Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase 4: Preparazione dell'output di Amazon Comprehend per la visualizzazione dei dati
Per preparare i risultati dei lavori di analisi del sentimento e delle entità per la creazione di visualizzazioni di dati, usi e. AWS Glue Amazon Athena In questo passaggio, estrai i file dei risultati di Amazon Comprehend. Quindi, crei un AWS Glue crawler che esplora i tuoi dati e li cataloga automaticamente in tabelle in. AWS Glue Data Catalog Dopodiché, accedi e trasformi queste tabelle utilizzando un servizio di query Amazon Athena interattivo e senza server. Al termine di questo passaggio, i risultati di Amazon Comprehend sono puliti e pronti per la visualizzazione.
Per un processo di rilevamento di entità PII, il file di output è in testo semplice, non è un archivio compresso. Il nome del file di output è lo stesso del file di input e viene .out aggiunto alla fine. Non è necessario il passaggio di estrazione del file di output. Passa a caricare i dati in un file. AWS Glue Data Catalog
Argomenti
Prerequisiti
Prima di iniziare, completa Fase 3: Esecuzione di processi di analisi su documenti in Amazon S3.
Scarica l'output
Amazon Comprehend utilizza la compressione Gzip per comprimere i file di output e salvarli come archivio tar. Il modo più semplice per estrarre i file di output è scaricare gli archivi localmente. output.tar.gz
In questo passaggio, scarichi gli archivi di output dei sentimenti e delle entità.
Per trovare i file di output per ogni processo, torna al lavoro di analisi nella console Amazon Comprehend. Il processo di analisi fornisce la posizione S3 per l'output, da cui è possibile scaricare il file di output.
Per scaricare i file di output (console)
-
Nella console Amazon Comprehend
, nel riquadro di navigazione, torna a Analysis jobs. -
Scegli il tuo lavoro di analisi del sentiment.
reviews-sentiment-analysis -
In Output, scegli il link visualizzato accanto a Posizione dei dati di output. Questo ti reindirizza all'
output.tar.gzarchivio nel tuo bucket S3. -
Nella scheda Panoramica, scegli Scarica.
-
Sul tuo computer, rinomina l'archivio come
sentiment-output.tar.gz. Poiché tutti i file di output hanno lo stesso nome, questo ti aiuta a tenere traccia dei file Sentiment ed Entities. -
Ripeti i passaggi 1-4 per trovare e scaricare l'output del tuo
reviews-entities-analysislavoro. Sul tuo computer, rinomina l'archivio come.entities-output.tar.gz
Per trovare i file di output per ogni lavoro, utilizzate il JobId comando from the analysis per trovare la posizione S3 dell'output. Quindi, utilizzate il cp comando per scaricare il file di output sul computer.
Per scaricare i file di output (AWS CLI)
-
Per elencare i dettagli sul tuo lavoro di analisi del sentiment, esegui il comando seguente.
sentiment-job-idJobIdche hai salvato.aws comprehend describe-sentiment-detection-job --job-idsentiment-job-idSe hai perso di vista il tuo
JobIdprofilo, puoi eseguire il seguente comando per elencare tutti i tuoi lavori sentimentali e filtrarli per nome.aws comprehend list-sentiment-detection-jobs --filter JobName="reviews-sentiment-analysis" -
Nell'
OutputDataConfigoggetto, trova ilS3Urivalore. IlS3Urivalore dovrebbe essere simile al formato seguente:s3://amzn-s3-demo-bucket/.../output/output.tar.gz -
Per scaricare l'archivio dei risultati dei sentimenti nella tua directory locale, esegui il seguente comando. Sostituisci il percorso del bucket S3 con
S3Uriquello copiato nel passaggio precedente.path/sentiment-output.tar.gzsostituisce il nome dell'archivio originale per aiutarti a tenere traccia dei file di sentiment ed entities.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/sentiment-output.tar.gz -
Per elencare i dettagli sul processo di analisi delle entità, esegui il comando seguente.
aws comprehend describe-entities-detection-job --job-identities-job-idSe non conosci il tuo
JobId, esegui il comando seguente per elencare tutti i lavori delle entità e filtrare il lavoro per nome.aws comprehend list-entities-detection-jobs --filter JobName="reviews-entities-analysis" -
Dall'
OutputDataConfigoggetto nella descrizione del lavoro della tua entità, copia ilS3Urivalore. -
Per scaricare l'archivio di output delle entità nella directory locale, esegui il comando seguente. Sostituisci il percorso del bucket S3 con
S3Uriquello copiato nel passaggio precedente.path/entities-output.tar.gzsostituisce il nome dell'archivio originale.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/entities-output.tar.gz
Estrai i file di output
Prima di poter accedere ai risultati di Amazon Comprehend, decomprimi gli archivi dei sentimenti e delle entità. Puoi utilizzare il file system locale o un terminale per decomprimere gli archivi.
Se usi macOS, fai doppio clic sull'archivio nel tuo file system GUI per estrarre il file di output dall'archivio.
Se usi Windows, puoi usare uno strumento di terze parti come 7-Zip per estrarre i file di output dal tuo file system GUI. In Windows, è necessario eseguire due passaggi per accedere al file di output nell'archivio. Prima decomprimi l'archivio, quindi estrai l'archivio.
Rinomina il file dei sentimenti come sentiment-output e il file delle entità come entities-output per distinguere i file di output.
Se usi Linux o macOS, puoi usare il tuo terminale standard. Se usi Windows, devi avere accesso a un ambiente in stile Unix, come Cygwin, per eseguire i comandi tar.
Per estrarre il file di output dei sentimenti dall'archivio dei sentimenti, esegui il seguente comando nel tuo terminale locale.
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
Nota che il --transform parametro aggiunge il prefisso sentiment- al file di output all'interno dell'archivio, rinominando il file come. sentiment-output Ciò consente di distinguere tra i file di output di sentiment e quelli delle entità e di evitare la sovrascrittura.
Per estrarre il file di output delle entità dall'archivio delle entità, esegui il seguente comando nel tuo terminale locale.
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
Il --transform parametro aggiunge il prefisso entities- al nome del file di output.
Suggerimento
Per risparmiare sui costi di archiviazione in Amazon S3, puoi comprimere nuovamente i file con Gzip prima di caricarli. È importante decomprimere e decomprimere gli archivi originali perché non è AWS Glue possibile leggere automaticamente i dati da un archivio tar. Tuttavia, AWS Glue può leggere da file in formato Gzip.
Carica i file estratti
Dopo aver estratto i file, caricali nel tuo bucket. È necessario archiviare i file di output dei sentimenti e delle entità in cartelle separate AWS Glue per leggere correttamente i dati. Nel tuo bucket, crea una cartella per i risultati di sentiment estratti e una seconda cartella per i risultati delle entità estratte. Puoi creare cartelle con la console Amazon S3 o il. AWS CLI
Nel tuo bucket S3, crea una cartella per il file dei risultati del sentiment estratto e una cartella per il file dei risultati delle entità. Quindi, carica i file dei risultati estratti nelle rispettive cartelle.
Per caricare i file estratti su Amazon S3 (console)
Apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/
-
In Bucket, scegli il tuo bucket, quindi scegli Crea cartella.
-
Per il nuovo nome della cartella, inserisci
sentiment-resultse scegli Salva. Questa cartella conterrà il file di output del sentiment estratto. -
Nella scheda Panoramica del bucket, dall'elenco dei contenuti del bucket, scegli la nuova cartella.
sentiment-resultsScegli Carica. -
Scegli Aggiungi file, scegli il
sentiment-outputfile dal tuo computer locale, quindi scegli Avanti. -
Lascia le opzioni per Gestisci utenti, Accedi per altri Account AWS e Gestisci le autorizzazioni pubbliche come impostazioni predefinite. Scegli Next (Successivo).
-
Per la classe Storage, scegli Standard. Lascia le opzioni per Crittografia, Metadati e Tag come predefinite. Scegli Next (Successivo).
-
Controlla le opzioni di caricamento, quindi scegli Carica.
-
Ripeti i passaggi 1-8 per creare una cartella denominata
entities-resultse caricarvi ilentities-outputfile.
Puoi creare una cartella nel tuo bucket S3 durante il caricamento di un file con il comando. cp
Per caricare i file estratti su Amazon AWS CLI S3 ()
-
Crea una cartella sentiment e carica il tuo file di sentiment eseguendo il seguente comando. Sostituisci
path/aws s3 cppath/sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/ -
Crea una cartella di output delle entità e carica il file delle entità eseguendo il seguente comando. Sostituisci
path/aws s3 cppath/entities-output s3://amzn-s3-demo-bucket/entities-results/
Carica i dati in un AWS Glue Data Catalog
Per inserire i risultati in un database, puoi usare un AWS Glue crawler. Un AWS Glue crawler analizza i file e scopre lo schema dei dati. Quindi organizza i dati in tabelle in un AWS Glue Data Catalog (un database senza server). È possibile creare un crawler con la console o il AWS Glue . AWS CLI
Crea un AWS Glue crawler che scansioni le tue cartelle sentiment-results e entities-results quelle delle cartelle separatamente. Un nuovo ruolo IAM per AWS Glue
concede al crawler l'autorizzazione ad accedere al tuo bucket S3. Crei questo ruolo IAM durante la configurazione del crawler.
Per caricare i dati in una AWS Glue Data Catalog (console)
-
Assicurati di trovarti in una regione che supporti AWS Glue. Se ti trovi in un'altra regione, nella barra di navigazione, scegli una regione supportata dal selettore Regione. Per un elenco delle regioni che lo supportano AWS Glue, consulta la tabella delle regioni
nella Guida globale all'infrastruttura. Apri la AWS Glue console all'indirizzo https://console.aws.amazon.com/glue/
. -
Nel riquadro di navigazione, scegli Crawler, quindi scegli Aggiungi crawler.
-
Per il nome del crawler, inserisci e quindi scegli Avanti.
comprehend-analysis-crawler -
Per il tipo di sorgente Crawler, scegli Archivi dati, quindi scegli Avanti.
-
Per Aggiungi un data store, procedi come segue:
-
Per Scegli un datastore, scegliere S3.
-
Lascia vuoto il campo Connessione.
-
Per Scansionare i dati, scegli Percorso specificato nel mio account.
-
Per Includi percorso, inserisci il percorso S3 completo della cartella di output dei sentimenti:.
s3://amzn-s3-demo-bucket/sentiment-results -
Scegli Next (Successivo).
-
-
Per Aggiungi un altro archivio dati, scegli Sì, quindi scegli Avanti. Ripeti il passaggio 6, ma inserisci il percorso S3 completo della cartella di output delle entità:
s3://amzn-s3-demo-bucket/entities-results. -
Per Aggiungi un altro archivio dati, scegli No, quindi scegli Avanti.
-
Per Scegli un ruolo IAM, procedi come segue:
-
Scegli Crea un ruolo IAM.
-
Per il ruolo IAM, inserisci
glue-access-rolee quindi scegli Avanti.
-
-
Per Crea una pianificazione per questo crawler, scegli Esegui su richiesta e scegli Avanti.
-
Per Configura l'output del crawler, procedi come segue:
-
Per Database, scegliete Aggiungi database.
-
Per Database name (Nome database), immettere
comprehend-results. Questo database memorizzerà le tabelle di output di Amazon Comprehend. -
Lascia le altre opzioni sulle impostazioni predefinite e scegli Avanti.
-
-
Controlla le informazioni del crawler, quindi scegli Fine.
-
Nella console Glue, in Crawlers, scegli
comprehend-analysis-crawlere scegli Run crawler. Il completamento del crawler può richiedere alcuni minuti.
Crea un ruolo IAM AWS Glue che fornisca l'autorizzazione ad accedere al tuo bucket S3. Quindi, crea un database in. AWS Glue Data Catalog Infine, crea ed esegui un crawler che carichi i dati nelle tabelle del database.
Per caricare i dati in un AWS Glue Data Catalog file ()AWS CLI
-
Per creare un ruolo IAM per AWS Glue, procedi come segue:
-
Salva la seguente politica di attendibilità come documento JSON richiamato
glue-trust-policy.jsonsul tuo computer.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Per creare un ruolo IAM, esegui il comando seguente. Sostituiscilo
path/aws iam create-role --role-name glue-access-role --assume-role-policy-document file://path/glue-trust-policy.json -
Quando AWS CLI elenca l'Amazon Resource Number (ARN) per il nuovo ruolo, copialo e salvalo in un editor di testo.
-
Salva la seguente policy IAM come documento JSON richiamato
glue-access-policy.jsonsul tuo computer. La policy concede il AWS Glue permesso di eseguire la scansione delle cartelle dei risultati.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*", "arn:aws:s3:::amzn-s3-demo-bucket/entities-results*" ] } ] } -
Per creare la policy IAM, esegui il comando seguente. Sostituiscilo
path/aws iam create-policy --policy-name glue-access-policy --policy-document file://path/glue-access-policy.json -
Quando AWS CLI elenca l'ARN della politica di accesso, copialo e salvalo in un editor di testo.
-
Associa la nuova policy al ruolo IAM eseguendo il comando seguente. Sostituisci
policy-arnaws iam attach-role-policy --policy-arnpolicy-arn--role-name glue-access-role -
Allega la policy AWS gestita
AWSGlueServiceRoleal tuo ruolo IAM eseguendo il comando seguente.aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole --role-name glue-access-role
-
-
Crea un AWS Glue database eseguendo il comando seguente.
aws glue create-database --database-input Name="comprehend-results" -
Crea un nuovo AWS Glue crawler eseguendo il comando seguente. Sostituisci
glue-iam-role-arnaws glue create-crawler --name comprehend-analysis-crawler --roleglue-iam-role-arn--targets S3Targets=[ {Path="s3://amzn-s3-demo-bucket/sentiment-results"}, {Path="s3://amzn-s3-demo-bucket/entities-results"}] --database-name comprehend-results -
Avvia il crawler eseguendo il comando seguente.
aws glue start-crawler --name comprehend-analysis-crawlerIl completamento del crawler può richiedere alcuni minuti.
Prepara i dati per l'analisi
Ora hai un database popolato con i risultati di Amazon Comprehend. Tuttavia, i risultati sono annidati. Per disinserirli, si eseguono alcune istruzioni SQL. Amazon Athena Amazon Athena è un servizio di interrogazione interattivo che semplifica l'analisi dei dati in Amazon S3 utilizzando SQL standard. Athena è serverless, quindi non richiede alcuna infrastruttura da gestire e ha un pay-per-query modello di prezzo. In questo passaggio, crei nuove tabelle di dati puliti che puoi utilizzare per l'analisi e la visualizzazione. Si utilizza la console Athena per preparare i dati.
Per preparare i dati
Apri la console Athena all'indirizzo https://console.aws.amazon.com/athena/
. -
Nell'editor di query, scegli Impostazioni, quindi seleziona Gestisci.
-
Per Ubicazione dei risultati dell'interrogazione, immettere
s3://amzn-s3-demo-bucket/query-results/. In questo modo viene creata una nuova cartella denominataquery-resultsnel bucket che memorizza l'output delle Amazon Athena query eseguite. Seleziona Salva. -
Nell'editor delle query, scegli Editor.
-
Per Database, scegli il AWS Glue database
comprehend-resultsche hai creato. -
Nella sezione Tabelle, dovresti avere due tabelle chiamate
sentiment_resultseentities_results. Visualizzate l'anteprima delle tabelle per assicurarvi che il crawler abbia caricato i dati. Nelle opzioni di ogni tabella (i tre punti accanto al nome della tabella), scegliete Anteprima tabella. Una breve interrogazione viene eseguita automaticamente. Controlla il riquadro Risultati per assicurarti che le tabelle contengano dati.Suggerimento
Se le tabelle non contengono dati, prova a controllare le cartelle nel tuo bucket S3. Assicurati che ci sia una cartella per i risultati delle entità e una cartella per i risultati del sentiment. Quindi, prova a eseguire un nuovo AWS Glue crawler.
-
Per rimuovere la
sentiment_resultstabella, inserisci la seguente query nell'editor di query e scegli Esegui.CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results -
Per iniziare a disnidificare la tabella delle entità, inserisci la seguente query nell'editor di query e scegli Esegui.
CREATE TABLE entities_results_1 AS SELECT file, line, nested FROM entities_results CROSS JOIN UNNEST(entities) as t(nested) -
Per completare l'eliminazione della tabella delle entità, inserisci la seguente query nell'editor di query e scegli Esegui query.
CREATE TABLE entities_results_final AS SELECT file, line, nested.beginoffset AS beginoffset, nested.endoffset AS endoffset, nested.score AS score, nested.text AS entity, nested.type AS category FROM entities_results_1
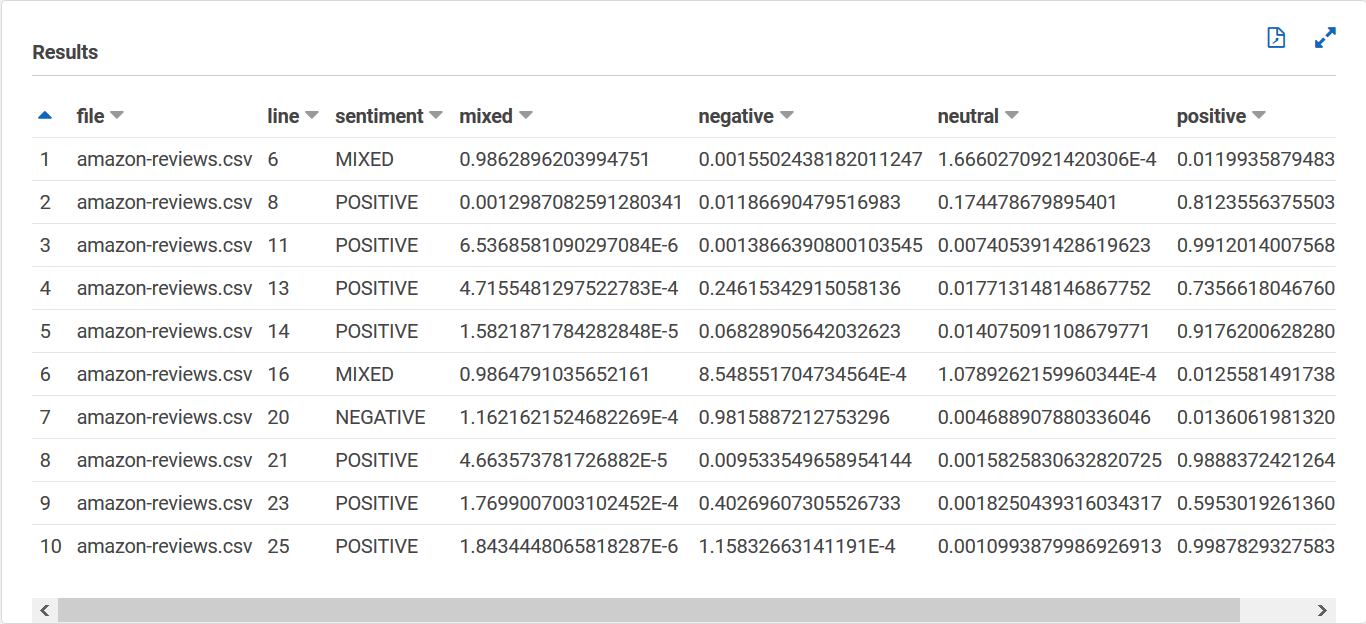
La sentiment_results_final tabella dovrebbe avere l'aspetto seguente, con colonne denominate file, line, sentiment, mixed, negative, neutral e positive. La tabella deve avere un valore per cella. La colonna sul sentimento descrive il sentimento generale più probabile di una particolare recensione. Le colonne miste, negative, neutre e positive forniscono punteggi per ogni tipo di sentimento.
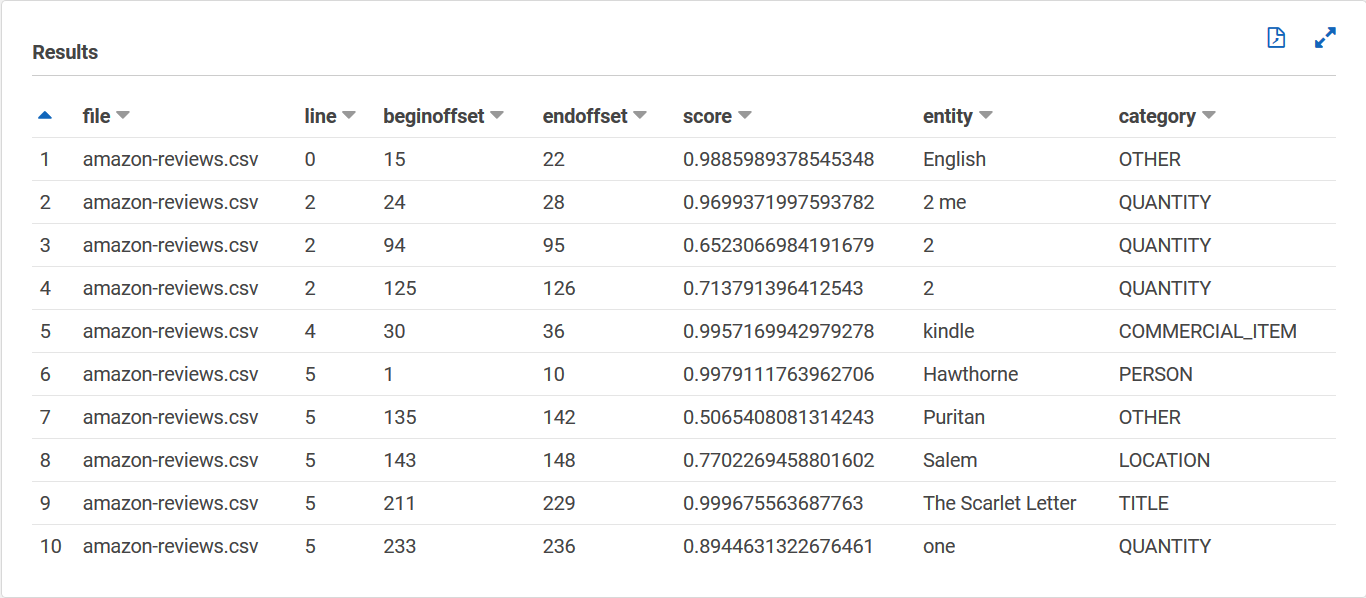
La entities_results_final tabella dovrebbe essere simile alla seguente, con colonne denominate file, line, beginoffset, endoffset, score, entity e category. La tabella deve avere un valore per cella. La colonna del punteggio indica la fiducia di Amazon Comprehend nell'entità rilevata. La categoria indica il tipo di entità rilevata da Comprehend.
Ora che hai i risultati di Amazon Comprehend caricati nelle tabelle, puoi visualizzare ed estrarre informazioni significative dai dati.
