.
-
Un bucket S3. Per ulteriori informazioni, consulta la sezione Crea il tuo primo bucket Amazon S3 nella Amazon S3 User Guide.
Terminologia e concetti relativi al data lake
Utilizza i seguenti termini e concetti per comprendere come funziona il data lake.
- Amazon Kinesis Data Firehose
-
Un servizio di estrazione, trasformazione e caricamento (ETL) che acquisisce, trasforma e fornisce dati in streaming in modo affidabile a data lake, data store e servizi di analisi. Per ulteriori informazioni, consulta What Is Amazon Kinesis Data Firehose?
- Amazon Athena
-
Amazon Athena è un servizio di query interattivo che consente di analizzare i dati in Amazon S3 utilizzando SQL standard. Athena è serverless, quindi non hai alcuna infrastruttura da gestire e paghi solo per le query che esegui. Per usare Athena, punta ai tuoi dati in Amazon S3, definisci lo schema e usa query SQL standard. Puoi anche utilizzare i gruppi di lavoro per raggruppare gli utenti e controllare le risorse a cui hanno accesso durante l'esecuzione delle query. I gruppi di lavoro consentono di gestire la concorrenza delle query e di assegnare priorità all'esecuzione delle query tra diversi gruppi di utenti e carichi di lavoro.
- Catalogo dati Glue
-
In Amazon Athena, le tabelle e i database contengono i metadati che descrivono in dettaglio uno schema per i dati di origine sottostanti. Per ogni set di dati, deve esistere una tabella in Athena. I metadati nella tabella indicano ad Athena la posizione del tuo bucket Amazon S3. Inoltre, specifica la struttura dei dati, come i nomi delle colonne, i tipi di dati e il nome della tabella. I database contengono solo i metadati e le informazioni sullo schema di un set di dati.
Creazione di più data lake
È possibile creare più data lake fornendo un nome di database Glue univoco per specificare dove archiviare le informazioni sulle chiamate. Per un determinato AWS account, possono esserci diverse configurazioni di analisi delle chiamate, ognuna con un data lake corrispondente. Ciò significa che la separazione dei dati può essere applicata per determinati casi d'uso, come la personalizzazione della politica di conservazione e della politica di accesso sulla modalità di archiviazione dei dati. Possono essere applicate diverse politiche di sicurezza per l'accesso a informazioni dettagliate, registrazioni e metadati.
Disponibilità regionale del data lake
Il data lake Amazon Chime SDK è disponibile nelle seguenti regioni.
Regione |
Tavolo Glue |
QuickSight |
|---|---|---|
us-east-1 |
Disponibilità |
Disponibilità |
us-west-2 |
Disponibilità |
Disponibilità |
eu-central-1 |
Disponibilità |
Disponibilità |
Architettura del data lake
Il diagramma seguente mostra l'architettura del data lake. I numeri nel disegno corrispondono al testo numerato riportato di seguito.
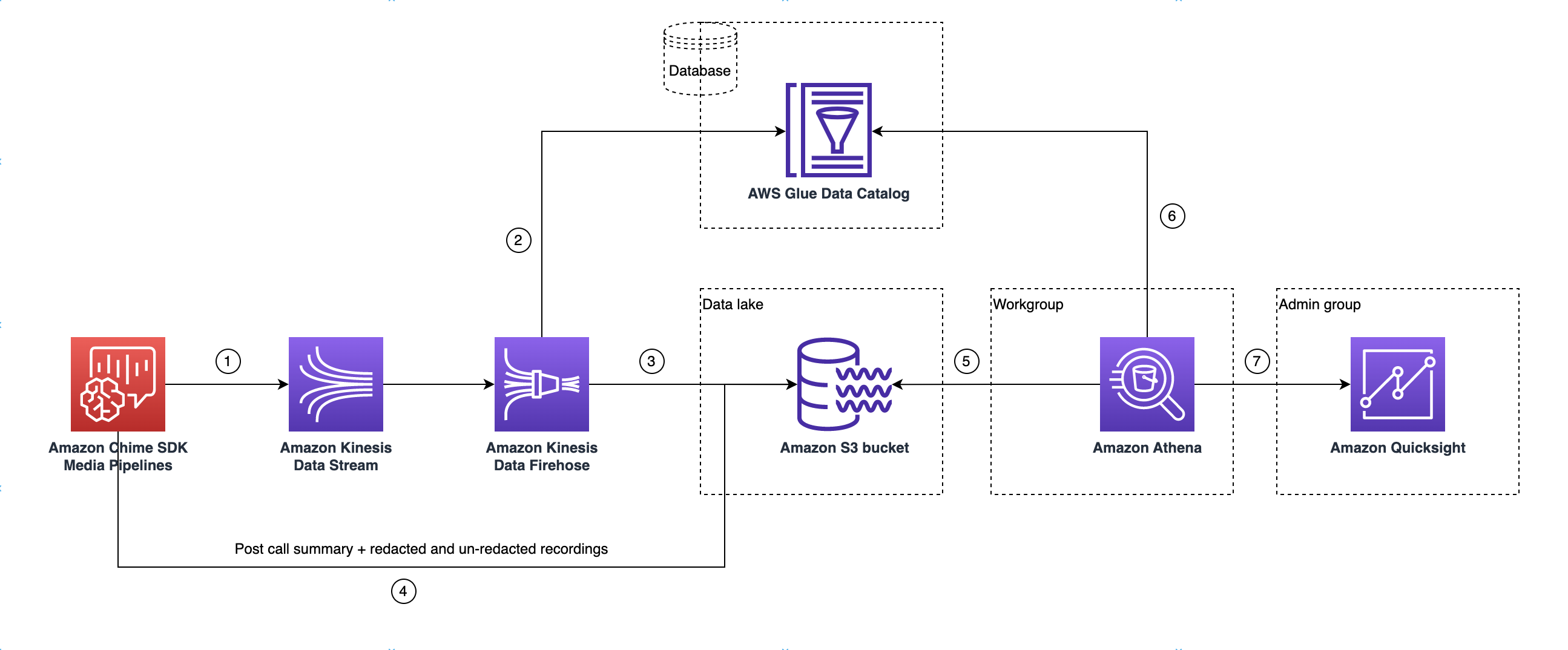
Nel diagramma, dopo aver utilizzato la AWS console per distribuire il CloudFormation modello dal flusso di lavoro di configurazione della pipeline di Media Insights, i seguenti dati fluiscono verso il bucket Amazon S3:
-
L'analisi delle chiamate dell'SDK Amazon Chime inizierà a trasmettere dati in tempo reale al Kinesis Data Stream del cliente.
-
Amazon Kinesis Firehose memorizza nel buffer questi dati in tempo reale fino a quando non accumulano 128 MB o trascorsi 60 secondi, a seconda dell'evento che si verifica per primo. Firehose utilizza quindi il file contenuto
amazon_chime_sdk_call_analytics_firehose_schemanel Glue Data Catalog per comprimere i dati e trasforma i record JSON in un file parquet. -
Il file parquet si trova nel tuo bucket Amazon S3, in un formato partizionato.
-
Oltre ai dati in tempo reale, al tuo Amazon S3 Bucket vengono inviati anche i file.wav di riepilogo di Amazon Transcribe Call Analytics post-chiamata (redatti e non redatti, se specificato nella configurazione) e i file.wav di registrazione delle chiamate.
-
Puoi utilizzare Amazon Athena e SQL standard per interrogare i dati nel bucket Amazon S3.
-
Il CloudFormation modello crea anche un Glue Data Catalog per interrogare questi dati di riepilogo post-chiamata tramite Athena.
-
Tutti i dati sul bucket Amazon S3 possono essere visualizzati anche utilizzando. QuickSight QuickSight crea una connessione con un bucket Amazon S3 utilizzando Amazon Athena.
La tabella Amazon Athena utilizza le seguenti funzionalità per ottimizzare le prestazioni delle query:
- Partizionamento dei dati
-
Il partizionamento divide la tabella in parti e mantiene insieme i dati correlati in base ai valori delle colonne come data, paese e regione. Le partizioni agiscono come colonne virtuali. In questo caso, il CloudFormation modello definisce le partizioni al momento della creazione della tabella, il che aiuta a ridurre la quantità di dati scansionati per query e migliora le prestazioni. È inoltre possibile filtrare per partizione per limitare la quantità di dati analizzati da una query. Per ulteriori informazioni, consulta la sezione Partizionamento dei dati in Athena nella Amazon Athena User Guide.
Questo esempio mostra la struttura di partizionamento con una data del 1° gennaio 2023:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
dove
DETAIL_TYPEè uno dei seguenti:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- Ottimizza la generazione di archivi dati colonnari
-
Apache Parquet utilizza la compressione a colonne, la compressione in base al tipo di dati e il pushdown dei predicati per archiviare i dati. Rapporti di compressione migliori o saltare blocchi di dati significa leggere meno byte dal tuo bucket Amazon S3. Ciò porta a migliori prestazioni di query e a costi ridotti. Per questa ottimizzazione, la conversione dei dati da JSON a parquet è abilitata in Amazon Kinesis Data Firehose.
- Proiezione delle partizioni
-
Questa funzionalità di Athena crea automaticamente partizioni per ogni giorno per migliorare le prestazioni delle query basate sulla data.
Configurazione del data lake
Utilizza la console Amazon Chime SDK per completare i seguenti passaggi.
-
Avvia la console Amazon Chime SDK ( https://console.aws.amazon.com/chime-sdk/home
) e nel pannello di navigazione, in Call Analytics, scegli Configurazioni. -
Completa il passaggio 1, scegli Avanti e nella pagina Passaggio 2, seleziona la casella di controllo Voice Analytics.
-
In Dettagli di output, seleziona la casella di controllo Data warehouse per eseguire l'analisi storica, quindi scegli il link Deploy CloudFormation stack.
Il sistema ti rimanda alla pagina Quick create stack nella console. CloudFormation
-
Inserisci un nome per lo stack, quindi inserisci i seguenti parametri:
-
DataLakeType— Scegli Crea analisi DataLake delle chiamate. -
KinesisDataStreamName— Scegli il tuo stream. Dovrebbe essere lo stream utilizzato per lo streaming di analisi delle chiamate. -
S3BucketURI— Scegli il tuo bucket Amazon S3. L'URI deve avere il prefissos3://bucket-name -
GlueDatabaseName— Scegli un nome univoco per AWS Glue Database. Non è possibile riutilizzare un database esistente nell' AWS account.
-
-
Scegli la casella di controllo di conferma, quindi scegli Crea data lake. Attendi 10 minuti affinché il sistema crei il lago.
Configurazione del data lake utilizzando AWS CLI
Si usa AWS CLI per creare un ruolo con i permessi per chiamare lo CloudFormation stack di creazione. Segui la procedura seguente per creare e configurare i ruoli IAM. Per ulteriori informazioni, consulta Creating a stack nella Guida per l'AWS CloudFormation utente.
-
Crea un ruolo chiamato AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role e allega al ruolo una politica di fiducia che consenta di assumere il ruolo. CloudFormation
-
Crea una policy di fiducia IAM utilizzando il seguente modello e salva il file in formato.json.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
Esegui il aws iam create-role comando e passa la policy di fiducia come parametro.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
Annota il ruolo arn restituito dalla risposta. role arn è richiesto nel passaggio successivo.
-
-
Crea una policy con il permesso di creare uno CloudFormation stack.
-
Crea una policy IAM utilizzando il seguente modello e salva il file in formato.json. Questo file è necessario quando si chiama create-policy.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
Esegui aws iam create-policy e passa la policy create stack come parametro.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
Annota il ruolo arn restituito dalla risposta. role arn è richiesto nel passaggio successivo.
-
-
Collegare la policy aws iam attach-role-policy al ruolo.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
Crea uno CloudFormation stack e inserisci i parametri richiesti:. aws cloudformation create-stack
Fornisci i valori dei parametri per ogni ParameterKey utilizzo ParameterValue.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
Risorse create dalla configurazione del data lake
La tabella seguente elenca le risorse create durante la creazione di un data lake.
Tipo di risorsa |
Nome e descrizione della risorsa |
Nome servizio |
|---|---|---|
Database del catalogo dati AWS Glue |
GlueDatabaseName— Raggruppa logicamente tutte le tabelle di dati di AWS Glue che appartengono agli approfondimenti sulle chiamate e all'analisi vocale. |
Analisi delle chiamate, analisi della voce |
|
Tabelle del catalogo dati AWS Glue |
amazon_chime_sdk_call_analytics_firehose_schema — Schema combinato per l'analisi vocale dell'analisi delle chiamate che viene fornito a Kinesis Firehose. |
Analisi delle chiamate, analisi vocale |
call_analytics_metadata — Schema per i metadati di analisi delle chiamate. Contiene e SIPmetadata OneTimeMetadata. |
Analisi delle chiamate |
|
| call_analytics_recording_metadata — Schema per i metadati di registrazione e miglioramento vocale | Analisi delle chiamate, analisi della voce | |
transcribe_call_analytics — Schema per il payload «UtteranceEvent» TranscribeCallAnalytics |
Analisi delle chiamate |
|
transcribe_call_analytics_category_events — Schema per il payload «CategoryEvent» TranscribeCallAnalytics |
Analisi delle chiamate |
|
transcribe_call_analytics_post_call — Schema per il payload riassuntivo di Post Call Transcribe Call Analytics |
Analisi delle chiamate |
|
transcribe — Schema per Transcribe Payload |
Analisi delle chiamate |
|
voice_analytics_status — Schema per eventi pronti per l'analisi vocale |
Analisi vocale |
|
speaker_search_status — Schema per le corrispondenze di identificazione |
Analisi vocale |
|
voice_tone_analysis_status — Schema per gli eventi di analisi del tono vocale |
Analisi vocale |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics- — |
Analisi delle chiamate, analisi della voce |
Gruppo di lavoro Amazon Athena |
GlueDatabaseName- AmazonChime SDKData Analytics: gruppo logico di utenti per controllare le risorse a cui hanno accesso durante l'esecuzione delle query. |
Analisi delle chiamate, analisi della voce |
