Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Disaster recovery e cluster globali Amazon DocumentDB
Argomenti
Utilizzando un cluster globale, puoi eseguire rapidamente il ripristino da disastri come i guasti regionali. Il ripristino da emergenza viene in genere misurato utilizzando i valori per RTO e RPO.
-
Obiettivo del tempo di ripristino (RTO): il tempo necessario a un sistema per tornare in uno stato funzionante dopo un'emergenza. In altre parole, l'RTO misura i tempi di inattività. Per un cluster globale, RTO in pochi minuti.
-
Obiettivo del punto di ripristino (RPO): la quantità di dati che possono essere persi (misurata nel tempo). Per un cluster globale, l'RPO viene in genere misurato in secondi.
-
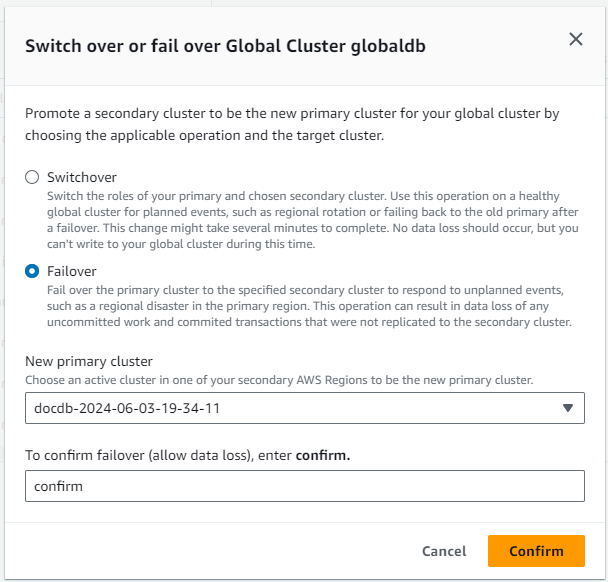
Per ripristinare il sistema dopo un'interruzione non pianificata, è possibile eseguire un failover interregionale su uno dei sistemi secondari del cluster globale. Se il cluster globale ha più regioni secondarie, assicurati di scollegare tutte le regioni secondarie che desideri promuovere come principali. Quindi, promuovi una di queste regioni secondarie affinché diventi la nuova principale. Regione AWS Infine, crei nuovi cluster in ciascuna delle altre regioni secondarie e colleghi tali cluster al tuo cluster globale.
Esecuzione di un failover gestito per un cluster globale Amazon DocumentDB
Questo approccio è destinato alla continuità aziendale in caso di una reale emergenza a livello regionale o di un'interruzione completa del livello di servizio.
Durante un failover gestito, il cluster primario viene eseguito il failover nella regione secondaria prescelta, mentre viene mantenuta la topologia di replica esistente del cluster globale Amazon DocumentDB. Il cluster secondario scelto promuove uno dei suoi nodi di sola lettura allo stato di istanza di scrittura completa. Questo passaggio consente al cluster di assumere il ruolo di cluster primario. Il database non sarà disponibile per un breve periodo di tempo mentre il cluster sta assumendo il suo nuovo ruolo. I dati che non sono stati replicati dal vecchio cluster primario al cluster secondario scelto potrebbero mancare quando questo secondario diventa il nuovo primario. Il vecchio volume primario fa del suo meglio per scattare un'istantanea prima di sincronizzarsi con il nuovo volume primario, in modo che i dati non replicati vengano conservati nell'istantanea.
Nota
È possibile eseguire un failover di cluster interregionale gestito su un cluster globale Amazon DocumentDB solo se i cluster primari e tutti i cluster secondari hanno le stesse versioni del motore. Se le versioni del motore non sono compatibili, puoi eseguire il failover manualmente seguendo i passaggi indicati in Esecuzione di un failover manuale per un cluster globale Amazon DocumentDB.
Se le versioni del motore della regione non corrispondono, il failover verrà bloccato. Verifica la presenza di eventuali aggiornamenti in sospeso e applicali per assicurarti che le versioni del motore di tutte le regioni corrispondano e che il failover globale del cluster sia sbloccato. Per ulteriori informazioni, consulta Sblocco dello switchover o del failover di un cluster globale.
Per ridurre al minimo la perdita di dati, è consigliabile eseguire le seguenti operazioni prima di utilizzare questa funzionalità:
Metti offline le applicazioni per evitare che le scritture vengano inviate al cluster primario del cluster globale Amazon DocumentDB.
Controlla i tempi di ritardo per tutti i cluster secondari di Amazon DocumentDB. La scelta della regione secondaria con il minor ritardo di replica può ridurre al minimo la perdita di dati relativamente all'attuale regione primaria in stato di errore. Controlla i tempi di ritardo per tutti i cluster secondari di Amazon DocumentDB nel cluster globale visualizzando la
GlobalClusterReplicationLagmetrica in Amazon. CloudWatch Questi parametri mostrano quanto sia indietro (in millisecondi) la replica su un cluster secondario rispetto al cluster primario.Per ulteriori informazioni sui CloudWatch parametri per Amazon DocumentDB, consulta. Metriche di Amazon DocumentDB
Durante un failover gestito, il cluster secondario scelto viene promosso al suo nuovo ruolo di primario. Tuttavia, non eredita le varie opzioni di configurazione del cluster primario. Una mancata corrispondenza nella configurazione può causare problemi di prestazioni, incompatibilità dei carichi di lavoro e altri comportamenti anomali. Per evitare tali problemi, ti consigliamo di risolvere le differenze tra i cluster globali di Amazon DocumentDB per quanto segue:
Se necessario, configura un gruppo di parametri del cluster Amazon DocumentDB per il nuovo cluster primario: puoi configurare i gruppi di parametri del cluster Amazon DocumentDB in modo indipendente per ogni cluster nei cluster globali Amazon DocumentDB. Pertanto, quando promuovi un cluster secondario affinché assuma il ruolo principale, il gruppo di parametri del secondario potrebbe essere configurato in modo diverso rispetto a quello primario. In tal caso, modifica il gruppo di parametri del cluster secondario promosso in modo che sia conforme alle impostazioni del cluster primario. Per scoprire come, consulta Modifica dei gruppi di parametri del cluster Amazon DocumentDB.
Configura strumenti e opzioni di monitoraggio, come CloudWatch eventi e allarmi Amazon: configura il cluster promosso con la stessa capacità di registrazione, allarmi e così via necessari per il cluster globale. Come per i gruppi di parametri, la configurazione di queste funzionalità non viene ereditata dal primario durante il processo di failover. Alcune CloudWatch metriche, come il ritardo di replica, sono disponibili solo per le regioni secondarie. Pertanto, un failover modifica il modo in cui visualizzare tali metriche e impostare i relativi allarmi e potrebbe richiedere modifiche da apportare a qualsiasi dashboard predefinito. Per ulteriori informazioni sui cluster e sul monitoraggio di Amazon DocumentDB, consulta. Monitoraggio di Amazon DocumentDB
In genere, il cluster secondario scelto assume il ruolo principale entro un minuto. Non appena il nodo di scrittura della nuova regione primaria è disponibile, puoi connettervi le tue applicazioni e riprendere i tuoi carichi di lavoro. Dopo aver promosso il nuovo cluster primario, Amazon DocumentDB ricostruisce automaticamente tutti i cluster regionali secondari aggiuntivi.
Poiché i cluster globali di Amazon DocumentDB utilizzano la replica asincrona, il ritardo di replica in ciascuna regione secondaria può variare. Amazon DocumentDB ricostruisce queste regioni secondarie in modo che abbiano esattamente gli stessi point-in-time dati del nuovo cluster Region primario. La durata dell'attività di ricostruzione completa può richiedere da alcuni minuti a diverse ore, a seconda delle dimensioni del volume di archiviazione e della distanza tra regioni. Quando i cluster regionali secondari terminano la ricostruzione in base alla nuova regione primaria, diventano disponibili per l'accesso in lettura. Non appena il nuovo writer primario viene promosso e reso disponibile, il cluster della nuova regione primaria può gestire le operazioni di lettura e scrittura per il cluster globale Amazon DocumentDB.
Per ripristinare la topologia originale del cluster globale, Amazon DocumentDB monitora la disponibilità della vecchia regione primaria. Non appena la regione è di nuovo integra e disponibile, Amazon DocumentDB la riaggiunge automaticamente al cluster globale come regione secondaria. Prima di creare il nuovo volume di storage nella vecchia regione primaria, Amazon DocumentDB tenta di scattare un'istantanea del vecchio volume di storage nel punto in cui si è verificato l'errore. Ciò consente di usare lo snapshot per recuperare i dati mancanti. Se questa operazione ha esito positivo, Amazon DocumentDB inserisce questa istantanea denominata «rds: docdb-unplanned-global-failover - name-of-old-primary -DB-Cluster-Timestamp» nella sezione snapshot di. AWS Management Console Puoi anche vedere questa istantanea elencata nelle informazioni restituite dall'operazione API. DescribeDBClusterSnapshots
Nota
Lo snapshot del vecchio volume di archiviazione è uno snapshot del sistema soggetto al periodo di conservazione del backup configurato sul vecchio cluster primario. Per conservare questo snapshot oltre il periodo di conservazione, puoi copiarlo e salvarlo come snapshot manuale. Per ulteriori informazioni sulla copia degli snapshot, inclusi i prezzi, consulta Copiare uno snapshot del cluster.
Dopo il ripristino della topologia originale, è possibile eseguire il failback del cluster globale nella regione primaria originale eseguendo un'operazione di switchover nel momento più opportuno per l'azienda e il carico di lavoro. A tale scopo, segui la procedura in Esecuzione di uno switchover per un cluster globale Amazon DocumentDB.
Puoi eseguire il failover del cluster globale Amazon DocumentDB utilizzando l' AWS Management Console API Amazon DocumentDB o Amazon DocumentDB. AWS CLI
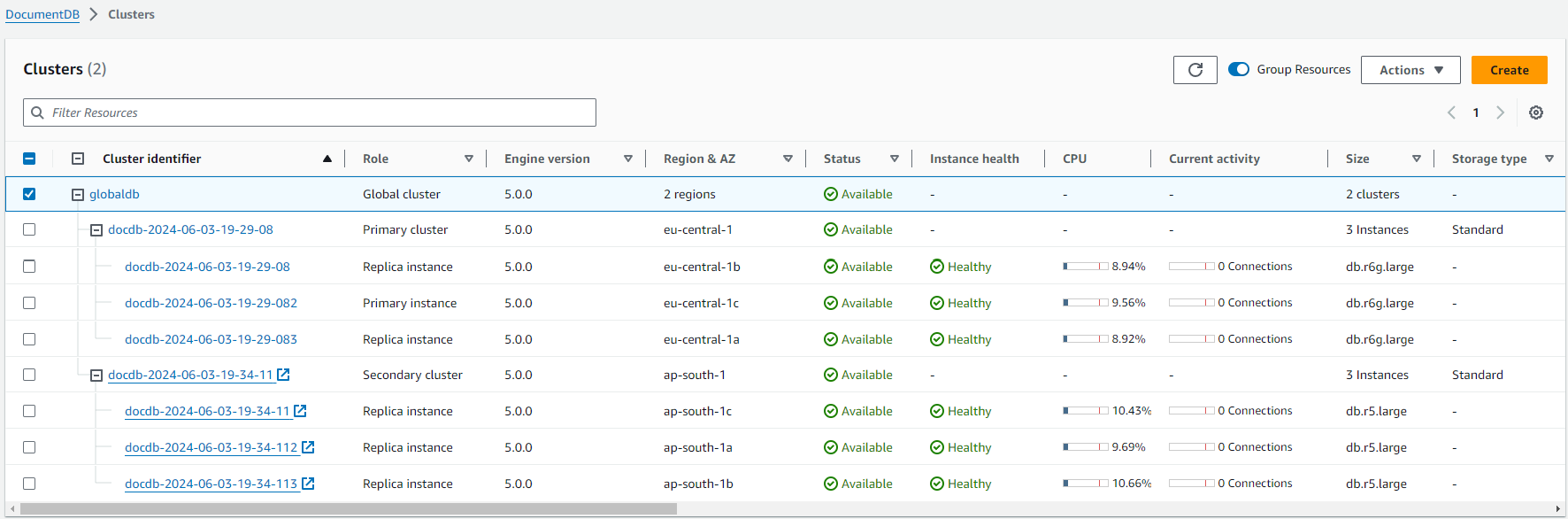

Esecuzione di un failover manuale per un cluster globale Amazon DocumentDB
Se un intero cluster in uno Regione AWS diventa non disponibile, puoi promuovere un altro cluster del cluster globale affinché read/write disponga delle funzionalità.
È possibile attivare manualmente il meccanismo di failover globale del cluster se un cluster in un altro Regione AWS è la scelta migliore come cluster principale. Ad esempio, potrebbe essere necessario incrementare la capacità di uno dei cluster secondari e quindi promuoverlo a cluster primario. Oppure l'equilibrio delle attività tra i due Regioni AWS potrebbe cambiare, in modo che il passaggio dal cluster primario a un altro Regione AWS potrebbe ridurre la latenza per le operazioni di scrittura.
La procedura seguente descrive cosa fare per promuovere uno dei cluster secondari in un cluster globale Amazon DocumentDB.
Per promuovere un cluster secondario:
-
Interrompi l'emissione di istruzioni DML e altre operazioni di scrittura sul cluster primario in caso Regione AWS di interruzione.
-
Identifica un cluster da un cluster secondario da Regione AWS utilizzare come nuovo cluster primario. Se hai due (o più) cluster secondari Regioni AWS nel tuo cluster globale, scegli il cluster secondario con il minor ritardo.
-
Scollega il cluster secondario scelto dal cluster globale.
La rimozione di un cluster secondario da un cluster globale interrompe immediatamente la replica dal primario a questo secondario e la promuove in un cluster autonomo con funzionalità complete. read/write Qualsiasi altro cluster secondario associato al cluster primario nella regione interessata dall'interruzione è ancora disponibile e può accettare chiamate dall'applicazione. Inoltre consumano risorse. Poiché state ricreando il cluster globale, per evitare problemi di tipo split-brain e di altro tipo, rimuovete gli altri cluster secondari prima di creare il nuovo cluster globale nei passaggi seguenti.
Per i passaggi dettagliati per lo scollegamento, consulta Rimozione di un cluster da un cluster globale Amazon DocumentDB.
-
Questo cluster diventa il cluster principale di un nuovo cluster globale quando inizi ad aggiungervi regioni, nel passaggio successivo.
-
Aggiungi un Regione AWS al cluster. Quando esegui questa operazione, inizia il processo di replica da primario a secondario.
-
Aggiungine altro Regioni AWS se necessario per ricreare la topologia necessaria per supportare l'applicazione. Assicurati che le scritture delle applicazioni vengano inviate al cluster corretto prima, durante e dopo aver apportato modifiche come queste, per evitare incongruenze di dati tra i cluster del cluster globale (problemi di split-brain).
-
Quando l'interruzione è stata risolta e sei pronto a riassegnare il cluster originale Regione AWS come cluster primario, esegui la stessa procedura in senso inverso.
-
Rimuovi uno dei cluster secondari dal cluster globale. Ciò gli consentirà di servire il read/write traffico.
-
Reindirizza tutto il traffico di scrittura al cluster primario dell'originale Regione AWS.
-
Aggiungi un Regione AWS per configurare uno o più cluster secondari nello stesso modo di prima Regione AWS .
I cluster globali di Amazon DocumentDB possono essere gestiti utilizzando AWS SDKs, il che consente di creare soluzioni per automatizzare il processo di failover globale dei cluster per i casi d'uso di Disaster Recovery e Business Continuity Planning. Una di queste soluzioni è disponibile per i nostri clienti con licenza Apache 2.0 ed è accessibile dal nostro repository di strumenti qui.
Esecuzione di uno switchover per un cluster globale Amazon DocumentDB
Utilizzando gli switchover, puoi modificare la regione del cluster primario su base regolare. Questo approccio è destinato agli scenari controllati, ad esempio durante la manutenzione operativa e altre procedure operative pianificate.
Esistono tre casi d'uso comuni per l'utilizzo degli switchover:
Per i requisiti relativi alla "rotazione regionale" imposti a settori specifici. Ad esempio, le normative sui servizi finanziari potrebbero imporre che i sistemi di livello 0 passino a un'altra regione per diversi mesi per garantire l'esecuzione regolare delle procedure di ripristino di emergenza.
Per applicazioni "" multiregionali. follow-the-sun Ad esempio, un'azienda potrebbe voler fornire scritture con latenza inferiore in diverse regioni in base all'orario di lavoro nei vari fusi orari.
Come zero-data-loss metodo per tornare alla regione principale originale dopo un failover.
Nota
Gli switchover sono progettati per essere utilizzati su un cluster globale Amazon DocumentDB integro. Per eseguire il ripristino da un'interruzione non pianificata, puoi eseguire la procedura appropriata descritta in Esecuzione di un failover manuale per un cluster globale Amazon DocumentDB.
Per eseguire uno switchover, tutte le regioni secondarie devono utilizzare la stessa identica versione del motore della principale. Se le versioni del motore della regione non corrispondono, lo switchover verrà bloccato. Verifica la presenza di eventuali aggiornamenti in sospeso e applicali per assicurarti che le versioni del motore di tutte le regioni corrispondano e che il passaggio al cluster globale sia sbloccato. Per ulteriori informazioni, consulta Sblocco dello switchover o del failover di un cluster globale.
Durante uno switchover, Amazon DocumentDB trasferisce il cluster primario alla regione secondaria prescelta, mantenendo al contempo la topologia di replica esistente del cluster globale. Prima di avviare il processo di passaggio, Amazon DocumentDB attende che tutti i cluster regionali secondari siano completamente sincronizzati con il cluster Region primario. Il cluster database nella regione primaria diventa di sola lettura e il cluster secondario scelto promuove uno dei relativi nodi di sola lettura allo stato di nodo di scrittura completa. La promozione di questo nodo a nodo di scrittura consente a tale cluster secondario di assumere il ruolo di cluster primario. Poiché tutti i cluster secondari sono stati sincronizzati con quello primario all'inizio del processo, il nuovo cluster primario continua a operare per il cluster globale Amazon DocumentDB senza perdere alcun dato. Il database non è disponibile per un breve periodo, mentre i cluster primario e secondario selezionati assumono i loro nuovi ruoli.
Per ottimizzare la disponibilità delle applicazioni, è consigliabile eseguire le seguenti operazioni prima di utilizzare questa funzionalità:
Esegui questa operazione durante le ore non di punta o in un altro momento in cui le scritture sul cluster primario sono minime.
Metti offline le applicazioni per evitare che le scritture vengano inviate al cluster primario del cluster globale Amazon DocumentDB.
Controlla i tempi di ritardo per tutti i cluster secondari di Amazon DocumentDB nel cluster globale visualizzando la
GlobalClusterReplicationLagmetrica in Amazon. CloudWatch Questa metrica mostra quanto sia indietro (in millisecondi) la replica su un cluster secondario rispetto al cluster primario. Questo valore è direttamente proporzionale al tempo impiegato da Amazon DocumentDB per completare lo switchover. Di conseguenza, maggiore è il valore del ritardo, maggiore sarà il tempo necessario per lo switchover.Per ulteriori informazioni sui CloudWatch parametri per Amazon DocumentDB, consulta. Metriche di Amazon DocumentDB
Durante uno switchover gestito, il cluster database secondario scelto viene promosso al nuovo ruolo primario. Tuttavia, non eredita le varie opzioni di configurazione del cluster di database primario. Una mancata corrispondenza nella configurazione può causare problemi di prestazioni, incompatibilità dei carichi di lavoro e altri comportamenti anomali. Per evitare tali problemi, ti consigliamo di risolvere le differenze tra i cluster globali di Amazon DocumentDB per quanto segue:
Se necessario, configura il gruppo di parametri del cluster Amazon DocumentDB per il nuovo cluster primario: puoi configurare i gruppi di parametri del cluster Amazon DocumentDB in modo indipendente per ogni cluster del tuo cluster globale Amazon DocumentDB. Ciò significa che quando si promuove un cluster di database secondario perché assuma il ruolo primario, il gruppo di parametri dal secondario potrebbe essere configurato in modo diverso rispetto al primario. In tal caso, modifica il gruppo di parametri del cluster di database secondario promosso in modo che sia conforme alle impostazioni del cluster primario. Per scoprire come, consulta Gestione dei gruppi di parametri del cluster Amazon DocumentDB.
Configura strumenti e opzioni di monitoraggio, come Amazon CloudWatch Events e allarmi: configura il cluster promosso con la stessa capacità di registrazione, allarmi e così via necessari per il cluster globale. Come per i gruppi di parametri, la configurazione di queste funzionalità non viene ereditata dal ruolo primario durante il processo di switchover. Alcune CloudWatch metriche, come il ritardo di replica, sono disponibili solo per le regioni primarie. Pertanto, uno switchover modifica il modo in cui visualizzare tali metriche e impostare i relativi allarmi e potrebbe richiedere modifiche da apportare a qualsiasi dashboard predefinito. Per ulteriori informazioni, consulta Monitoraggio di Amazon DocumentDB.
Nota
In genere, lo switchover del ruolo può richiedere fino a diversi minuti.
Una volta completato il processo di passaggio, il cluster Amazon DocumentDB promosso può gestire le operazioni di scrittura per il cluster globale.
Puoi passare da un cluster globale di Amazon DocumentDB utilizzando AWS Management Console o: AWS CLI


Sblocco dello switchover o del failover di un cluster globale
Gli switchover e i failover del cluster globale vengono bloccati quando non tutti i cluster regionali del cluster globale utilizzano la stessa versione del motore. Se le versioni non corrispondono, è possibile che venga visualizzato questo errore in risposta quando si richiama uno switchover o un failover: il cluster DB di destinazione specificato esegue una versione del motore con un livello di patch diverso rispetto al cluster DB di origine. Ti consigliamo di applicare regolarmente le versioni più recenti del motore per assicurarti di eseguire gli aggiornamenti più recenti per mantenere i cluster globali in uno stato integro.
Per risolvere questo errore, aggiorna prima tutte le aree secondarie e poi l'area principale alla stessa versione del motore applicando eventuali azioni di manutenzione in sospeso. Per visualizzare le azioni di manutenzione in sospeso e applicare le modifiche necessarie per correggere il problema, segui le istruzioni in una delle seguenti schede:
