Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Amazon DocumentDB: come funziona
Amazon DocumentDB (compatibile con MongoDB) è un servizio di database completamente gestito. MongoDB-compatible Con Amazon DocumentDB, puoi eseguire lo stesso codice applicativo e utilizzare gli stessi driver e strumenti che usi con MongoDB. Amazon DocumentDB è compatibile con MongoDB 3.6, 4.0, 5.0 e 8.0.
Argomenti
Quando usi Amazon DocumentDB, inizi con la creazione di un cluster. Un cluster è composto da una o più istanze database e da un volume cluster per la gestione dei dati di tali istanze. Un volume cluster Amazon DocumentDB è un volume di storage di database virtuale che si estende su più zone di disponibilità. Ogni zona di disponibilità ha una copia dei dati del cluster.
Un cluster Amazon DocumentDB è composto da due componenti:
-
Volume del cluster: utilizza un servizio di storage nativo del cloud per replicare i dati in sei modi su tre zone di disponibilità, fornendo uno storage altamente durevole e disponibile. Un cluster Amazon DocumentDB ha esattamente un volume cluster, che può archiviare fino a 128 TiB di dati.
-
Istanze: forniscono la potenza di elaborazione per il database, la scrittura e la lettura dei dati dal volume di storage del cluster. Un cluster Amazon DocumentDB può avere da 0 a 16 istanze.
Le istanze sono utilizzate per uno dei due ruoli:
-
Istanza primaria: supporta operazioni di lettura e scrittura ed esegue tutte le modifiche ai dati sul volume del cluster. Ogni cluster Amazon DocumentDB ha un'istanza principale.
-
Istanza di replica: supporta solo operazioni di lettura. Un cluster Amazon DocumentDB può avere fino a 15 repliche oltre all'istanza principale. La presenza di più repliche consente di distribuire i carichi di lavoro di lettura. Inoltre, è sufficiente collocare le repliche in zone di disponibilità separate per aumentare anche la disponibilità del cluster.
Il diagramma seguente illustra la relazione tra il volume del cluster, l'istanza principale e le repliche in un cluster Amazon DocumentDB:
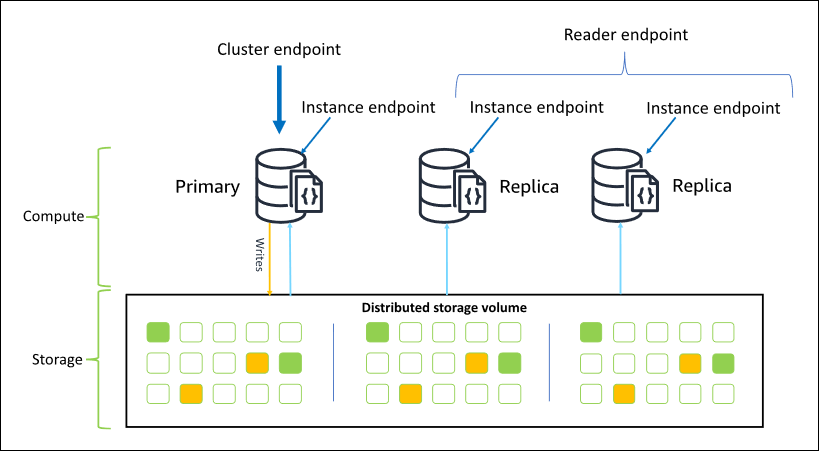
Le istanze cluster non devono appartenere alla stessa classe di istanza e possono essere sottoposte a provisioning e terminate in base alle esigenze. Questa architettura consente di aumentare la capacità di calcolo del cluster in modo indipendente dallo storage.
Quando l'applicazione scrive i dati in un'istanza primaria, questa istanza esegue una scrittura durevole nel volume cluster. Quindi replica lo stato di quella scrittura (non i dati) su ogni replica attiva. Le repliche di Amazon DocumentDB non partecipano all'elaborazione delle scritture e pertanto le repliche di Amazon DocumentDB sono vantaggiose per il ridimensionamento della lettura. Le letture dalle repliche di Amazon DocumentDB alla fine sono coerenti con un ritardo di replica minimo, in genere meno di 100 millisecondi dopo la scrittura dei dati da parte dell'istanza principale. La funzionalità garantisce che le letture dalle repliche vengano lette nell'ordine con cui sono state scritte nell'istanza primaria. Il ritardo della replica varia a seconda della percentuale di variazione dei dati e i periodi con un'intensa attività di scrittura potrebbero aumentare il ritardo della replica. Per ulteriori informazioni, consulta la pagina relativa ai parametri ReplicationLag in Metriche di Amazon DocumentDB.
Endpoint Amazon DocumentDB
Amazon DocumentDB offre diverse opzioni di connessione per soddisfare un'ampia gamma di casi d'uso. Per connetterti a un'istanza in un cluster Amazon DocumentDB, devi specificare l'endpoint dell'istanza. Un endpoint è formato da un indirizzo host e da un numero di porta, separati da due punti.
Ti consigliamo di connetterti al cluster utilizzando l'endpoint del cluster e in modalità set di replica (vedi Connessione ad Amazon DocumentDB come set di repliche), a meno che non hai un caso d'uso specifico per la connessione all'endpoint del lettore o a un endpoint di istanza. Per instradare le richieste alle repliche, scegli un'impostazione di preferenza di lettura del driver che massimizza il dimensionamento della lettura nel rispetto dei requisiti di coerenza di lettura dell'applicazione. La preferenza di lettura secondaryPreferred consente la lettura delle repliche e libera l'istanza primaria per eseguire ulteriori operazioni.
I seguenti endpoint sono disponibili da un cluster Amazon DocumentDB.
Endpoint del cluster
L'endpoint del cluster consente la connessione all'istanza primaria corrente del cluster. L'endpoint del cluster può essere utilizzato per le operazioni di lettura e scrittura. Un cluster Amazon DocumentDB ha esattamente un endpoint del cluster.
L'endpoint del cluster fornisce il supporto per il failover per le connessioni in lettura e scrittura al cluster. Se l'istanza primaria corrente del cluster non riesce e il cluster ha almeno una replica di lettura attiva, l'endpoint del cluster reindirizza automaticamente le richieste di connessione a una nuova istanza primaria. Quando ti connetti al cluster Amazon DocumentDB, ti consigliamo di connetterti al cluster utilizzando l'endpoint del cluster e in modalità set di repliche (vedi). Connessione ad Amazon DocumentDB come set di repliche
Di seguito è riportato un esempio di endpoint del cluster Amazon DocumentDB:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Di seguito è riportato un esempio della stringa di connessione che utilizza questo endpoint del cluster:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Per ulteriori informazioni sulla ricerca di un endpoint del cluster, consulta Individuazione degli endpoint di un cluster.
Endpoint di lettura
L'endpoint lettore bilancia il carico delle connessioni di sola lettura in tutte le repliche disponibili nel cluster. Un endpoint di lettura del cluster fungerà da endpoint del cluster se ci si connette in replicaSet modalità, il che significa che nella stringa di connessione, il parametro del set di replica è. &replicaSet=rs0 In questo caso, sarai in grado di eseguire operazioni di scrittura sul primario. Tuttavia, se ci si connette al cluster specificandodirectConnection=true, il tentativo di eseguire un'operazione di scrittura tramite una connessione all'endpoint di lettura genera un errore. Un cluster Amazon DocumentDB ha esattamente un endpoint di lettura.
Se il cluster contiene solo un'istanza (primaria), l'endpoint lettore si connette all'istanza primaria. Quando aggiungi un'istanza di replica al tuo cluster Amazon DocumentDB, l'endpoint di lettura apre connessioni di sola lettura alla nuova replica dopo che è attiva.
Di seguito è riportato un esempio di endpoint di lettura per un cluster Amazon DocumentDB:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Di seguito è riportato un esempio della stringa di connessione che utilizza un endpoint lettore:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
L'endpoint lettore bilancia il carico delle connessioni di sola lettura, non delle richieste di lettura. Se alcune connessioni dell'endpoint lettore vengono utilizzate più di altre, le richieste di lettura potrebbero non essere equamente divise tra le istanze nel cluster. Si consiglia di distribuire le richieste collegandosi all'endpoint del cluster come set di repliche e utilizzando l'opzione preferenza di lettura secondaryPreferred.
Per ulteriori informazioni sulla ricerca di un endpoint del cluster, consulta Individuazione degli endpoint di un cluster.
Endpoint dell'istanza
Un endpoint dell'istanza si connette a un'istanza specifica all'interno del cluster. L'endpoint dell'istanza per l'istanza primaria corrente può essere utilizzato per le operazioni di lettura e scrittura. Tuttavia, il tentativo di eseguire operazioni di scrittura su un endpoint dell'istanza per una replica di lettura genera un errore. Un cluster Amazon DocumentDB ha un endpoint di istanza per istanza attiva.
Un endpoint dell'istanza fornisce il controllo diretto sulle connessioni a una specifica istanza per scenari in cui l'utilizzo di endpoint lettore o del cluster potrebbe non essere appropriato. Un caso d'uso di esempio è il provisioning per un carico di lavoro di analisi di sola lettura periodico. Puoi effettuare il provisioning di un'istanza di replica con dimensioni superiori a quelle normali, connetterti direttamente a questa nuova istanza di grandi dimensioni con l'endpoint dell'istanza, eseguire query di analisi e terminare l'istanza. L'utilizzo dell'endpoint dell'istanza evita che il traffico delle analisi influisca negativamente sulle altre istanze del cluster.
Di seguito è riportato un esempio di endpoint di istanza per una singola istanza in un cluster Amazon DocumentDB:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Di seguito è riportato un esempio della stringa di connessione che utilizza questo endpoint dell'istanza:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Nota
Il ruolo di un'istanza primaria o di replica può variare a causa di un evento di failover. Le applicazioni non devono mai presupporre che un determinato endpoint dell'istanza sia l'istanza primaria. Non è consigliabile connettersi agli endpoint dell'istanza per le applicazioni di produzione. È consigliabile invece connettersi al cluster utilizzando l'endpoint del cluster e in modalità set di repliche (vedi Connessione ad Amazon DocumentDB come set di repliche). Per un controllo più avanzato sulla priorità di failover delle istanze, consulta Comprendere la tolleranza agli errori del cluster Amazon DocumentDB.
Per ulteriori informazioni sulla ricerca di un endpoint del cluster, consulta Individuazione dell'endpoint di un'istanza.
Modalità set di repliche
È possibile connettersi all'endpoint del cluster Amazon DocumentDB in modalità set di repliche specificando il nome del set di repliche. rs0 La connessione con la modalità per i set di repliche consente di specificare le opzioni per Read Concern, Write Concern e Read Preference. Per ulteriori informazioni, consulta Consistenza di lettura.
Di seguito è riportato un esempio della stringa di connessione connessa con la modalità per i set di repliche:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Quando ti connetti in modalità set di repliche, il cluster Amazon DocumentDB appare ai driver e ai client come un set di repliche. Le istanze aggiunte e rimosse dal cluster Amazon DocumentDB si riflettono automaticamente nella configurazione del set di repliche.
Ogni cluster Amazon DocumentDB è costituito da un singolo set di repliche con il nome predefinito. rs0 Il nome del set di repliche non può essere modificato.
La connessione all'endpoint del cluster con la modalità per i set di repliche è il metodo consigliato per l'uso generale.
Nota
Tutte le istanze in un cluster Amazon DocumentDB ascoltano le connessioni sulla stessa porta TCP.
Supporto TLS
Per ulteriori dettagli sulla connessione ad Amazon DocumentDB utilizzando Transport Layer Security (TLS), consulta. Crittografia dei dati in transito
Archiviazione Amazon DocumentDB
I dati di Amazon DocumentDB sono archiviati in un volume cluster, che è un singolo volume virtuale che utilizza unità a stato solido (SSD). Un volume cluster è composto da sei copie dei dati, che vengono replicate automaticamente su più zone di disponibilità in un'unica copia. Regione AWS Questa replica contribuisce a garantire l'estrema durata dei tuoi dati e a ridurre il rischio di perdita dei dati. Consente inoltre di assicurare che il cluster non sia più disponibile durante un failover perché le copie dei dati sono già presenti in altre zone di disponibilità. Queste copie possono continuare a servire richieste di dati alle istanze del cluster Amazon DocumentDB.
Come viene fatturato lo storage dei dati
Amazon DocumentDB aumenta automaticamente le dimensioni di un volume di cluster all'aumentare della quantità di dati. Un volume di cluster Amazon DocumentDB può crescere fino a una dimensione massima di 128 TiB; tuttavia, ti viene addebitato solo lo spazio utilizzato in un volume cluster Amazon DocumentDB. A partire da Amazon DocumentDB 4.0, quando i dati vengono rimossi, ad esempio eliminando una raccolta o un indice, lo spazio allocato complessivo diminuisce di una quantità comparabile. In questo modo, puoi ridurre i costi di archiviazione eliminando raccolte, indici e database che non ti servono più. Nella versione 3.6 di Amazon DocumentDB, il volume del cluster può riutilizzare lo spazio liberato quando si rimuovono i dati, ma le dimensioni del volume stesso non diminuiscono mai. Di conseguenza, nella versione 3.6, non è possibile che si verifichi alcuna modifica nello storage quando si elimina una raccolta o un indice, anche se lo spazio liberato viene riutilizzato.
Nota
Con Amazon DocumentDB 3.6, i costi di storage si basano sulla «soglia massima» dello storage (la quantità massima allocata per il cluster Amazon DocumentDB in qualsiasi momento). Puoi gestire i costi evitando le pratiche ETL che creano grandi volumi di informazioni temporanee o che caricano grandi volumi di nuovi dati prima di rimuovere i dati più vecchi non necessari. Se la rimozione di dati da un cluster Amazon DocumentDB comporta una notevole quantità di spazio allocato ma inutilizzato, la reimpostazione del limite massimo richiede l'esecuzione di un dump logico dei dati e il ripristino in un nuovo cluster, utilizzando uno strumento come o. mongodump mongorestore La creazione e il ripristino di una snapshot non riduce lo storage allocato perché il livello fisico dello storage sottostante rimane uguale nella snapshot ripristinata.
Nota
L'utilizzo di utilità come mongodump e I/O comporta mongorestore costi in base alle dimensioni dei dati che vengono letti e scritti nel volume di storage.
Per informazioni sullo storage e sui prezzi dei dati di Amazon DocumentDB, consulta le I/O domande frequenti sui prezzi e sui prezzi di Amazon DocumentDB (compatibile con MongoDB
Replica Amazon DocumentDB
In un cluster Amazon DocumentDB, ogni istanza di replica espone un endpoint indipendente. Questi endpoint di replica forniscono l'accesso in sola lettura ai dati del volume cluster. Consentono di calibrare il carico di lavoro in lettura dei dati su più istanze replicate. Inoltre, aiutano a migliorare le prestazioni di lettura dei dati e ad aumentare la disponibilità dei dati nel cluster Amazon DocumentDB. Le repliche di Amazon DocumentDB sono anche obiettivi di failover e vengono promosse rapidamente in caso di guasto dell'istanza principale del cluster Amazon DocumentDB.
Affidabilità di Amazon DocumentDB
Amazon DocumentDB è progettato per essere affidabile, durevole e tollerante ai guasti. (Per migliorare la disponibilità, è necessario configurare il cluster Amazon DocumentDB in modo che abbia più istanze di replica in diverse zone di disponibilità.) Amazon DocumentDB include diverse funzionalità automatiche che lo rendono una soluzione di database affidabile.
Riparazione automatica dello storage
Amazon DocumentDB conserva più copie dei dati in tre zone di disponibilità, riducendo notevolmente la possibilità di perdita dei dati a causa di un errore di storage. Amazon DocumentDB rileva automaticamente gli errori nel volume del cluster. Quando un segmento di un volume del cluster si guasta, Amazon DocumentDB ripara immediatamente il segmento. Utilizza i dati degli altri volumi che costituiscono il volume cluster per garantire che i dati del segmento riparato siano aggiornati. Di conseguenza, Amazon DocumentDB evita la perdita di dati e riduce la necessità di eseguire un ripristino point-in-time per il ripristino dopo un errore di istanza.
Riscaldamento di sopravvivenza della cache
Amazon DocumentDB gestisce la cache delle pagine in un processo separato dal database in modo che la cache delle pagine possa funzionare indipendentemente dal database. Nella remota eventualità di un errore del database, la cache di pagina rimane in memoria. In questo modo il pool di buffer viene riscaldato con lo stato più aggiornato quando il database viene riavviato.
Ripristino in caso di arresto
Amazon DocumentDB è progettato per il ripristino da un crash quasi istantaneo e per continuare a fornire i dati delle applicazioni. Amazon DocumentDB esegue il ripristino in modo asincrono su thread paralleli in modo che il database sia aperto e disponibile quasi immediatamente dopo un arresto anomalo.
Governance delle risorse
Amazon DocumentDB protegge le risorse necessarie per eseguire processi critici nel servizio, come i controlli dello stato. A tale scopo, e quando un'istanza è sottoposta a un'elevata pressione della memoria, Amazon DocumentDB limiterà le richieste. Di conseguenza, alcune operazioni potrebbero essere messe in coda per attendere che la pressione della memoria diminuisca. Se la pressione della memoria continua, le operazioni in coda potrebbero scadere. È possibile controllare se le operazioni di limitazione del servizio sono dovute o meno alla scarsa memoria con le seguenti CloudWatch metriche:,,,. LowMemThrottleQueueDepth LowMemThrottleMaxQueueDepth LowMemNumOperationsThrottled LowMemNumOperationsTimedOut Per ulteriori informazioni, consulta Monitoring Amazon DocumentDB with. CloudWatch Se riscontri una pressione sostenuta della memoria sulla tua istanza a causa dei LowMem CloudWatch parametri, ti consigliamo di aumentare la scalabilità dell'istanza per fornire memoria aggiuntiva per il carico di lavoro.
Leggi le opzioni di preferenza
Amazon DocumentDB utilizza un servizio di storage condiviso nativo del cloud che replica i dati sei volte su tre zone di disponibilità per fornire livelli elevati di durabilità. Amazon DocumentDB non si basa sulla replica dei dati su più istanze per ottenere la durabilità. I dati del cluster sono sempre durevoli, sia che contengano una singola istanza che 15.
Argomenti
Durabilità della scrittura
Amazon DocumentDB utilizza un sistema di storage unico, distribuito, tollerante ai guasti e con riparazione automatica. Questo sistema replica sei copie (V=6) dei dati in tre AWS zone di disponibilità per fornire disponibilità e durabilità elevate. Durante la scrittura dei dati, Amazon DocumentDB garantisce che tutte le scritture vengano registrate in modo duraturo sulla maggior parte dei nodi prima di confermare la scrittura al client. Se utilizzi un set di repliche MongoDB a tre nodi, l'utilizzo di un problema di scrittura {w:3, j:true} di produrrebbe la migliore configurazione possibile rispetto ad Amazon DocumentDB.
Le scritture su un cluster Amazon DocumentDB devono essere elaborate dall'istanza writer del cluster. Il tentativo di scrivere su un lettore genera un errore. Una scrittura riconosciuta da un'istanza primaria di Amazon DocumentDB è durevole e non può essere ripristinata. Amazon DocumentDB è altamente durevole per impostazione predefinita e non supporta un'opzione di scrittura non durevole. Non puoi modificare il livello di durabilità (ovvero Write Concern). Amazon DocumentDB ignora w=anything ed è effettivamente w: 3 e j: true. Non puoi ridurlo.
Poiché lo storage e l'elaborazione sono separati nell'architettura Amazon DocumentDB, un cluster con una singola istanza è estremamente durevole. La durabilità è gestita a livello di storage. Di conseguenza, un cluster Amazon DocumentDB con una singola istanza e uno con tre istanze raggiungono lo stesso livello di durabilità. Puoi configurare il cluster per il tuo caso d'uso specifico senza sacrificare la durabilità elevata per i dati.
Le scritture su un cluster Amazon DocumentDB sono atomiche all'interno di un singolo documento.
Amazon DocumentDB non supporta l'wtimeoutopzione e non restituirà un errore se viene specificato un valore. È garantito che le scritture sull'istanza primaria di Amazon DocumentDB non si blocchino a tempo indeterminato.
Isolamento della lettura
Le letture da un'istanza di Amazon DocumentDB restituiscono solo dati durevoli prima dell'inizio della query. Le letture non restituiscono mai i dati modificati dopo aver avviato l'esecuzione delle query e in nessun caso sono consentite le letture modificate.
Consistenza di lettura
I dati letti da un cluster Amazon DocumentDB sono durevoli e non verranno ripristinati. Puoi modificare la coerenza di lettura per le letture di Amazon DocumentDB specificando la preferenza di lettura per la richiesta o la connessione. Amazon DocumentDB non supporta un'opzione di lettura non durevole.
Le letture dall'istanza principale di un cluster Amazon DocumentDB sono estremamente coerenti in condizioni operative normali e hanno una consistenza di lettura dopo scrittura. Se si verifica un failover tra la scrittura e la lettura successiva, il sistema è in grado di restituire per breve tempo una lettura non particolarmente coerente. Tutte le letture da una replica di lettura garantiscono coerenza finale e restituiscono i dati nello stesso ordine, spesso con un ritardo di replica inferiore ai 100 ms.
Preferenze di lettura di Amazon DocumentDB
Amazon DocumentDB supporta l'impostazione di un'opzione di preferenza di lettura solo durante la lettura dei dati dall'endpoint del cluster in modalità set di replica. L'impostazione di un'opzione di preferenza di lettura influisce sul modo in cui il client o il driver MongoDB instrada le richieste di lettura alle istanze del cluster Amazon DocumentDB. Puoi impostare le opzioni per le preferenze di lettura per una query specifica oppure come opzione generale nel tuo driver MongoDB. Consulta la documentazione del driver o del client per istruzioni su come impostare un'opzione per le preferenze di lettura.
Se il client o il driver non si connette a un endpoint del cluster Amazon DocumentDB in modalità set di repliche, il risultato della specifica di una preferenza di lettura non è definito.
Amazon DocumentDB non supporta l'impostazione di set di tag come preferenza di lettura.
Opzioni per le preferenze di lettura supportate
-
primary—Specificare una preferenza diprimarylettura aiuta a garantire che tutte le letture vengano indirizzate all'istanza primaria del cluster. Se l'istanza primaria non è disponibile, l'operazione di lettura non riesce. Una preferenza di letturaprimarygenera la consistenza lettura dopo scrittura ed è opportuna per i casi d'uso che assegnano priorità alla consistenza lettura dopo scrittura rispetto all'alta disponibilità e al dimensionamento della lettura.L'esempio seguente specifica una preferenza di lettura
primary:db.example.find().readPref('primary') -
primaryPreferred—La specificazione di una preferenza diprimaryPreferredlettura indirizza le letture all'istanza principale durante il normale funzionamento. Se si verifica un failover dell'istanza primaria, il client indirizza le richieste a una replica. Una preferenza di letturaprimaryPreferredgenera una consistenza lettura dopo scrittura durante il normale funzionamento e letture consistenti finali durante un evento di failover. Una preferenza di letturaprimaryPreferredè opportuna per i casi d'uso che assegnano priorità alla consistenza lettura dopo scrittura rispetto al dimensionamento della lettura, ma a cui è comunque necessaria l'alta disponibilità.L'esempio seguente specifica una preferenza di lettura
primaryPreferred:db.example.find().readPref('primaryPreferred') -
secondary—La specifica di una preferenza disecondarylettura garantisce che le letture vengano indirizzate solo a una replica, mai all'istanza principale. Se in un cluster non sono presenti istanze di replica, la richiesta di lettura non riesce. Una preferenza di letturasecondarygenera letture consistenti finali ed è opportuna per i casi d'uso che assegnano priorità al throughput di scrittura dell'istanza primaria rispetto all'alta disponibilità e alla consistenza lettura dopo scrittura.L'esempio seguente specifica una preferenza di lettura
secondary:db.example.find().readPref('secondary') -
secondaryPreferred—La specificazione di una preferenza disecondaryPreferredlettura garantisce che le letture vengano indirizzate a una replica di lettura quando una o più repliche sono attive. Se in un cluster non sono presenti istanze di replica attive, la richiesta di lettura viene instradata all'istanza primaria. Una preferenza di letturasecondaryPreferredgenera letture consistenti finali quando la lettura viene gestita da una replica di lettura. Genera una consistenza lettura dopo scrittura quando la lettura viene gestita dall'istanza primaria (salvo eventi di failover). Una preferenza di letturasecondaryPreferredè opportuna per i casi d'uso che assegnano priorità alla consistenza lettura dopo scrittura rispetto all'alta disponibilità e al dimensionamento della lettura.L'esempio seguente specifica una preferenza di lettura
secondaryPreferred:db.example.find().readPref('secondaryPreferred') -
nearest—La specificazione di unanearestpreferenza di lettura indirizza le letture esclusivamente in base alla latenza misurata tra il client e tutte le istanze nel cluster Amazon DocumentDB. Una preferenza di letturanearestgenera letture consistenti finali quando la lettura viene gestita da una replica di lettura. Genera una consistenza lettura dopo scrittura quando la lettura viene gestita dall'istanza primaria (salvo eventi di failover). Una preferenza di letturanearestè opportuna per i casi d'uso che assegnano priorità al raggiungimento della minor latenza di lettura possibile e all'alta disponibilità rispetto alla consistenza lettura dopo scrittura e al dimensionamento della lettura.L'esempio seguente specifica una preferenza di lettura
nearest:db.example.find().readPref('nearest')
Elevata disponibilità
Amazon DocumentDB supporta configurazioni di cluster ad alta disponibilità utilizzando le repliche come destinazioni di failover per l'istanza principale. Se l'istanza primaria si guasta, una replica di Amazon DocumentDB viene promossa come nuova istanza primaria, con una breve interruzione durante la quale le richieste di lettura e scrittura effettuate all'istanza primaria hanno esito negativo con un'eccezione.
Se il cluster Amazon DocumentDB non include alcuna replica, l'istanza principale viene ricreata in caso di errore. Tuttavia, promuovere una replica di Amazon DocumentDB è molto più veloce che ricreare l'istanza principale. Pertanto, consigliamo di creare una o più repliche di Amazon DocumentDB come destinazioni di failover.
Le repliche che sono pensate per l'utilizzo come destinazioni di failover devono essere della stessa classe di istanza dell'istanza primaria. Devono essere assegnate in diverse zone di disponibilità dal database primario. Puoi specificare le repliche preferite come destinazioni di failover. Per le best practice sulla configurazione di Amazon DocumentDB per l'alta disponibilità, consulta. Comprendere la tolleranza agli errori del cluster Amazon DocumentDB
Ridimensionamento delle letture
Le repliche di Amazon DocumentDB sono ideali per il ridimensionamento della lettura. Sono dedicate completamente alle operazioni di lettura nel volume cluster, ossia le repliche non elaborano le scritture. Le repliche dei dati si verificano all'interno del volume cluster e non tra le istanze. Quindi le risorse di ogni replica sono dedicate all'elaborazione delle query, non a replicare e scrivere dati.
Se l'applicazione richiede più capacità di lettura, puoi aggiungere rapidamente una replica al cluster, in genere in meno di 10 minuti. Se i tuoi requisiti per la capacità di lettura diminuiscono, puoi rimuovere le repliche non necessarie. Con le repliche di Amazon DocumentDB, paghi solo per la capacità di lettura di cui hai bisogno.
Amazon DocumentDB supporta la scalabilità di lettura lato client tramite l'uso delle opzioni di preferenza di lettura. Per ulteriori informazioni, consulta Preferenze di lettura di Amazon DocumentDB.
Eliminazioni TTL
Le eliminazioni da un'area di indice TTL ottenute tramite un processo in background si basano sul miglior tentativo e non sono garantite all'interno di un determinato periodo di tempo specifico. Fattori come le dimensioni dell'istanza, l'utilizzo di risorse dell'istanza, le dimensioni documento e il throughput complessivo possono influenzare la tempistica di un'eliminazione TTL.
Quando il monitor TTL elimina i documenti, ogni eliminazione comporta costi di IO incrementando l'importo in fattura. Se la velocità di trasmissione e i tassi di eliminazione TTL aumentano, dovresti aspettarti un aumento della bolletta dovuto al maggiore utilizzo dell'IO.
Quando create un indice TTL su una raccolta esistente, dovete eliminare tutti i documenti scaduti prima di creare l'indice. L'attuale implementazione TTL è ottimizzata per l'eliminazione di una piccola parte di documenti nella raccolta, il che è tipico se il TTL è stato abilitato nella raccolta fin dall'inizio, e può comportare un IOPS più elevato del necessario se è necessario eliminare un gran numero di documenti contemporaneamente.
Se non desideri creare un indice TTL per eliminare i documenti, puoi invece segmentare i documenti in raccolte in base al tempo e semplicemente eliminare tali raccolte quando i documenti non sono più necessari. Ad esempio, puoi creare una raccolta a settimana e eliminarla senza incorrere in costi di I/O. Questo può essere molto più conveniente rispetto all'utilizzo di un indice TTL.
Risorse fatturabili
Identificazione delle risorse fatturabili di Amazon DocumentDB
Essendo un servizio di database completamente gestito, Amazon DocumentDB addebita costi per istanze, storage I/Os, backup e trasferimento dati. Per ulteriori informazioni, consulta i prezzi di Amazon DocumentDB (con compatibilità con MongoDB
Per scoprire le risorse fatturabili nel tuo account e potenzialmente eliminare le risorse, puoi utilizzare o. Console di gestione AWS AWS CLI
Utilizzando il Console di gestione AWS
Utilizzando Console di gestione AWS, puoi scoprire i cluster, le istanze e gli snapshot di Amazon DocumentDB di cui hai effettuato il provisioning per un determinato periodo. Regione AWS
Per individuare cluster, istanze e snapshot
Accedi a e apri Console di gestione AWS la console Amazon DocumentDB all'indirizzo. https://console.aws.amazon.com/docdb
-
Per scoprire risorse fatturabili in una regione diversa da quella predefinita, nell'angolo in alto a destra dello schermo, scegli Regione AWS quella in cui desideri cercare.
-
Nel riquadro di navigazione, scegliere il tipo di risorse fatturabili di interesse: Clusters (Cluster), Instances (Istanze) o Snapshots (Snapshot).
-
Tutti i cluster, le istanze o le snapshot di cui è stato eseguito il provisioning per la regione sono elencati nel riquadro a destra. Verrà addebitato il costo per i cluster, le istanze e le snapshot.
Utilizzando il AWS CLI
Utilizzando AWS CLI, puoi scoprire i cluster, le istanze e gli snapshot di Amazon DocumentDB di cui hai effettuato il provisioning per un determinato periodo. Regione AWS
Per individuare cluster e istanze
Il codice seguente elenca tutti i cluster e le istanze per la regione specificata. Per eseguire la ricerca di cluster e istanze nella regione predefinita, è possibile omettere il parametro --region.
Esempio
Per Linux, macOS o Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Per Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
L'aspetto dell'output di questa operazione è simile al seguente.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",Per individuare le snapshot
Il codice seguente elenca tutte le snapshot per la regione specificata. Per eseguire la ricerca di snapshot nella regione predefinita, è possibile omettere il parametro --region.
Per Linux, macOS o Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Per Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
L'aspetto dell'output di questa operazione è simile al seguente.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]È necessario eliminare solo le snapshot di tipo manual. Le snapshot di tipo Automated vengono eliminate quando si elimina il cluster.
Eliminazione di risorse fatturabili indesiderate
Per eliminare un cluster, è necessario eliminare prima tutte le istanze che esso contiene.
-
Per eliminare le istanze, consultare Eliminazione di un'istanza Amazon DocumentDB.
Importante
Anche eliminando le istanze in un cluster, lo storage e l'utilizzo di backup di utilizzo associati a tale cluster vengono comunque fatturati. Per interrompere ogni addebito, è necessario eliminare anche il cluster e le snapshot manuali.
-
Per eliminare i cluster, consultare Eliminazione di un cluster Amazon DocumentDB.
-
Per eliminare le snapshot manuali, consultare Eliminazione di un'istantanea del cluster.
