Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esegui il debug di applicazioni e lavori con Studio EMR
Con Amazon EMR Studio, puoi avviare interfacce di applicazioni dati per analizzare applicazioni ed esecuzioni di processi nel browser.
Puoi anche avviare le interfacce utente persistenti e fuori dal cluster per Amazon EMR in esecuzione su EC2 cluster dalla console Amazon. EMR Per ulteriori informazioni, consulta Visualizza le interfacce utente persistenti delle applicazioni in Amazon EMR.
A seconda delle impostazioni del browser, potrebbe essere necessario abilitare i popup per l'apertura dell'interfaccia utente di un'applicazione.
Per informazioni sulla configurazione e l'utilizzo delle interfacce dell'applicazione, consulta The YARN Timeline Server, Monitoring and instrumentation o Tez UI overview.
Esegui il debug di Amazon EMR in esecuzione su Amazon jobs EC2
- Workspace UI
-
Avvio di un'interfaccia utente su cluster da un file notebook
Quando utilizzi le EMR versioni 5.33.0 e successive di Amazon, puoi avviare l'interfaccia utente web di Spark (Spark UI o Spark History Server) da un notebook nel tuo spazio di lavoro.
Sul cluster UIs funzionano con i kernel PySpark, Spark o SparkR. La dimensione massima del file visualizzabile per i log eventi o i log del container di Spark è di 10 MB. Se i file di log superano i 10 MB, si consiglia di utilizzare lo Spark History Server persistente anziché l'interfaccia utente Spark su cluster per eseguire il debug dei processi.
Affinché EMR Studio possa avviare le interfacce utente delle applicazioni on-cluster da un Workspace, un cluster deve essere in grado di comunicare con Amazon Gateway. API È necessario configurare il EMR cluster per consentire il traffico di rete in uscita verso Amazon API Gateway e assicurarsi che Amazon API Gateway sia raggiungibile dal cluster.
L'interfaccia utente Spark accede ai log del container risolvendo i nomi host. Se utilizzi un nome di dominio personalizzato, devi assicurarti che i nomi host dei nodi del cluster possano essere risolti da Amazon DNS o dal DNS server specificato. A tale scopo, imposta le opzioni Dynamic Host Configuration Protocol (DHCP) per Amazon Virtual Private Cloud (VPC) associato al tuo cluster. Per ulteriori informazioni sulle DHCP opzioni, consulta i set di DHCP opzioni nella Amazon Virtual Private Cloud User Guide.
-
Nel tuo EMR Studio, apri l'area di lavoro che desideri utilizzare e assicurati che sia collegata a un EMR cluster Amazon su EC2 cui è in esecuzione. Per istruzioni, consulta Collega un computer a uno EMR Studio Workspace.
-
Apri un file notebook e usa il kernel PySpark, Spark o SparkR. Per selezionare un kernel, scegli il nome del kernel in alto a destra della barra degli strumenti del notebook per aprire la finestra di dialogo Select Kernel (Seleziona kernel). Il nome viene visualizzato come No Kernel! (Nessun kernel!) se non è stato selezionato alcun kernel.
-
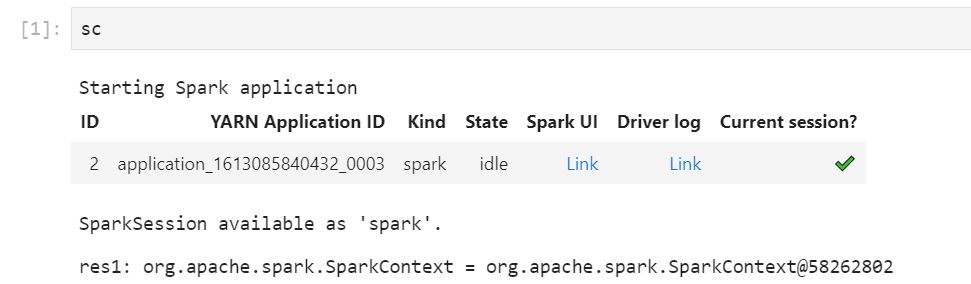
Esegui il codice del notebook. Quando avvii il contesto Spark, viene visualizzato come output nel notebook. Potrebbero essere necessari alcuni secondi prima di visualizzarlo. Se hai avviato il contesto Spark, è possibile eseguire il comando %%info per accedere a un collegamento all'interfaccia utente Spark in qualsiasi momento.
Se i collegamenti dell'interfaccia utente Spark non funzionano o non vengono visualizzati dopo alcuni secondi, crea una nuova cella del notebook ed esegui il comando %%info per rigenerare i collegamenti.
-
Per avviare l'interfaccia utente Spark, seleziona Link (Collegamento) in Spark UI (Interfaccia utente Spark). Se l'applicazione Spark è in esecuzione, l'interfaccia utente Spark si apre in una nuova scheda. Se l'applicazione è stata completata, si apre Spark History Server.
Dopo aver avviato l'interfaccia utente di Spark, puoi modificarla URL nel browser per aprire il YARN ResourceManager o lo Yarn Timeline Server. Aggiungi uno dei percorsi seguenti dopo amazonaws.com.
| Interfaccia utente Web |
Path |
Esempio modificato URL |
| YARN ResourceManager |
/rm |
https://j-examplebby5ij.emrappui-prod. eu-west-1.amazonaws.com /rm |
| Timeline Server di Yarn |
/yts |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /yts |
| Spark History Server |
/shs |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /shs
|
- Studio UI
-
Avvia il YARN Timeline Server persistente, Spark History Server o l'interfaccia utente Tez dall'interfaccia utente di Studio EMR
-
Nel tuo EMR Studio, seleziona Amazon EMR EC2 sul lato sinistro della pagina per aprire l'elenco Amazon EMR on EC2 clusters.
-
Filtra l'elenco dei cluster per name (nome), state (stato) oppure ID immettendo valori nella casella di ricerca. Puoi anche effettuare una ricerca per time range (intervallo temporale) di creazione.
-
Seleziona un cluster, quindi scegli Avvia applicazione UIs per selezionare l'interfaccia utente dell'applicazione. L'interfaccia utente dell'applicazione si apre in una nuova scheda del browser e potrebbe richiedere del tempo per il caricamento.
Debug EMR Studio in esecuzione su Serverless EMR
Analogamente ad Amazon EMR in esecuzione su AmazonEC2, puoi utilizzare l'interfaccia utente Workspace per analizzare le tue applicazioni EMR Serverless. Dall'interfaccia utente di Workspace, quando utilizzi le EMR versioni di Amazon 6.14.0 e successive, puoi avviare l'interfaccia utente web di Spark (Spark UI o Spark History Server) da un notebook nel tuo Workspace. Per comodità, forniamo anche un collegamento al log dei driver per accedere rapidamente ai log dei driver Spark.
Esegui il debug di Amazon EMR on EKS job run con Spark History Server
Quando invii un job run a un Amazon EMR on EKS cluster, puoi accedere ai log relativi a quel job eseguito utilizzando Spark History Server. Lo Spark History Server fornisce strumenti per il monitoraggio delle applicazioni Spark, come un elenco delle fasi e delle attività dello scheduler, un riepilogo delle RDD dimensioni e dell'utilizzo della memoria e informazioni ambientali. Puoi avviare Spark History Server per Amazon EMR on EKS job run nei seguenti modi:
-
Quando invii un job eseguito utilizzando EMR Studio con un Amazon EMR on EKS managed endpoint, puoi avviare Spark History Server da un file di notebook nel tuo Workspace.
-
Quando invii un lavoro eseguito utilizzando AWS CLI o AWS SDK per Amazon EMR suEKS, puoi avviare Spark History Server dall'interfaccia utente di EMR Studio.
Per informazioni su come utilizzare Spark History Server, consulta Monitoraggio e strumentazionenella documentazione di Apache Spark. Per ulteriori informazioni sulle esecuzioni dei job, consulta Concepts and components nella Amazon EMR on EKS Development Guide.
Per avviare Spark History Server da un file di notebook nel tuo spazio di lavoro di EMR Studio
-
Apri un'area di lavoro connessa a un Amazon EMR on EKS cluster.
-
Seleziona e apri il file del notebook nell'istanza WorkSpace.
-
Scegli Spark UI (Interfaccia utente Spark) nella parte superiore di un file notebook per aprire lo Spark History Server persistente in una nuova scheda.
Per avviare Spark History Server dall'interfaccia utente di Studio EMR
L'elenco dei lavori nell'interfaccia utente di EMR Studio mostra solo le esecuzioni di lavoro inviate utilizzando AWS CLI o AWS SDK per Amazon EMR suEKS.
-
Nel tuo EMR Studio, seleziona Amazon EMR EKS sul lato sinistro della pagina.
-
Cerca il cluster Amazon EMR on EKS virtual che hai usato per inviare il job run. Puoi filtrare l'elenco dei cluster per status (stato) o ID immettendo valori nella casella di ricerca.
-
Seleziona il cluster per aprire la relativa pagina dei dettagli. Nella pagina dei dettagli vengono visualizzate informazioni sul cluster, ad esempio ID, spazio dei nomi e stato. La pagina mostra anche un elenco di tutti i processi eseguiti inviati a quel cluster.
-
Dalla pagina dei dettagli del cluster, seleziona un processo da sottoporre a debug.
-
In alto a destra dell'elenco Jobs (Processi), seleziona Launch Spark History Server (Avvia Spark History Server) per aprire l'interfaccia dell'applicazione in una nuova scheda del browser.