Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cosa succede quando invii un lavoro a un cluster virtuale Amazon EMR su EKS?
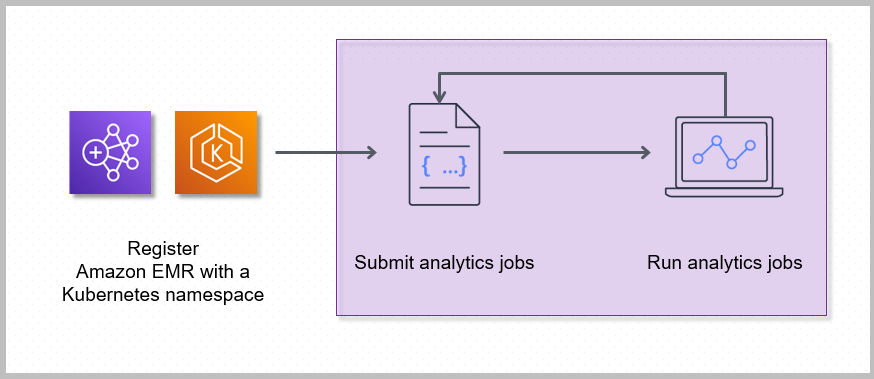
La registrazione di Amazon EMR con uno spazio dei nomi Kubernetes su Amazon EKS crea un cluster virtuale. Amazon EMR può quindi eseguire carichi di lavoro di analisi dei dati in tale spazio dei nomi. Quando si utilizza Amazon EMR su EKS per inviare i processi Spark al cluster virtuale, Amazon EMR su EKS richiede al pianificatore Kubernetes su Amazon EKS di pianificare i pod.
I seguenti passaggi e il seguente diagramma illustrano il flusso di lavoro di Amazon EMR su EKS:
-
Utilizza un cluster Amazon EKS esistente o creane uno utilizzando l'utility a riga di comando eksctl o la console di Amazon EKS.
-
Crea un cluster virtuale registrando Amazon EMR con uno spazio dei nomi in un cluster EKS.
-
Invia il lavoro al cluster virtuale utilizzando l'SDK AWS CLI o.
Per ogni processo eseguito, Amazon EMR su EKS crea un container con un'immagine di base Amazon Linux 2, Apache Spark e le dipendenze associate. Ogni processo viene eseguito in un pod che effettua il download del container e inizia a eseguirlo. Il pod termina dopo la fine del processo. Se l'immagine del container è stata già precedentemente impiegata nel nodo, viene utilizzata un'immagine memorizzata nella cache e il download viene ignorato. I container Sidecar, come ad esempio i server d'inoltro di log e parametri, possono essere implementati sul pod. Una volta terminato il processo, è comunque possibile eseguire il debug utilizzando l'interfaccia utente dell'applicazione Spark nella console di Amazon EMR.
