Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Metriche di classificazione personalizzate
Amazon Comprehend fornisce metriche per aiutarti a stimare le prestazioni di un classificatore personalizzato. Amazon Comprehend calcola le metriche utilizzando i dati di test del processo di formazione del classificatore. Le metriche rappresentano accuratamente le prestazioni del modello durante l'allenamento, quindi approssimano le prestazioni del modello per la classificazione di dati simili.
Utilizza operazioni API, ad esempio DescribeDocumentClassifierper recuperare le metriche per un classificatore personalizzato.
Nota
Fai riferimento a Metrics: Precision, recall e FScore
Metriche
Amazon Comprehend supporta le seguenti metriche:
Per visualizzare le metriche di un classificatore, apri la pagina dei dettagli del classificatore nella console.
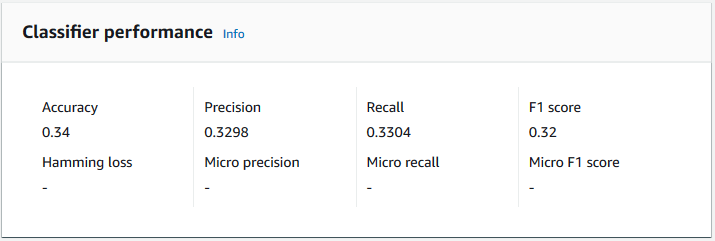
Accuratezza
La precisione indica la percentuale di etichette dei dati di test che il modello ha previsto con precisione. Per calcolare l'accuratezza, dividi il numero di etichette previste con precisione nei documenti di test per il numero totale di etichette nei documenti di test.
Ad esempio
| Etichetta effettiva | Etichetta prevista | Preciso/errato |
|---|---|---|
|
1 |
1 |
Preciso |
|
0 |
1 |
Errato |
|
2 |
3 |
Errato |
|
3 |
3 |
Preciso |
|
2 |
2 |
Preciso |
|
1 |
1 |
Preciso |
|
3 |
3 |
Preciso |
L'accuratezza è costituita dal numero di previsioni accurate diviso per il numero di campioni complessivi dei test = 5/7 = 0,714 o 71,4%
Precisione (precisione macro)
La precisione è una misura dell'utilità dei risultati del classificatore nei dati del test. È definito come il numero di documenti classificati accuratamente, diviso per il numero totale di classificazioni per la classe. L'elevata precisione significa che il classificatore ha restituito risultati significativamente più pertinenti rispetto a quelli non pertinenti.
La Precision metrica è anche nota come Macro Precision.
L'esempio seguente mostra i risultati di precisione per un set di test.
| Etichetta | Dimensione del campione | Precisione dell'etichetta |
|---|---|---|
|
Etichetta_1 |
400 |
0.75 |
|
Etichetta_2 |
300 |
0,80 |
|
Etichetta_3 |
30000 |
0.90 |
|
Etichetta_4 |
20 |
0.50 |
|
Etichetta_5 |
10 |
0,40 |
La metrica Precision (Macro Precision) per il modello è quindi:
Macro Precision = (0.75 + 0.80 + 0.90 + 0.50 + 0.40)/5 = 0.67Richiamo (richiamo di macro)
Indica la percentuale di categorie corrette nel testo che il modello è in grado di prevedere. Questa metrica deriva dalla media dei punteggi di richiamo di tutte le etichette disponibili. Il richiamo è una misura della completezza dei risultati del classificatore per i dati del test.
Un richiamo elevato significa che il classificatore ha restituito la maggior parte dei risultati pertinenti.
La Recall metrica è anche nota come Macro Recall.
L'esempio seguente mostra i risultati di richiamo per un set di test.
| Etichetta | Dimensione del campione | Richiamo dell'etichetta |
|---|---|---|
|
Etichetta_1 |
400 |
0,70 |
|
Etichetta_2 |
300 |
0,70 |
|
Etichetta_3 |
30000 |
0,98 |
|
Etichetta_4 |
20 |
0,80 |
|
Etichetta_5 |
10 |
0.10 |
La metrica Recall (Macro Recall) per il modello è quindi:
Macro Recall = (0.70 + 0.70 + 0.98 + 0.80 + 0.10)/5 = 0.656Punteggio F1 (punteggio macro F1)
Il punteggio F1 è derivato dai valori and. Precision Recall Misura la precisione complessiva del classificatore. Il punteggio più alto è 1 e il punteggio più basso è 0.
Amazon Comprehend calcola il punteggio Macro F1. È la media non ponderata dei punteggi F1 dell'etichetta. Utilizzando il seguente set di test come esempio:
| Etichetta | Dimensione del campione | Etichetta il punteggio F1 |
|---|---|---|
|
Etichetta_1 |
400 |
0,724 |
|
Etichetta_2 |
300 |
0,824 |
|
Etichetta_3 |
30000 |
0,94 |
|
Etichetta_4 |
20 |
0,62 |
|
Etichetta_5 |
10 |
0,16 |
Il punteggio F1 (Macro F1 Score) per il modello viene calcolato come segue:
Macro F1 Score = (0.724 + 0.824 + 0.94 + 0.62 + 0.16)/5 = 0.6536Perdita di Hamming
La frazione di etichette prevista in modo errato. Considerata anche come la frazione di etichette errate rispetto al numero totale di etichette. I punteggi più vicini allo zero sono migliori.
Micro precisione
Originale:
Simile alla metrica di precisione, tranne per il fatto che la microprecisione si basa sul punteggio complessivo di tutti i punteggi di precisione sommati.
Micro richiamo
Simile alla metrica di richiamo, tranne per il fatto che il micro richiamo si basa sul punteggio complessivo di tutti i punteggi di richiamo sommati.
Punteggio Micro F1
Il punteggio Micro F1 è una combinazione delle metriche Micro Precision e Micro Recall.
Miglioramento delle prestazioni del classificatore personalizzato
Le metriche forniscono una panoramica delle prestazioni del classificatore personalizzato durante un processo di classificazione. Se le metriche sono basse, il modello di classificazione potrebbe non essere efficace per il tuo caso d'uso. Sono disponibili diverse opzioni per migliorare le prestazioni del classificatore:
-
Nei dati di allenamento, fornisci esempi concreti che definiscano una netta separazione delle categorie. Ad esempio, fornite documenti che utilizzano Unique words/sentences per rappresentare la categoria.
-
Aggiungi altri dati per le etichette sottorappresentate nei dati di allenamento.
-
Cerca di ridurre l'inclinazione nelle categorie. Se l'etichetta più grande dei tuoi dati contiene più di 10 volte i documenti nell'etichetta più piccola, prova ad aumentare il numero di documenti per l'etichetta più piccola. Assicurati di ridurre il rapporto di inclinazione a un massimo di 10:1 tra le classi altamente rappresentate e quelle meno rappresentate. Puoi anche provare a rimuovere i documenti di input dalle classi altamente rappresentate.
