Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Teoria del ridimensionamento di Kubernetes
Nodes vs. Churn Rate
Spesso, quando parliamo della scalabilità di Kubernetes, lo facciamo in termini di quanti nodi ci sono in un singolo cluster. È interessante notare che questa è raramente la metrica più utile per comprendere la scalabilità. Ad esempio, un cluster da 5.000 nodi con un numero elevato ma fisso di pod non metterebbe molto a dura prova il piano di controllo dopo la configurazione iniziale. Tuttavia, se prendessimo un cluster da 1.000 nodi e provassimo a creare 10.000 posti di lavoro di breve durata in meno di un minuto, eserciteremmo una forte pressione sul piano di controllo.
Il semplice utilizzo del numero di nodi per comprendere la scalabilità può essere fuorviante. È meglio pensare in termini di velocità di cambiamento che si verifica in un determinato periodo di tempo (utilizziamo un intervallo di 5 minuti per questa discussione, poiché è quello che di solito usano le query di Prometheus per impostazione predefinita). Scopriamo perché inquadrare il problema in termini di tasso di cambiamento può darci un'idea migliore di cosa ottimizzare per raggiungere la scala desiderata.
Pensare in termini di domande al secondo
Kubernetes dispone di una serie di meccanismi di protezione per ogni componente (Kubelet, Scheduler, Kube Controller Manager e server API) per evitare di sovraccaricare l'anello successivo della catena Kubernetes. Ad esempio, Kubelet dispone di un flag per limitare le chiamate al server API a una certa velocità. Questi meccanismi di protezione sono generalmente, ma non sempre, espressi in termini di query consentite al secondo o QPS.
È necessario prestare molta attenzione quando si modificano queste impostazioni QPS. La rimozione di un collo di bottiglia, ad esempio le query al secondo su un Kubelet, avrà un impatto sugli altri componenti a valle. Ciò può sovraccaricare il sistema oltre una certa velocità, e lo farà, quindi la comprensione e il monitoraggio di ogni parte della catena di servizi sono fondamentali per scalare con successo i carichi di lavoro su Kubernetes.
Nota
Il server API ha un sistema più complesso con l'introduzione di API Priority and Fairness, di cui parleremo separatamente.
Nota
Attenzione, alcune metriche sembrano la soluzione giusta ma in realtà misurano qualcos'altro. Ad esempio, kubelet_http_inflight_requests si riferisce solo al server delle metriche in Kubelet, non al numero di richieste da Kubelet alle richieste apiserver. Ciò potrebbe indurci a configurare erroneamente il flag QPS su Kubelet. Una query sui registri di controllo per un determinato Kubelet sarebbe un modo più affidabile per controllare le metriche.
Scalabilità dei componenti distribuiti
Poiché EKS è un servizio gestito, dividiamo i componenti di Kubernetes in due categorie: componenti gestiti da AWS che includono etcd, Kube Controller Manager e Scheduler (nella parte sinistra del diagramma) e componenti configurabili dal cliente come Kubelet, Container Runtime e i vari operatori che chiamano AWS APIs come i driver di rete e archiviazione (nella parte destra del diagramma). Lasciamo il server API al centro anche se è gestito da AWS, poiché le impostazioni per la priorità e l'equità delle API possono essere configurate dai clienti.
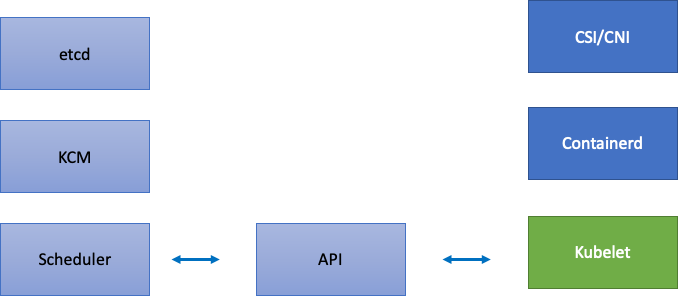
Colli di bottiglia a monte e a valle
Mentre monitoriamo ogni servizio, è importante esaminare le metriche in entrambe le direzioni per individuare eventuali rallentamenti. Impariamo come farlo usando Kubelet come esempio. Kubelet parla sia con il server API che con il runtime del contenitore; come e cosa dobbiamo monitorare per rilevare se uno dei componenti presenta un problema?
Quanti Pod per nodo
Quando esaminiamo i numeri in scala, ad esempio quanti pod possono essere eseguiti su un nodo, potremmo prendere alla lettera i 110 pod per nodo supportati da upstream.
Tuttavia, il carico di lavoro è probabilmente più complesso di quello testato in un test di scalabilità in Upstream. Per assicurarci di poter gestire il numero di pod che vogliamo utilizzare in produzione, assicuriamoci che Kubelet «stia al passo» con il runtime di Containerd.
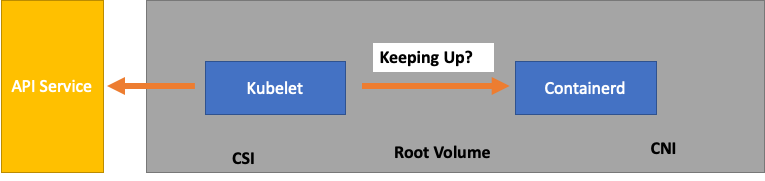
Per semplificare eccessivamente, Kubelet sta ottenendo lo stato dei pod dal runtime del contenitore (nel nostro caso Containerd). E se troppi pod cambiassero lo stato troppo velocemente? Se la velocità di modifica è troppo alta, le richieste [al runtime del contenitore] possono scadere.
Nota
Kubernetes è in continua evoluzione, questo sottosistema è attualmente sottoposto a modifiche. https://github.com/kubernetes/miglioramenti/problemi/3386

Nel grafico precedente, vediamo una linea piatta che indica che abbiamo appena raggiunto il valore di timeout per la metrica della durata della generazione degli eventi del ciclo di vita del pod. Se desideri visualizzarlo nel tuo cluster, puoi utilizzare la seguente sintassi PromQL.
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
Se assistiamo a questo comportamento di timeout, sappiamo di aver spinto il nodo oltre il limite di cui era capace. Dobbiamo correggere la causa del timeout prima di procedere ulteriormente. Ciò potrebbe essere ottenuto riducendo il numero di pod per nodo o cercando errori che potrebbero causare un elevato volume di nuovi tentativi (con conseguente impatto sul tasso di abbandono). La conclusione importante è che le metriche sono il modo migliore per capire se un nodo è in grado di gestire il tasso di abbandono dei pod assegnati anziché utilizzare un numero fisso.
Scala in base alle metriche
Sebbene il concetto di utilizzo delle metriche per ottimizzare i sistemi sia vecchio, viene spesso trascurato quando le persone iniziano il loro percorso verso Kubernetes. Invece di concentrarci su numeri specifici (ad esempio 110 pod per nodo), concentriamo i nostri sforzi sulla ricerca di metriche che ci aiutino a individuare i punti deboli nel nostro sistema. La comprensione delle soglie corrette per queste metriche può darci un alto grado di sicurezza che il nostro sistema sia configurato in modo ottimale.
L'impatto delle modifiche
Uno schema comune che potrebbe metterci nei guai è quello di concentrarci sul primo errore metrico o di registro che sembra sospetto. Quando abbiamo visto che il Kubelet stava scadendo prima, abbiamo potuto provare cose casuali, come aumentare la frequenza al secondo che Kubelet può inviare, ecc. Tuttavia, è consigliabile esaminare il quadro completo di tutto ciò che si trova a valle dell'errore che riscontriamo per primo. Apporta ogni modifica in modo mirato e supportata dai dati.
A valle di Kubelet ci sarebbe il runtime di Containerd (errori dei pod), DaemonSets come il driver di archiviazione (CSI) e il driver di rete (CNI) che comunicano con l'API, ecc. EC2
Continuiamo il nostro esempio precedente di Kubelet che non riesce a tenere il passo con il runtime. Ci sono diversi punti in cui potremmo impacchettare un nodo in modo così denso da generare errori.
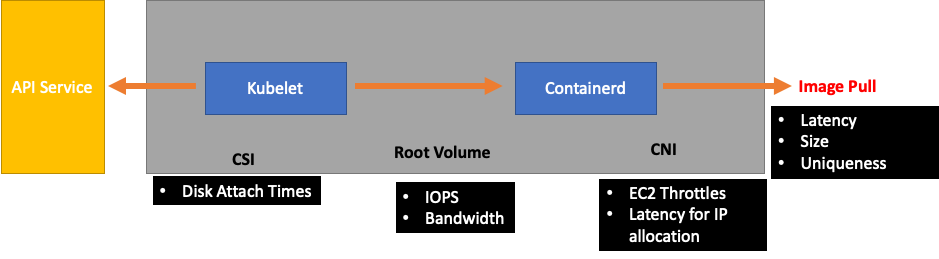
Quando progettiamo la giusta dimensione dei nodi per i nostri carichi di lavoro, si tratta di easy-to-overlook segnali che potrebbero esercitare una pressione inutile sul sistema, limitando così sia la nostra scalabilità che le prestazioni.
Il costo degli errori non necessari
I controller Kubernetes eccellono nel riprovare quando si verificano condizioni di errore, ma ciò ha un costo. Questi nuovi tentativi possono aumentare la pressione su componenti come Kube Controller Manager. Il monitoraggio di tali errori è un requisito importante dei test di scala.
Quando si verificano meno errori, è più facile individuare i problemi nel sistema. Garantendo periodicamente che i nostri cluster siano privi di errori prima delle operazioni più importanti (come gli aggiornamenti), possiamo semplificare i log di risoluzione dei problemi quando si verificano eventi imprevisti.
Espandere la nostra visione
Nei cluster su larga scala con migliaia di nodi non vogliamo cercare i colli di bottiglia singolarmente. In PromQL possiamo trovare i valori più alti in un set di dati usando una funzione chiamata topk; essendo K una variabile, inseriamo il numero di elementi che vogliamo. Qui utilizziamo tre nodi per avere un'idea se tutti i Kubelet del cluster sono saturi. Fino a questo punto abbiamo esaminato la latenza, ora vediamo se Kubelet sta scartando gli eventi.
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
Analizzando questa affermazione.
-
Utilizziamo la variabile Grafana
$__rate_intervalper assicurarci che riceva i quattro campioni di cui ha bisogno. Questo aggira un argomento complesso del monitoraggio con una variabile semplice. -
topkdacci solo i migliori risultati e il numero 3 li limita a tre. Questa è una funzione utile per le metriche a livello di cluster. -
{}dicci che non ci sono filtri, normalmente inseriresti il nome del lavoro qualunque sia la regola di scraping, tuttavia poiché questi nomi variano lo lasceremo vuoto.
Dividere il problema a metà
Per risolvere un problema nel sistema, adotteremo l'approccio di trovare una metrica che ci indichi l'esistenza di un problema a monte o a valle, in quanto ciò ci consente di dividere il problema a metà. Sarà anche un principio fondamentale del modo in cui mostriamo i dati delle nostre metriche.
Un buon punto di partenza per questo processo è il server API, in quanto ci consente di vedere se c'è un problema con un'applicazione client o con il Control Plane.
