Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Guida introduttiva ad Amazon EMR su EKS
Questo argomento consente di iniziare a utilizzare Amazon EMR su EKS implementando un'applicazione Spark Python in un cluster virtuale. Include i passaggi per configurare le autorizzazioni corrette e avviare un lavoro. Prima di iniziare, verifica di aver completato le fasi in Configurazione di Amazon EMR su EKS. Questo ti aiuta a ottenere strumenti come la AWS CLI configurazione prima di creare il tuo cluster virtuale. Per altri modelli che possono aiutarti a iniziare, consulta la nostra guida alle best practice per i contenitori EMR
Nella procedura di configurazione sono necessarie le seguenti informazioni:
-
ID del cluster virtuale per il cluster Amazon EKS e lo spazio dei nomi Kubernetes registrato con Amazon EMR
Importante
Quando crei un cluster EKS, assicurarsi di utilizzare m5.xlarge come tipo di istanza o qualsiasi altro tipo di istanza con CPU e memoria superiori. L'utilizzo di un tipo di istanza con CPU o memoria inferiore a m5.xlarge può causare errori di processo a causa di risorse insufficienti disponibili nel cluster.
-
Nome del ruolo IAM utilizzato per l'esecuzione del processo
-
Etichetta di rilascio per la versione di Amazon EMR (ad esempio,
emr-6.4.0-latest) -
I target di destinazione per la registrazione e il monitoraggio:
-
Nome del gruppo di CloudWatch log Amazon e prefisso del flusso di log
-
Ubicazione Amazon S3 per memorizzare i log degli eventi e del container
-
Importante
I job Amazon EMR su EKS utilizzano Amazon CloudWatch e Amazon S3 come destinazioni di destinazione per il monitoraggio e la registrazione. È possibile monitorare l'avanzamento dei processi e risolvere i fallimenti visualizzando i registri dei processi inviati a queste destinazioni. Per abilitare la registrazione, la policy IAM associata al ruolo IAM per l'esecuzione del processo deve disporre delle autorizzazioni necessarie per accedere alle risorse di destinazione. Se la policy IAM non dispone delle autorizzazioni richieste, devi seguire i passaggi descritti in Configurare un job run Aggiornamento della policy di affidabilità del ruolo di esecuzione di processo for use Amazon S3 logs e Configure a job run to CloudWatch use Logs prima di eseguire questo job di esempio.
Eseguire un'applicazione Spark
Seguire la procedura seguente per eseguire una applicazione semplice Applicazione Spark su Amazon EMR su EKS. Il file entryPoint di applicazione per le applicazioni Spark Python si trova in s3://. REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.pyREGIONÈ la regione in cui risiede il tuo cluster virtuale Amazon EMR su EKS, ad esempio. us-east-1
-
Aggiornare la policy IAM per il ruolo di esecuzione del processo con le autorizzazioni richieste, come dimostrano le istruzioni riportate di seguito.
-
La prima istruzione
ReadFromLoggingAndInputScriptBucketsin questa policy concedeListBucketeGetObjectsl'accesso ai seguenti bucket Amazon S3:-
REGION.elasticmapreduceentryPointsi trova. -
amzn-s3-demo-destination-bucket‐ un bucket definito dall'utente per i dati di output. -
amzn-s3-demo-logging-bucket‐ un bucket definito dall'utente per i dati di registrazione.
-
-
La seconda istruzione
WriteToLoggingAndOutputDataBucketsin questa policy concede al processo le autorizzazioni per scrivere i dati nei bucket di output e per registrarli rispettivamente. -
La terza istruzione
DescribeAndCreateCloudwatchLogStreamconcede al job le autorizzazioni per descrivere e creare Amazon CloudWatch Logs. -
La quarta istruzione
WriteToCloudwatchLogsconcede le autorizzazioni per scrivere log su un gruppo di CloudWatch log di Amazon denominatomy_log_group_namemy_log_stream_prefix
-
-
Per eseguire un'applicazione Spark Python, utilizzare il comando seguente. Sostituisci tutti i valori sostituibili con
red italicizedi valori appropriati.REGIONÈ la regione in cui risiede il tuo cluster virtuale Amazon EMR su EKS, ad esempio.us-east-1aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.4.0-latest\ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py", "entryPointArguments": ["s3://amzn-s3-demo-destination-bucket/wordcount_output"], "sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'I dati di output di questo processo saranno disponibili a
s3://.amzn-s3-demo-destination-bucket/wordcount_outputPuoi anche creare un file JSON con i parametri specificati per l'esecuzione del processo. Poi, esegui il comando
start-job-runcon un percorso del file JSON. Per ulteriori informazioni, consulta Invio di un'esecuzione di processo con StartJobRun. Per ulteriori dettagli sulla configurazione dei parametri di esecuzione del processo, consulta Opzioni per la configurazione di un'esecuzione di processo. -
Per eseguire un'applicazione Spark SQL, utilizzare il comando seguente. Sostituisci tutti i
red italicizedvalori con i valori appropriati.REGIONÈ la regione in cui risiede il tuo cluster virtuale Amazon EMR su EKS, ad esempio.us-east-1aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.7.0-latest\ --job-driver '{ "sparkSqlJobDriver": { "entryPoint": "s3://query-file.sql", "sparkSqlParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'Di seguito un esempio di file di query. È necessario disporre di un archivio file esterno, ad esempio S3, in cui sono archiviati i dati per le tabelle.
CREATE DATABASE demo; CREATE EXTERNAL TABLE IF NOT EXISTS demo.amazonreview( marketplace string, customer_id string, review_id string, product_id string, product_parent string, product_title string, star_rating integer, helpful_votes integer, total_votes integer, vine string, verified_purchase string, review_headline string, review_body string, review_date date, year integer) STORED AS PARQUET LOCATION 's3://URI to parquet files'; SELECT count(*) FROM demo.amazonreview; SELECT count(*) FROM demo.amazonreview WHERE star_rating = 3;L'output di questo processo sarà disponibile nei log stdout del driver in S3 o CloudWatch, a seconda della configurazione.
monitoringConfiguration -
Puoi anche creare un file JSON con i parametri specificati per l'esecuzione del processo. Poi, esegui il comando start-job-run con un percorso del file JSON. Per ulteriori informazioni, vedere Invio di un'esecuzione di processo. Per ulteriori informazioni sulla configurazione dei parametri di esecuzione del processo, vedere Opzioni per la configurazione di un'esecuzione di processo.
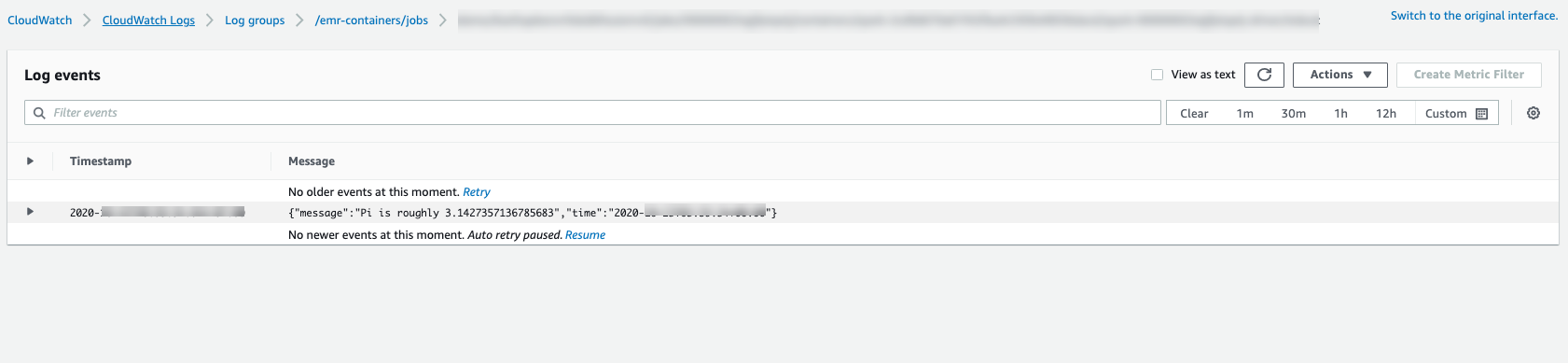
Per monitorare lo stato di avanzamento del processo o per eseguire il debug degli errori, puoi controllare i log caricati su Amazon S3, Logs o entrambi. CloudWatch Fai riferimento al percorso di log in Amazon S3 in Configure a job run per usare i log S3 e per i log di Cloudwatch in Configure a job run to use Logs. CloudWatch Per visualizzare i log in Logs, segui le istruzioni riportate di seguito. CloudWatch
-
Apri la CloudWatch console all'indirizzo. https://console.aws.amazon.com/cloudwatch/
-
Nel pannello Navigation (Navigazione), scegli Logs (Log). Quindi, scegli Log groups (Gruppi di log).
-
Scegli il gruppo di log per Amazon EMR su EKS e visualizza gli eventi di log caricati.
-
Importante
I processi hanno una policy di ripetizione configurata predefinita. Per informazioni sulla modifica o la disabilitazione della configurazione, fai riferimento a Utilizzo delle policy di ripetizione dei processi.
