Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Recupero dei parametri con l'API Performance Insights
Quando Performance Insights è abilitato, l'API fornisce visibilità sulle prestazioni dell'istanza. Amazon CloudWatch Logs fornisce la fonte autorevole per i parametri di monitoraggio dei servizi forniti. AWS
Performance Insights offre una vista specifica del dominio del carico del database misurato come numero medio di sessioni attive (AAS). Questo parametro viene visualizzata dai consumer API come un set di dati temporali bidimensionali. La dimensione temporale dei dati fornisce i dati relativi al carico del database per ogni momento dell'intervallo di tempo in cui è stata eseguita la query. Ogni punto temporale scompone il carico complessivo in relazione alle dimensioni richieste, come Query, Wait-state, Application o Host, misurato in corrispondenza di quel punto temporale.
Amazon DocumentDB Performance Insights monitora l'istanza DB di Amazon DocumentDB per consentirti di analizzare e risolvere i problemi relativi alle prestazioni del database. Un modo per visualizzare i dati di Performance Insights è disponibile nella Console di gestione AWS. Performance Insights fornisce inoltre un'API pubblica per eseguire query sui dati. Puoi usare l'API per effettuare quanto segue:
-
Scaricamento dei dati in un database
-
Aggiungi dati Performance Insights ai pannelli di controllo di monitoraggio esistenti
-
Crea strumenti di monitoraggio
Per utilizzare l'API Performance Insights, abilita Performance Insights su una delle tue istanze Amazon DocumentDB. Per informazioni sull'abilitazione di Performance Insights, consulta Abilitazione e disattivazione di Performance Insights. Per ulteriori informazioni sull'API di Performance Insights, consulta la Documentazione di riferimento dell'API di Performance Insights.
L'API di Performance Insights fornisce le seguenti operazioni.
|
Operazione di Performance Insights |
AWS CLI comando |
Description |
|---|---|---|
|
Recupera le prime N chiavi di dimensione per un parametro per un determinato periodo di tempo. |
||
|
Recupera gli attributi del gruppo di dimensioni specificato per un'istanza database o un'origine dati. Ad esempio, se si specifica un ID di query e se i dettagli della dimensione sono disponibili, |
||
GetResourceMetadata |
Recupera i metadati per diverse caratteristiche. Ad esempio, i metadati potrebbero indicare che una caratteristica è attivata o disattivata su un'istanza database specifica. |
|
|
Recupera parametri Performance Insights per un set di origini dati, su un periodo di tempo. Puoi fornire gruppi di dimensioni e dimensioni specifiche e fornire criteri di aggregazione e filtro per ogni gruppo. |
||
ListAvailableResourceDimensions |
Recupera le dimensioni su cui è possibile eseguire query per ogni tipo di parametro specificato su un'istanza specificata. |
|
ListAvailableResourceMetrics |
Recupera tutti i parametri disponibili dei tipi di parametro specificati su cui è possibile eseguire query per un'istanza database specificata. |
Argomenti
AWS CLI per Performance Insights
Puoi visualizzare i dati di Performance Insights utilizzando la AWS CLI. Puoi visualizzare la guida per i comandi AWS CLI per Performance Insights inserendo quanto segue nella riga di comando.
aws pi help
Se non lo avete AWS CLI installato, consultate Installazione dell'interfaccia a riga di AWS comando nella Guida per l'AWS CLI utente per informazioni sull'installazione.
Recupero dei parametri di serie temporali
L'operazione GetResourceMetrics recupera uno o più parametri di serie temporali dai dati di Performance Insights. GetResourceMetrics richiede un parametro e un periodo di tempo e restituisce una risposta con un elenco di punti di dati.
Ad esempio, gli Console di gestione AWS usi GetResourceMetrics per compilare il grafico Counter Metrics e il grafico Database Load, come illustrato nell'immagine seguente.
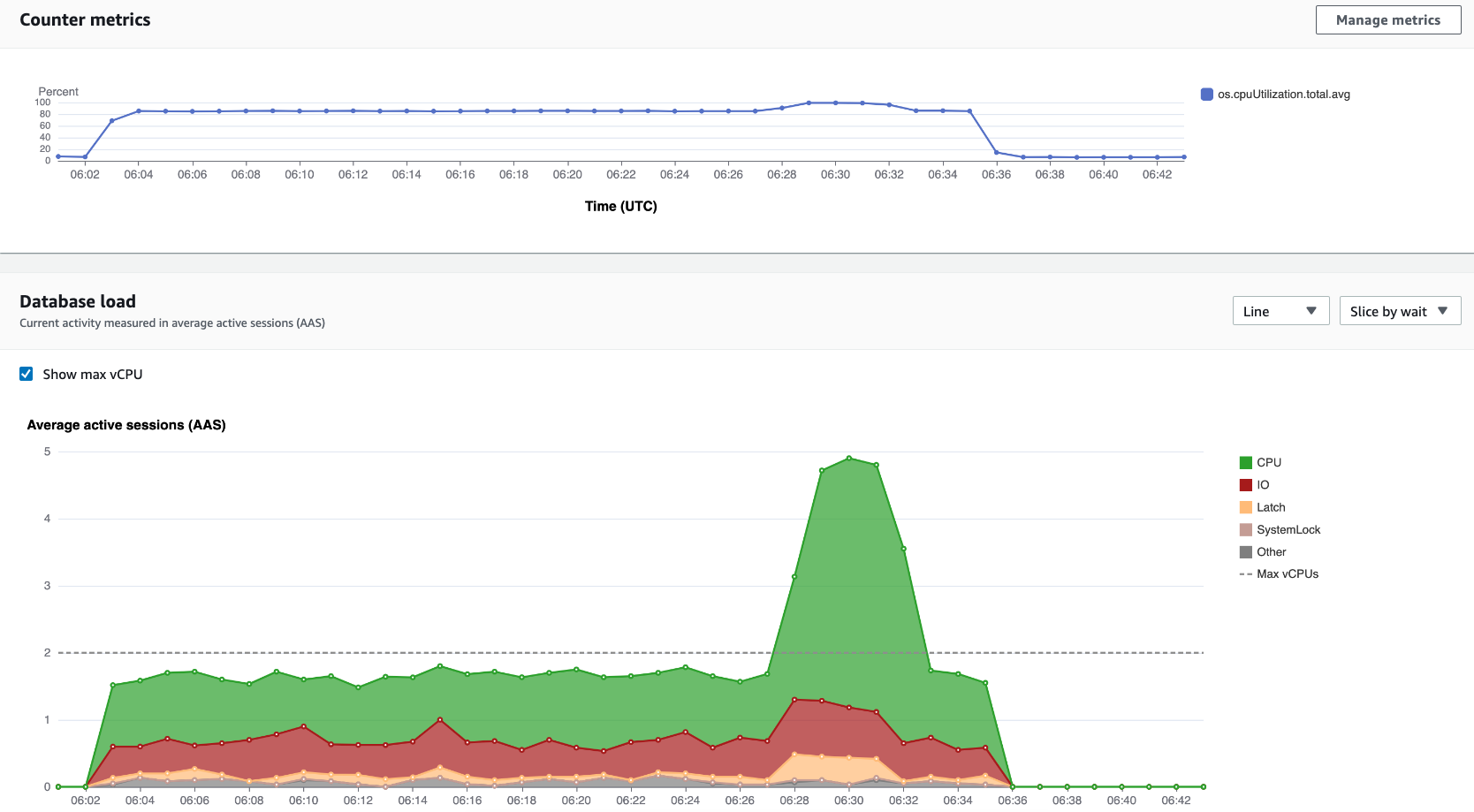
Tutti i parametri restituiti da GetResourceMetrics sono parametri di serie temporali standard ad eccezione di db.load. Questo parametro è visualizzato nel grafico Database Load (Carico del database). Il parametro db.load è diverso dagli altri parametri di serie temporali in quanto può essere suddiviso in sottocomponenti detti dimensioni. Nell'immagine precedente, db.load è suddiviso e raggruppato in base agli stati delle attese che formano il db.load.
Nota
GetResourceMetrics può anche restituire il parametro db.sampleload, ma il parametro db.load è appropriato nella maggior parte dei casi.
Per informazioni sui parametri contatore restituiti da GetResourceMetrics, consulta Performance Insights per le contrometriche.
I seguenti calcoli sono supportati per i parametri:
-
Media: il valore medio per il parametro su un periodo di tempo. Aggiungi
.avgal nome parametro. -
Minimo: il valore minimo per il parametro su un periodo di tempo. Aggiungi
.minal nome parametro. -
Massimo: il valore massimo per il parametro su un periodo di tempo. Aggiungi
.maxal nome parametro. -
Somma: la somma dei valori dei parametri su un periodo di tempo. Aggiungi
.sumal nome parametro. -
Conteggio di esempio: il numero di volte che il parametro è stato raccolto su un periodo di tempo. Aggiungi
.sample_countal nome parametro.
Ad esempio, supponiamo che un parametro venga raccolto per 300 secondi (5 minuti) e che il parametro venga raccolto una volta al minuto. I valori per ogni minuto sono 1, 2, 3, 4 e 5. In questo caso. vengono restituiti i seguenti calcoli:
-
Media: 3
-
Minimo: 1
-
Massimo: 5
-
Somma: 15
-
Conteggio del campione: 5
Per informazioni sull'utilizzo del get-resource-metrics AWS CLI comando, vedere. get-resource-metrics
Per l'opzione --metric-queries, specifica una o più query per cui ottenere risultati. Ciascuna query consiste di un parametro obbligatorio Metric e parametri facoltativi GroupBy e Filter. Di seguito è riportato un esempio della specifica di un'opzione --metric-queries.
{ "Metric": "string", "GroupBy": { "Group": "string", "Dimensions": ["string", ...], "Limit": integer }, "Filter": {"string": "string" ...}
AWS CLI esempi di Performance Insights
Gli esempi seguenti mostrano come utilizzare AWS CLI for Performance Insights.
Argomenti
Recupero dei parametri contatore
Lo screenshot seguente mostra due grafici dei parametri contatore nella Console di gestione AWS.
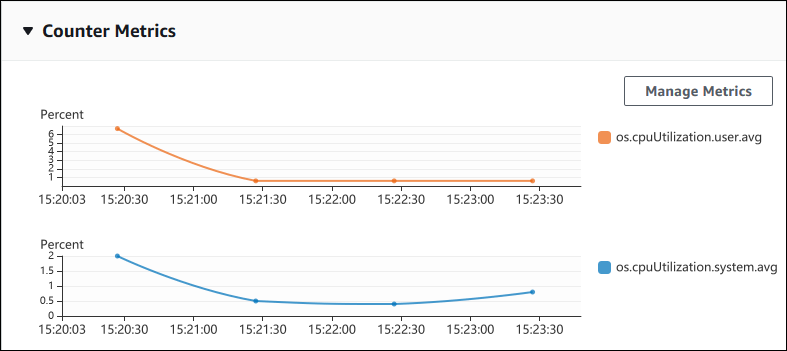
L'esempio seguente mostra come raccogliere gli stessi dati che utilizza la Console di gestione AWS per generare i due grafici dei parametri contatore.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Per Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Puoi agevolare la lettura del comando specificando un file per l'opzione --metrics-query. Il seguente esempio utilizza un file denominato query.json per l'opzione. Il file presenta i seguenti contenuti.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Esegui il comando seguente per utilizzare il file.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'esempio precedente specifica i seguenti valori per le opzioni:
-
--service-type—DOCDBper Amazon DocumentDB -
--identifier– L'ID risorsa per l'istanza database -
--start-timee--end-time– I valori ISO 8601DateTimeper il periodo su cui eseguire le query, con supporto di più formati
Esegue query per un intervallo di tempo di un'ora:
-
--period-in-seconds–60per una query al minuto -
--metric-queries– Una serie di due query, ognuna solo per un parametroIl nome del parametro utilizza punti per classificare il parametro in una categoria utile, dove l'ultimo elemento è una funzione. Nell'esempio, la funzione è
avgper ciascuna query. Come per Amazon CloudWatch, le funzioni supportate sonominmax,total, eavg.
La risposta è simile a quella riportata di seguito.
{ "AlignedStartTime": "2022-03-13T08:00:00+00:00", "AlignedEndTime": "2022-03-13T09:00:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ { "Key": { "Metric": "os.cpuUtilization.user.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", //Minute1 "Value": 3.6 }, { "Timestamp": "2022-03-13T08:02:00+00:00", //Minute2 "Value": 2.6 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric { "Key": { "Metric": "os.cpuUtilization.idle.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", "Value": 92.7 }, { "Timestamp": "2022-03-13T08:02:00+00:00", "Value": 93.7 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric ] } ] //end of MetricList } //end of response
La risposta presenta un Identifier, un AlignedStartTime e un AlignedEndTime. Poiché il valore --period-in-seconds era 60, l'ora di inizio e fine è stata allineata al minuto. Se --period-in-seconds fosse stato 3600, l'ora di inizio e fine sarebbe stata allineata all'ora.
MetricList nella risposta ha una serie di voci, ciascuna con una voce Key e una voce DataPoints. Ciascun DataPoint ha un Timestamp e un Value. Ciascun elenco Datapoints ha 60 punti di dati in quanto le query sono per dati al minuto nell'arco di un'ora, con Timestamp1/Minute1, Timestamp2/Minute2 e così via, fino a Timestamp60/Minute60.
Poiché la query è per due diversi parametri contatore, la risposta contiene due element MetricList.
Recupero della media di carico del DB per i principali stati di attesa
L'esempio seguente è la stessa query Console di gestione AWS utilizzata per generare un grafico a linee ad area impilata. Questo esempio recupera l'db.load.avgultima ora con il carico diviso in base ai primi sette stati di attesa. Il comando è come quello in Recupero dei parametri contatore. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 7 } } ]
Eseguire il comando riportato qui di seguito.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'esempio specifica la metrica db.load.avg e una dei primi sette GroupBy stati di attesa. Per i dettagli sui valori validi per questo esempio, consulta il riferimento DimensionGroupall'API Performance Insights.
La risposta è simile a quella riportata di seguito.
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_state.name": "CPU" } }, "DataPoints": [ { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the CPU key ] },//... In total we have 3 key/datapoints entries, 1) total, 2-3) Top Wait States ] //end of MetricList } //end of response
In questa risposta, ci sono tre voci inMetricList. È disponibile una voce per il totale db.load.avg e tre voci ciascuna per la db.load.avg divisione in base a uno dei primi tre stati di attesa. Poiché esisteva una dimensione di raggruppamento (a differenza del primo esempio), deve esserci una chiave per ogni raggruppamento della metrica. Può esserci una sola chiave per ciascun parametro, come nel caso d'uso del parametro contatore di base.
Recupero della media di carico del DB per Top Query
L'esempio seguente raggruppa in db.wait_state base alle prime 10 istruzioni di query. Esistono due gruppi diversi per le istruzioni di interrogazione:
-
db.query— L'istruzione di interrogazione completa, ad esempio{"find":"customers","filter":{"FirstName":"Jesse"},"sort":{"key":{"$numberInt":"1"}}} -
db.query_tokenized— L'istruzione di interrogazione tokenizzata, ad esempio{"find":"customers","filter":{"FirstName":"?"},"sort":{"key":{"$numberInt":"?"}},"limit":{"$numberInt":"?"}}
Quando si analizzano le prestazioni del database, può essere utile considerare come un unico elemento logico le istruzioni di query che differiscono solo in base ai relativi parametri. Pertanto, puoi utilizzare db.query_tokenized durante le query. Tuttavia, specialmente se sei interessatoexplain(), a volte è più utile esaminare istruzioni di query complete con parametri. Esiste una relazione padre-figlio tra le query tokenizzate e quelle complete, con più query complete (figli) raggruppate sotto la stessa query tokenizzata (principale).
Il comando in questo esempio è simile a quello in Recupero della media di carico del DB per i principali stati di attesa. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Limit": 10 } } ]
Nell'esempio seguente viene utilizzato db.query_tokenized.
Per Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Per Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
Questo esempio esegue una query di durata superiore a 1 ora, con un minuto. period-in-seconds
L'esempio specifica la metrica db.load.avg e una dei primi sette GroupBy stati di attesa. Per i dettagli sui valori validi per questo esempio, consulta il riferimento DimensionGroupall'API Performance Insights.
La risposta è simile a quella riportata di seguito.
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { "Metric": "db.load.avg" }, "DataPoints": [ //... 60 datapoints for the total db.load.avg key ] }, { "Key": {//Next key are the top tokenized queries "Metric": "db.load.avg", "Dimensions": { "db.query_tokenized.db_id": "pi-1064184600", "db.query_tokenized.id": "77DE8364594EXAMPLE", "db.query_tokenized.statement": "{\"find\":\"customers\",\"filter\":{\"FirstName\":\"?\"},\"sort\":{\"key\":{\"$numberInt\":\"?\"}},\"limit\" :{\"$numberInt\":\"?\"},\"$db\":\"myDB\",\"$readPreference\":{\"mode\":\"primary\"}}" } }, "DataPoints": [ //... 60 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized queries, 1 total key ] //End of MetricList } //End of response
Questa risposta contiene 11 voci MetricList (1 in totale, 10 delle principali query tokenizzate), con 24 voci all'ora per ogni voce. DataPoints
Per le query tokenizzate, ci sono tre voci in ogni elenco di dimensioni:
-
db.query_tokenized.statement— L'istruzione di interrogazione tokenizzata. -
db.query_tokenized.db_id— L'ID sintetico che Performance Insights genera per te. Questo esempio restituisce l'ID sinteticopi-1064184600. -
db.query_tokenized.id– L'ID della query all'interno di Performance Insights.Nel Console di gestione AWS, questo ID è denominato Support ID. Si chiama così perché l'ID è costituito da dati che AWS Support può esaminare per aiutarti a risolvere un problema con il tuo database. AWS prende molto sul serio la sicurezza e la privacy dei tuoi dati e quasi tutti i dati vengono archiviati crittografati con il tuo. AWS KMS key Pertanto, nessuno all'interno AWS può guardare questi dati. Nell'esempio precedente, sia
tokenized.statementchetokenized.db_idvengono archiviati crittografati. Se hai un problema con il tuo database, AWS Support può aiutarti facendo riferimento al Support ID.
Quando si eseguo query, potrebbe essere utile specificare un Group in GroupBy. Tuttavia, per un controllo più dettagliato dei dati restituiti, occorre specificare l'elenco delle dimensioni. Ad esempio, se tutto ciò di cui si necessita è db.query_tokenized.statement, è possibile aggiungere l'attributo Dimensions al file query.json.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Dimensions":["db.query_tokenized.statement"], "Limit": 10 } } ]
Recupero della media di carico del DB filtrata per Query
La query dell'API corrispondente in questo esempio è simile al comando in Recupero della media di carico del DB per Top Query. Tuttavia, il file query.json presenta i seguenti contenuti.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 5 }, "Filter": { "db.query_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
In questa risposta, tutti i valori vengono filtrati in base al contributo della query AKIAIOSFODNN7 tokenizzata EXAMPLE specificata nel file query.json. Le chiavi potrebbero inoltre seguire un ordine diverso rispetto a una query senza filtro, poiché sono i primi cinque stati di attesa che hanno influito sulla query filtrata.
