Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS Clean Rooms ML
AWS Clean Rooms ML consente a due o più parti di eseguire modelli di apprendimento automatico sui propri dati senza la necessità di condividerli tra loro. Il servizio fornisce controlli che migliorano la privacy che consentono ai proprietari dei dati di proteggere i propri dati e il proprio modello IP. Puoi utilizzare modelli AWS creati o portare il tuo modello personalizzato.
Per una spiegazione più dettagliata di come funziona, vediLavori su più account.
Per ulteriori informazioni sulle funzionalità dei modelli Clean Rooms ML, consulta i seguenti argomenti.
Argomenti
Come funziona AWS Clean Rooms ML con AWS i modelli
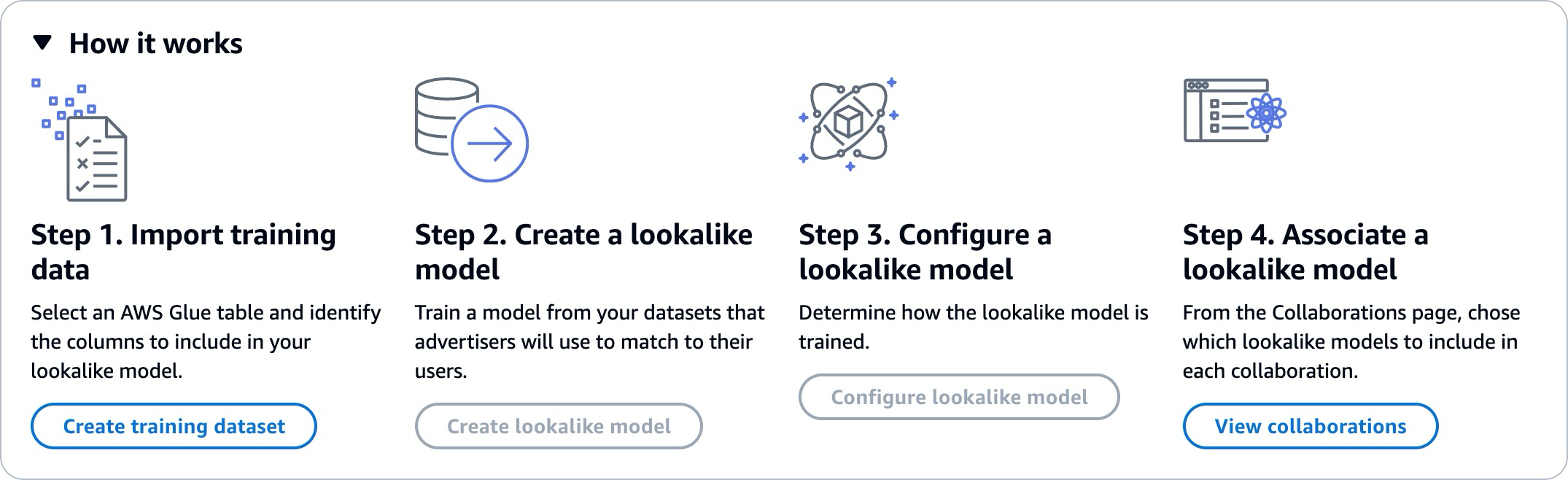
Lavorare con modelli simili richiede che due parti, un fornitore di dati di formazione e un fornitore di dati iniziali, lavorino in sequenza AWS Clean Rooms per portare i propri dati in una collaborazione. Questo è il flusso di lavoro che il fornitore di dati di formazione deve completare per primo:
-
I dati del fornitore di dati di formazione devono essere archiviati in una tabella del catalogo AWS Glue dati contenente le interazioni tra utenti e elementi. Come minimo, i dati di addestramento devono contenere una colonna ID utente, una colonna ID di interazione e una colonna timestamp.
-
Il fornitore di dati di formazione registra i dati di allenamento con. AWS Clean Rooms
-
Il fornitore di dati di addestramento crea un modello simile che può essere condiviso con più fornitori di dati iniziali. Il modello Lookalike è una rete neurale profonda che può impiegare fino a 24 ore per addestrarsi. Non viene riaddestrato automaticamente e ti consigliamo di riaddestrare il modello settimanalmente.
-
Il fornitore di dati di formazione configura il modello lookalike, incluso se condividere i parametri di pertinenza e la posizione in Amazon S3 dei segmenti di output. Il fornitore di dati di formazione può creare più modelli simili configurati a partire da un unico modello simile.
-
Il fornitore di dati di formazione associa il modello di audience configurato a una collaborazione condivisa con un fornitore di dati iniziali.
Questo è il flusso di lavoro che il fornitore di dati iniziali deve completare successivamente:
-
I dati del fornitore di dati iniziali possono essere archiviati in un bucket Amazon S3 o possono provenire dai risultati di una query.
-
Il fornitore di dati iniziali avvia la collaborazione che condivide con il fornitore di dati di formazione.
-
Il fornitore di dati iniziali crea un segmento simile dalla scheda Clean Rooms ML della pagina di collaborazione.
-
Il fornitore di dati iniziali può valutare le metriche di pertinenza, se sono state condivise, ed esportare il segmento simile per utilizzarlo all'esterno. AWS Clean Rooms
Come funziona AWS Clean Rooms ML con modelli personalizzati
Con Clean Rooms ML, i membri di una collaborazione possono utilizzare un algoritmo di modello personalizzato dockerizzato archiviato in Amazon ECR per analizzare congiuntamente i propri dati. A tale scopo, il fornitore del modello deve creare un'immagine e archiviarla in Amazon ECR. Segui i passaggi in Amazon Elastic Container Registry User Guide per creare un repository privato che conterrà il modello ML personalizzato.
Qualsiasi membro di una collaborazione può essere il fornitore del modello, a condizione che disponga delle autorizzazioni corrette. Tutti i membri di una collaborazione possono contribuire al modello con dati di addestramento, dati di inferenza o entrambi. Ai fini di questa guida, i membri che forniscono dati sono indicati come fornitori di dati. Il membro che crea la collaborazione è l'autore della collaborazione e questo membro può essere il fornitore del modello, uno dei fornitori di dati o entrambi.
Al livello più alto, ecco i passaggi che devono essere completati per eseguire la modellazione ML personalizzata:
-
Il creatore della collaborazione crea una collaborazione e assegna a ciascun membro le abilità e la configurazione di pagamento appropriate. Il creatore della collaborazione deve assegnare la capacità del membro di ricevere gli output del modello o ricevere i risultati dell'inferenza al membro appropriato in questa fase, poiché non può essere aggiornata dopo la creazione della collaborazione. Per ulteriori informazioni, consulta Creazione e partecipazione alla collaborazione in AWS Clean Rooms ML.
-
Il fornitore del modello configura e associa il proprio modello ML containerizzato alla collaborazione e garantisce l'impostazione dei vincoli di privacy per i dati esportati. Per ulteriori informazioni, consulta Configurazione di un algoritmo modello in AWS Clean Rooms ML.
-
I fornitori di dati contribuiscono con i propri dati alla collaborazione e garantiscono che le loro esigenze di privacy siano specificate. I fornitori di dati devono consentire al modello di accedere ai propri dati. Per ulteriori informazioni, consultare Contribuire ai dati di formazione in AWS Clean Rooms ML e Associazione dell'algoritmo del modello configurato in AWS Clean Rooms ML.
-
Un membro della collaborazione crea la configurazione ML, che definisce dove vengono esportati gli artefatti del modello o i risultati dell'inferenza.
-
Un membro della collaborazione crea un canale di input ML che fornisce input al contenitore di formazione o al contenitore di inferenza. Il canale di input ML è una query che definisce i dati da utilizzare nel contesto dell'algoritmo del modello.
-
Un membro della collaborazione richiama l'addestramento del modello utilizzando il canale di input ML e l'algoritmo del modello configurato. Per ulteriori informazioni, consulta Creazione di un modello addestrato in AWS Clean Rooms ML.
-
(Facoltativo) Il model trainer richiama il processo di esportazione del modello e gli artefatti del modello vengono inviati al destinatario dei risultati del modello. Solo i membri con una configurazione ML valida e la capacità dei membri di ricevere l'output del modello possono ricevere gli artefatti del modello. Per ulteriori informazioni, consulta Esportazione di artefatti del modello da AWS Clean Rooms ML.
-
(Facoltativo) Un membro della collaborazione richiama l'inferenza del modello utilizzando il canale di input ML, l'ARN del modello addestrato e l'algoritmo del modello configurato per l'inferenza. I risultati dell'inferenza vengono inviati al ricevitore di uscita dell'inferenza. Solo i membri con una configurazione ML valida e la capacità dei membri di ricevere l'output di inferenza possono ricevere risultati di inferenza.
Ecco i passaggi che devono essere completati dal fornitore del modello:
-
Crea un'immagine docker Amazon ECR compatibile con l' SageMaker AI. Clean Rooms ML supporta solo immagini docker compatibili con SageMaker AI.
-
Dopo aver creato un'immagine docker compatibile con l' SageMaker AI, invia l'immagine ad Amazon ECR. Segui le istruzioni nella Guida per l'utente di Amazon Elastic Container Registry per creare un'immagine di formazione sui container.
-
Configura l'algoritmo del modello da utilizzare in Clean Rooms ML.
-
Fornisci il link al repository Amazon ECR e tutti gli argomenti necessari per configurare l'algoritmo del modello.
-
Fornisci un ruolo di accesso al servizio che consenta a Clean Rooms ML di accedere al repository Amazon ECR.
-
Associa l'algoritmo del modello configurato alla collaborazione. Ciò include la fornitura di una politica sulla privacy che definisce i controlli per i registri dei contenitori, i registri degli errori, le CloudWatch metriche e i limiti sulla quantità di dati che possono essere esportati dai risultati del contenitore.
-
Ecco i passaggi che devono essere completati dal fornitore di dati per collaborare con un modello ML personalizzato:
-
Configura una AWS Glue tabella esistente con una regola di analisi personalizzata. Ciò consente a un insieme specifico di query preapprovate o account preapprovati di utilizzare i tuoi dati.
-
Associa la tabella configurata a una collaborazione e fornisci un ruolo di accesso al servizio che può accedere alle tue tabelle. AWS Glue
-
Aggiungi una regola di analisi della collaborazione alla tabella che consente all'associazione degli algoritmi del modello configurato di accedere alla tabella configurata.
-
Dopo aver associato e configurato il modello e i dati in Clean Rooms ML, il membro con la capacità di eseguire query fornisce una query SQL e seleziona l'algoritmo del modello da utilizzare.
Al termine dell'addestramento del modello, quel membro avvia l'esportazione degli artefatti di addestramento del modello o dei risultati dell'inferenza. Questi artefatti o risultati vengono inviati al membro con la possibilità di ricevere l'output del modello addestrato. Il destinatario dei risultati deve configurare il proprio modello MachineLearningConfiguration prima di poter ricevere l'output del modello.
