Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migliora i kernel con magic i comandi in EMR Studio
Panoramica
EMR Studio ed EMR Notebooks supportano i comandi. magic Magici comandi, o magics, sono miglioramenti forniti dal IPython kernel per aiutarti a eseguire e analizzare i dati. IPythonè un ambiente shell interattivo creato con Python.
Amazon EMR supporta Sparkmagic anche un pacchetto che fornisce comandi magic specifici ai kernel relativi a Spark (PySpark, SparkR e Scala) e che utilizza Livy sul cluster per inviare lavori Spark.
È possibile utilizzare i comandi magic purché si disponga di un kernel Python nel notebook EMR. Analogamente, qualsiasi kernel relativo a Spark supporta i comandi Sparkmagic.
Comandi Magic, chiamati anche magic, sono disponibili in due varietà:
-
Line magic: questi comandi magic sono denotati da un singolo prefisso
%e funzionano su una singola riga di codice -
Cell magic: questi comandi magic sono indicati con un doppio prefisso
%%e funzionano su più righe di codice
Per tutti i magic disponibili, consulta Elenco magic e comandi Sparkmagic.
Considerazioni e limitazioni
-
EMR Serverless non supporta il
%%shper eseguirespark-submit. Non supporta i magic di EMR Notebooks. -
I cluster Amazon EMR su EKS non supportano i comandi Sparkmagic per EMR Studio. Questo perché i kernel Spark utilizzati con gli endpoint gestiti sono integrati in Kubernetes e non sono supportati da Sparkmagic e Livy. È possibile impostare la configurazione Spark direttamente nell' SparkContext oggetto come soluzione alternativa, come dimostra l'esempio seguente.
spark.conf.set("spark.driver.maxResultSize", '6g') -
I seguenti magic comandi e azioni sono proibiti da: AWS
-
%alias -
%alias_magic -
%automagic -
%macro -
Modifica
proxy_usercon%configure -
Modifica
KERNEL_USERNAMEcon%envo%set_env
-
Elenco magic e comandi Sparkmagic
Utilizza i comandi seguenti per visualizzare un elenco di tutti i comandi magic disponibili:
-
%lsmagicelenca tutte le funzioni magic attualmente disponibili. -
%%helpelenca le funzioni magic attualmente disponibili su Spark fornite dal pacchetto Sparkmagic.
Utilizza %%configure per configurare Spark
Uno dei comandi Sparkmagic più utili è il comando %%configure, che configura i parametri di creazione della sessione. Utilizzando le impostazioni conf, è possibile configurare qualsiasi configurazione Spark menzionata nella documentazione di configurazione di Apache Spark
Esempio Aggiungi un file JAR esterno ai EMR Notebooks dal repository Maven o da Amazon S3
È possibile utilizzare il seguente approccio per aggiungere una dipendenza da file JAR esterno a qualsiasi kernel relativo a Spark supportato da Sparkmagic.
%%configure -f {"conf": { "spark.jars.packages": "com.jsuereth:scala-arm_2.11:2.0,ml.combust.bundle:bundle-ml_2.11:0.13.0,com.databricks:dbutils-api_2.11:0.0.3", "spark.jars": "s3://amzn-s3-demo-bucket/my-jar.jar" } }
Esempio : Configura Hudi
È quindi possibile utilizzare l'editor del notebook per configurare EMR Notebooks per l'utilizzo di Hudi.
%%configure { "conf": { "spark.jars": "hdfs://apps/hudi/lib/hudi-spark-bundle.jar,hdfs:///apps/hudi/lib/spark-spark-avro.jar", "spark.serializer": "org.apache.spark.serializer.KryoSerializer", "spark.sql.hive.convertMetastoreParquet":"false" } }
Utilizza %%sh per eseguire spark-submit
Il %%sh magic esegue comandi shell (interprete di comandi) in un sottoprocesso su un'istanza del cluster collegato. In genere, si utilizza uno dei kernel relativi a Spark per eseguire applicazioni Spark sul cluster collegato. Tuttavia, se si desidera utilizzare un kernel Python per inviare un'applicazione Spark, è possibile utilizzare la seguente magic, sostituendo il nome del bucket con il nome del bucket in minuscolo.
%%sh spark-submit --master yarn --deploy-mode cluster s3://amzn-s3-demo-bucket/test.py
In questo esempio, il cluster deve accedere alla posizione di s3:// o il comando avrà esito negativo.amzn-s3-demo-bucket/test.py
È possibile utilizzare qualsiasi comando Linux con %%sh magic. Per eseguire qualsiasi comando Spark o YARN, utilizza una delle seguenti opzioni per creare un Utente Hadoop emr-notebook e concedi all'utente le autorizzazioni per eseguire i comandi:
-
Puoi creare esplicitamente un nuovo utente eseguendo i seguenti comandi.
hadoop fs -mkdir /user/emr-notebook hadoop fs -chown emr-notebook /user/emr-notebook -
Puoi attivare la rappresentazione dell'utente in Livy, che crea automaticamente l'utente. Per ulteriori informazioni, consulta Abilitazione della rappresentazione utente per monitorare l'attività dell'utente e dei processi Spark.
Utilizza %%display per visualizzare i dataframe Spark
Puoi usare %%display magic per visualizzare un dataframe Spark. Per usare questo magic, eseguire il seguente comando.
%%display df
Scegli di visualizzare i risultati in formato tabella, come illustrato nell'immagine seguente.
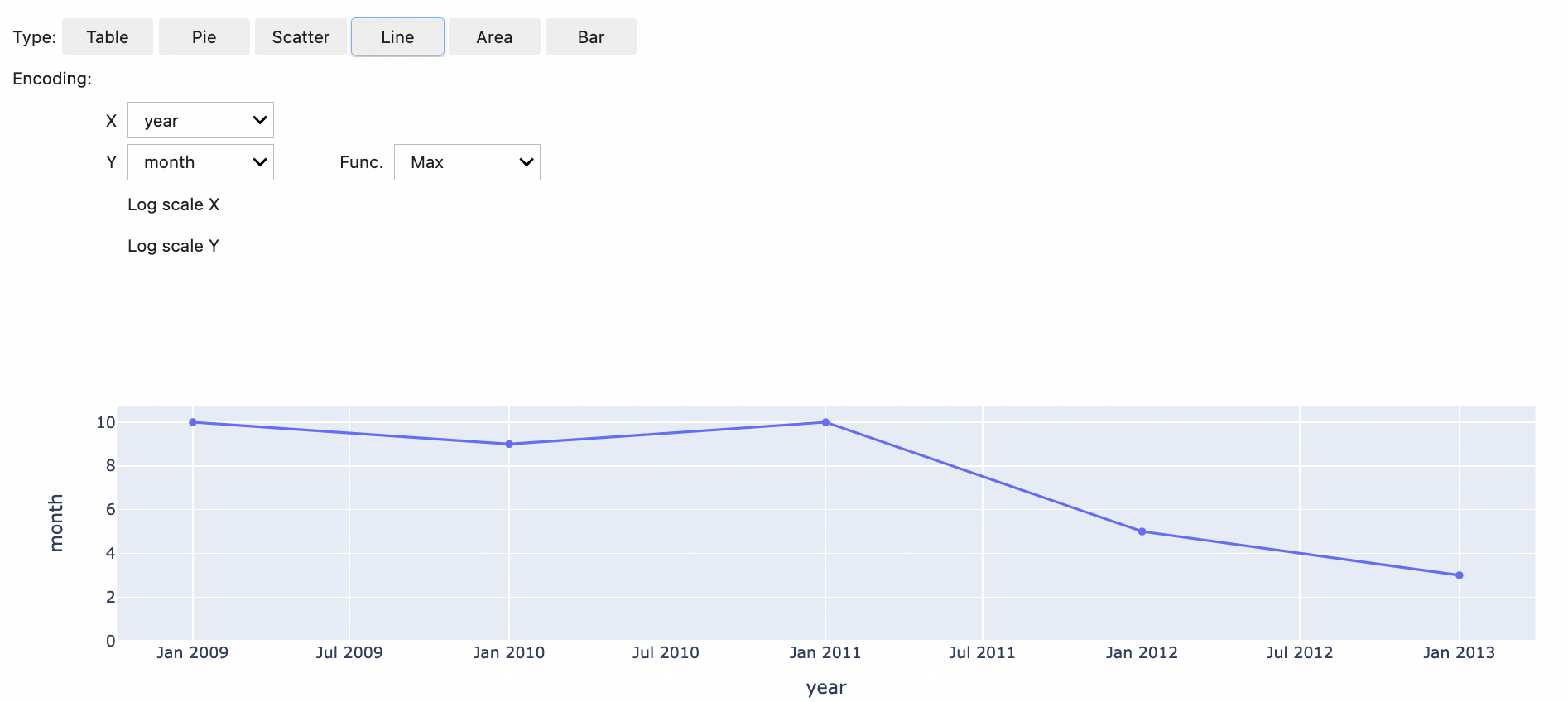
È inoltre possibile scegliere di visualizzare i dati con cinque tipi di grafici. Le opzioni includono grafici a torta, a dispersione, a linee, ad area e a barre.
Utilizza i magic di EMR Notebooks
Amazon EMR fornisce i seguenti magic di EMR Notebooks che possono essere utilizzati con i kernel basati su Python3 e Spark:
-
%mount_workspace_dir- Monta la directory WorkSpace sul cluster in modo da poter importare ed eseguire codice da altri file nel WorkSpaceNota
con
%mount_workspace_dir, solo il kernel Python 3 può accedere ai file system locali. Gli executor Spark non avranno accesso alla directory montata con questo kernel. -
%umount_workspace_dir- Smonta la directory WorkSpace dal cluster -
%generate_s3_download_url- Genera un link per il download temporaneo nell'output del notebook per un oggetto Amazon S3
Prerequisiti
Prima di installare i magic di EMR Notebooks, completare i seguenti processi:
-
Assicurarsi che il proprio Ruolo di servizio per le istanze del cluster (profilo EC2 dell'istanza) EC2 disponga dell'accesso in lettura per Amazon S3. Il
EMR_EC2_DefaultRolecon la policy gestitaAmazonElasticMapReduceforEC2Rolesoddisfa questo requisito. Se si utilizza un ruolo o una policy personalizzati, assicurarsi che dispongano delle autorizzazioni S3 necessarie.Nota
magicEMR Notebooks viene eseguito su un cluster come utente del notebook e EC2 utilizza il profilo dell'istanza per interagire con Amazon S3. Quando si monta una directory WorkSpace su un cluster EMR, tutti i notebook WorkSpace e EMR con il permesso di collegarsi a tale cluster possono accedere alla directory montata.
Le directory sono montate in sola lettura per impostazione predefinita. Mentre
s3fs-fuseegoofyspermettono il supporto in lettura-scrittura, consigliamo vivamente di non modificare i parametri di montaggio per montare le directory in modalità di lettura-scrittura. Se si permette l'accesso in scrittura, le modifiche apportate alla directory vengono scritte nel bucket S3. Per evitare l'eliminazione o la sovrascrittura accidentale, è possibile abilitare il controllo delle versioni per il bucket S3. Per ulteriori informazioni, consulta Utilizzo della funzione controllo delle versioni nei bucket S3. -
Eseguire uno dei seguenti script sul cluster per installare le dipendenze per i magic di EMR Notebooks. Per eseguire uno script, è possibile eseguire Utilizzo di operazioni di bootstrap personalizzate oppure segui le istruzioni in Run commands and scripts on an Amazon EMR cluster (Esegui comandi e script su un cluster Amazon EMR) quando si dispone già di un cluster in esecuzione.
È possibile scegliere quale dipendenza installare. Entrambi s3fs-fuse
e goofys sono strumenti FUSE (Filesystem in Userspace) che consentono di montare un bucket Amazon S3 come file system locale su un cluster. Lo strumento s3fsoffre un'esperienza simile a POSIX. Lo strumentogoofysè una buona scelta quando si preferiscono le prestazioni rispetto a un file system conforme a POSIX.La serie Amazon EMR 7.x utilizza Amazon Linux 2023, che non supporta i repository EPEL. Se utilizzi Amazon EMR 7.x, segui le istruzioni di s3fs-fuse per l'installazione GitHub
. s3fs-fuseSe usi la serie 5.x o 6.x, usa i seguenti comandi per l'installazione.s3fs-fuse#!/bin/sh # Install the s3fs dependency for EMR Notebooks magics sudo amazon-linux-extras install epel -y sudo yum install s3fs-fuse -yOPPURE
#!/bin/sh # Install the goofys dependency for EMR Notebooks magics sudo wget https://github.com/kahing/goofys/releases/latest/download/goofys -P /usr/bin/ sudo chmod ugo+x /usr/bin/goofys
Installare i magic di EMR Notebooks
Nota
Con i rilasci di Amazon EMR da 6.0 a 6.9.0 e da 5.0 a 5.36.0, solo il pacchetto emr-notebooks-magics versione 0.2.0 e successive supporta %mount_workspace_dir magic.
Per installare i magic di EMR Notebooks, completare i seguenti passaggi.
-
Nel notebook, esegui i comandi seguenti per installare il pacchetto
emr-notebooks-magics. %pip install boto3 --upgrade %pip install botocore --upgrade %pip install emr-notebooks-magics --upgrade -
Riavviare il kernel per caricare i magic di EMR Notebooks.
-
Verificare l'installazione con il seguente comando, che dovrebbe visualizzare il testo della guida di output per
%mount_workspace_dir.%mount_workspace_dir?
Montare una directory WorkSpace con %mount_workspace_dir
Il %mount_workspace_dir magic consente di montare la directory WorkSpace sul cluster EMR in modo da poter importare ed eseguire altri file, moduli o pacchetti archiviati nella directory.
L'esempio seguente monta l'intera directory di WorkSpace su un cluster e specifica l'argomento opzionale <--fuse-type>
%mount_workspace_dir .<--fuse-type goofys>
Per verificare che la directory WorkSpace sia montata, utilizzare l'esempio seguente per visualizzare l'attuale directory di lavoro con il comando ls. L'output dovrebbe visualizzare tutti i file nel WorkSpace.
%%sh ls
Una volta che sono state apportate le modifiche nel WorkSpace, puoi smontare la directory del WorkSpace con il seguente comando:
Nota
La directory WorkSpace rimane montata sul cluster anche quando il WorkSpace viene arrestato o distaccato. È necessario smontare esplicitamente la directory di WorkSpace.
%umount_workspace_dir
Scaricare un oggetto Amazon S3 con %generate_s3_download_url
Il comando generate_s3_download_url crea un URL prefirmato per un oggetto archiviato in Amazon S3. È possibile utilizzare l'URL preimpostato per scaricare l'oggetto sul computer locale. Ad esempio si potrebbe eseguire generate_s3_download_url per scaricare il risultato di una query SQL che il codice scrive su Amazon S3.
L'URL prefirmato è valido per 60 minuti per impostazione predefinita. È possibile modificare il tempo di scadenza specificando un numero di secondi per il flag --expires-in. Ad esempio, --expires-in 1800 crea un URL valido per 30 minuti.
L'esempio seguente genera un collegamento per il download di un oggetto specificando il percorso completo di Amazon S3: s3://EXAMPLE-DOC-BUCKET/path/to/my/object
%generate_s3_download_urls3://EXAMPLE-DOC-BUCKET/path/to/my/object
Per ulteriori informazioni sull'uso di generate_s3_download_url, eseguire il comando di seguito per visualizzare il testo della guida.
%generate_s3_download_url?
Gestione di un notebook in modalità headless con %execute_notebook
Con %execute_notebook magic, puoi eseguire un altro notebook in modalità headless e visualizzare l'output di ogni cella che hai utilizzato. Ciò magic richiede autorizzazioni aggiuntive per il ruolo dell'istanza condiviso da Amazon EMR e Amazon EC2 . Per ulteriori dettagli su come concedere autorizzazioni aggiuntive, esegui il comando %execute_notebook?.
Durante un processo di lunga durata, il sistema potrebbe andare in modalità di sospensione a causa dell'inattività o perdere temporaneamente la connettività Internet. Ciò potrebbe interrompere la connessione tra il browser e il server Jupyter. In questo caso, potresti perdere l'output delle celle che hai eseguito e inviato dal server Jupyter.
Se utilizzi il notebook in modalità headless con %execute_notebook magic, EMR Notebooks acquisisce l'output dalle celle che hai eseguito, anche in caso di interruzione della rete locale. EMR Notebooks salva l'output in modo incrementale in un nuovo notebook con lo stesso nome del notebook che hai utilizzato. EMR Notebooks inserisce quindi il notebook in una nuova cartella all'interno del workspace. Le esecuzioni headless avvengono sullo stesso cluster e utilizzano il ruolo di servizio EMR_Notebook_DefaultRole, ma argomenti aggiuntivi possono modificare i valori predefiniti.
Per eseguire un notebook in modalità headless, usa il seguente comando:
%execute_notebook<relative-file-path>
Per specificare un ID cluster e il ruolo di servizio per un'esecuzione headless, usa il seguente comando:
%execute_notebook<notebook_name>.ipynb --cluster-id <emr-cluster-id> --service-role <emr-notebook-service-role>
Quando Amazon EMR e Amazon EC2 condividono un ruolo di istanza, il ruolo richiede le seguenti autorizzazioni aggiuntive:
Nota
Per utilizzare %execute_notebook magic, installa il pacchetto emr-notebooks-magics, versione 0.2.3 o successive.
