Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
HBase su Amazon S3 (modalità di storage Amazon S3)
Se utilizzi Amazon EMR versione 5.2.0 o successiva, puoi abilitarlo HBase su Amazon HBase S3, che offre i seguenti vantaggi:
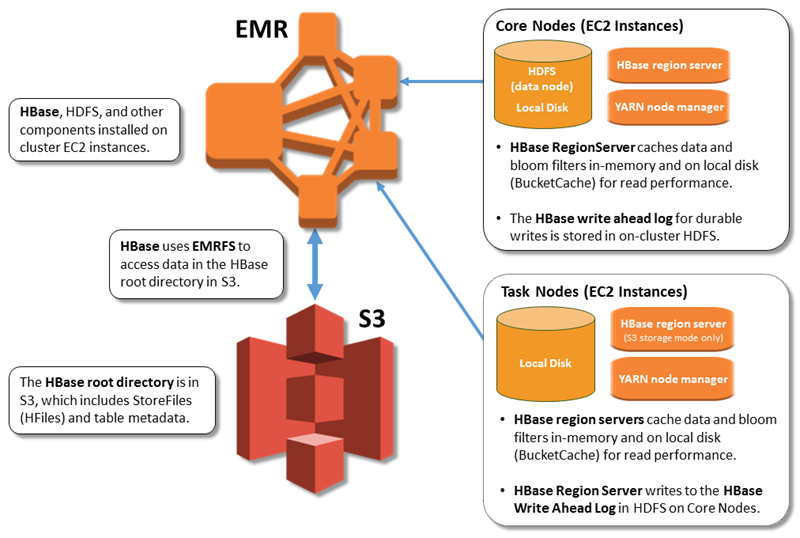
La directory HBase principale è archiviata in Amazon S3, inclusi i file di HBase archivio e i metadati delle tabelle. Questi dati sono persistenti all'esterno del cluster, disponibili in tutte le zone di EC2 disponibilità di Amazon e non è necessario ripristinarli utilizzando snapshot o altri metodi.
Con i file dello store in Amazon S3 puoi dimensionare il cluster Amazon EMR per i tuoi requisiti di calcolo anziché i requisiti dei dati, con replica 3x in HDFS.
Utilizzando Amazon EMR versione 5.7.0 o successive, puoi impostare una replica di lettura al cluster, che consente di mantenere copie di sola lettura dei dati in Amazon S3. Puoi accedere ai dati dalla replica di lettura al cluster per eseguire operazioni di lettura simultaneamente e nel caso in cui il cluster principale diventi indisponibile.
Nelle versioni di Amazon EMR da 6.2.0 a 7.3.0, il HFile monitoraggio persistente utilizza una tabella di HBase sistema chiamata
hbase:storefileper tracciare direttamente i HFile percorsi utilizzati per le operazioni di lettura. Questa caratteristica è abilitata per impostazione predefinita e non richiede la migrazione manuale. Nelle versioni successive alla 7.3.0, HFile i percorsi vengono tracciati utilizzando un file tracker, che archivia i HFile percorsi direttamente in un meta file, all'interno della directory store.
Nota
Gli utenti che utilizzano una versione di Amazon EMR precedente alla 7.4.0 e stanno migrando a EMR-7.4.0 e versioni successive, consultano Migrazione da HBase versioni precedenti e seguono la documentazione di aggiornamento disponibile per garantire una transizione senza intoppi.
La seguente illustrazione mostra i HBase componenti rilevanti per HBase Amazon S3.
Abilitazione HBase su Amazon S3
Puoi abilitarlo HBase su Amazon S3 utilizzando la console Amazon EMR, AWS CLI o l'API Amazon EMR. La configurazione è un'opzione durante la creazione del cluster. Quando utilizzi la console, puoi scegliere l'impostazione utilizzando Advanced options (Opzioni avanzate). Quando utilizzi AWS CLI, utilizza l'opzione --configurations per fornire un oggetto di configurazione JSON. Le proprietà dell'oggetto di configurazione specificano la modalità di archiviazione e il percorso della directory principale in Amazon S3. Il percorso Amazon S3 specificato deve trovarsi nella stessa regione del cluster Amazon EMR. Solo un cluster attivo alla volta può utilizzare la stessa directory HBase principale in Amazon S3. Per i passaggi della console e un esempio dettagliato di creazione di cluster utilizzando il AWS CLI, consulta. Creazione di un cluster con HBase Un esempio di oggetto di configurazione è mostrato nel seguente snippet JSON.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
Nota
Se utilizzi un bucket Amazon S3 come modulo HBase, devi aggiungere una barra alla fine dell'URI Amazon S3. rootdir Per evitare problemi occorre utilizzare, ad esempio, "hbase.rootdir: s3://amzn-s3-demo-bucket/" anziché "hbase.rootdir: s3://amzn-s3-demo-bucket".
Utilizzo della replica di lettura al cluster
Dopo aver configurato un cluster primario utilizzando HBase Amazon S3, puoi creare e configurare un cluster di replica in lettura che fornisce accesso in sola lettura agli stessi dati del cluster primario. Ciò è utile quando è necessario accesso simultaneo per eseguire query sui dati o accesso ininterrotto se il cluster principale diventa non disponibile. La funzione replica di lettura è disponibile con Amazon EMR versione 5.7.0 e successive.
Il cluster principale e la replica di lettura al cluster vengono impostati nello stesso modo con una differenza importante. Entrambi fanno riferimento allo stesso percorso hbase.rootdir. Tuttavia, la classificazione hbase per la replica di lettura al cluster include la proprietà "hbase.emr.readreplica.enabled":"true".
Il cluster di replica di lettura è progettato per operazioni di sola lettura e non deve essere eseguita alcuna azione manuale di compattazione o scrittura su di esso. Per le versioni di Amazon EMR precedenti alla 7.4.0, si consiglia di disabilitare la compattazione sul cluster di lettura-replica quando si abilita la funzionalità di lettura-replica. Questa precauzione è necessaria perché, con la funzionalità di HFile tracciamento persistente abilitata sul cluster primario, è possibile che il cluster di lettura-replica compatti le tabelle di sistema, causando potenzialmente un problema nel cluster primario. FileNotFoundException La disabilitazione della compattazione sul cluster di lettura e replica impedisce le incongruenze dei dati tra il cluster primario e quello di replica di lettura.
Ad esempio, data la classificazione JSON per il cluster primario illustrata in precedenza nell'argomento, la configurazione per un cluster di replica in lettura per le versioni EMR precedenti alla 7.4.0 è la seguente:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
Per le versioni di Amazon EMR successive alla 7.3.0, ora utilizziamo la Monitoraggio dei file di archiviazione funzionalità, quindi non è necessario disabilitare le compattazioni.
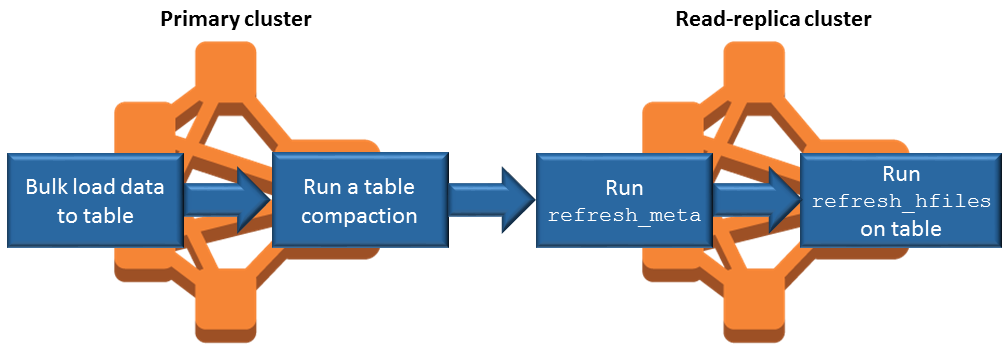
Sincronizzazione della replica di lettura quando si aggiungono dati
Poiché la replica di lettura utilizza i HBase StoreFiles metadati che il cluster primario scrive su Amazon S3, la replica di lettura è aggiornata solo quanto il data store Amazon S3. Le seguenti indicazioni consentono di ridurre il ritardo tra il cluster principale e la replica di lettura durante la scrittura dei dati.
Se possibile, caricare i dati in blocco nel cluster principale. Per ulteriori informazioni, consulta la documentazione relativa al caricamento in blocco di Apache.
HBase Dopo che i dati vengono aggiunti, i file dello store devono essere scritti al più presto in Amazon S3 mediante uno svuotamento. Eseguire lo svuotamento manualmente o ottimizzare le impostazioni di svuotamento per ridurre il ritardo.
Se è possibile che vengano eseguite compattazioni automatiche, eseguire una compattazione manuale per evitare incoerenze quando le compattazioni vengono attivate.
Nel cluster read-replica, quando i metadati sono cambiati, ad esempio quando si verificano divisioni o compattazioni di HBase regioni o quando vengono aggiunte o rimosse tabelle, esegui il comando.
refresh_metaNella replica di lettura al cluster, eseguire il comando
refresh_hfilesquando si aggiungono o modificano record in una tabella.
HFile Monitoraggio persistente
Il HFile tracciamento persistente utilizza una tabella di HBase sistema chiamata hbase:storefile per tracciare direttamente i HFile percorsi utilizzati per le operazioni di lettura. I nuovi HFile percorsi vengono aggiunti alla tabella man mano che vengono aggiunti dati aggiuntivi HBase. Ciò rimuove le operazioni di ridenominazione come meccanismo di commit nelle HBase operazioni critiche relative ai percorsi di scrittura e migliora i tempi di ripristino all'apertura di una HBase regione mediante la lettura dalla tabella di hbase:storefile sistema anziché dall'elenco delle directory del file system. Questa funzionalità è abilitata per impostazione predefinita nelle versioni di Amazon EMR da 6.2.0 a 7.3.0 e non richiede alcuna procedura di migrazione manuale.
Nota
Il HFile tracciamento persistente tramite la tabella HBase dello storefile system non supporta la funzionalità di replica regionale. HBase Per ulteriori informazioni sulla replica delle aree, consulta HBase Timeline-Consistent
HFile Disattivazione del tracciamento persistente
Il HFile tracciamento persistente è abilitato per impostazione predefinita a partire dalla release 6.2.0 di Amazon EMR. Per disabilitare il HFile tracciamento persistente, specifica la seguente modifica della configurazione all'avvio di un cluster:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
Nota
Durante la riconfigurazione del cluster Amazon EMR, tutti i gruppi di istanze devono essere aggiornati.
Sincronizzazione manuale della tabella Storefile
La tabella storefile viene mantenuta aggiornata man mano che vengono create nuove HFile istanze. Tuttavia, se la tabella storefile non è sincronizzata con i file di dati per qualsiasi motivo, è possibile utilizzare i comandi seguenti per sincronizzare manualmente i dati:
Sincronizza la tabella Storefile in una regione online:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Sincronizza la tabella Storefile in una regione offline:
Rimuove lo znode della tabella Storefile.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Assegna la regione (da eseguire in "hbase shell").
hbase cli> assign '<region name>'Se l'assegnazione ha esito negativo.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Ridimensionamento della tabella Storefile
La tabella Storefile è suddivisa in quattro regioni per impostazione predefinita. Se la tabella Storefile presenta ancora un'ingente mole di scrittura, può essere ulteriormente divisa in modalità manuale.
Per dividere una regione critica specifica, utilizza il seguente comando (da eseguire in "hbase shell").
hbase cli> split '<region name>'
Per dividere la tabella, utilizza il seguente comando (da eseguire in "hbase shell").
hbase cli> split 'hbase:storefile'
Monitoraggio dei file di archiviazione
Per impostazione predefinita, utilizziamo l'FileBasedStoreFileTrackerimplementazione. Questa implementazione crea nuovi file direttamente nella directory dell'archivio, evitando la necessità di operazioni di ridenominazione. Mantiene in memoria un elenco di istanze hfile impegnate, supportato da meta file in ogni directory di archivio. Ogni volta che viene eseguito il commit di un nuovo hfile, l'elenco dei file tracciati nell'archivio specificato viene aggiornato e viene scritto un nuovo metafile con il contenuto dell'elenco e scartando il metafile precedente, che contiene un elenco obsoleto. Ulteriori informazioni su Store File Tracking sono disponibili su Store File Tracking nella guida di riferimento
L'implementazione del FileBasedStoreFile tracker è abilitata per impostazione predefinita, a partire dalla versione 7.4.0 di Amazon EMR:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
Per disabilitare l' FileBasedStoreFileTracker implementazione, specifica la seguente modifica della configurazione all'avvio di un cluster:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
Nota
Durante la riconfigurazione del cluster Amazon EMR, tutti i gruppi di istanze devono essere aggiornati.
Considerazioni operative
HBase i server regionali vengono utilizzati BlockCache per archiviare le letture dei dati in memoria e BucketCache per archiviare le letture dei dati sul disco locale. Inoltre, i server regionali archiviano MemStore i dati scritti in memoria e utilizzano i log write-ahead per archiviare le scritture dei dati in HDFS prima che i dati vengano scritti in Amazon S3. HBase StoreFiles Le prestazioni di lettura del cluster fanno riferimento alla frequenza con cui un record può essere recuperato dalle cache in memoria o su disco. Un errore nella cache comporta la lettura del record da Amazon S3, che ha una latenza e una deviazione standard significativamente più elevate rispetto alla lettura da HDFS. StoreFile Inoltre, le frequenze di richiesta massime per Amazon S3 sono inferiori rispetto a quelle che possono essere ottenute dalla cache locale, pertanto il caching dei dati può essere importante per i carichi di lavoro gravosi in lettura. Per maggiori informazioni sulle prestazioni di Amazon S3, consulta la sezione Ottimizzazione delle prestazioni nella Guida per l'utente di Amazon Simple Storage Service.
Per migliorare le prestazioni, consigliamo di memorizzare nella cache la maggior parte possibile del set di dati nello storage delle istanze. EC2 Poiché BucketCache utilizza lo storage di EC2 istanze del server regionale, puoi scegliere un tipo di EC2 istanza con un instance store sufficiente e aggiungere lo storage Amazon EBS per soddisfare le dimensioni della cache richieste. Puoi anche aumentare le BucketCache dimensioni degli store di istanze e dei volumi EBS collegati utilizzando la hbase.bucketcache.size proprietà. L'impostazione predefinita è 8192 MB.
Per quanto riguarda le scritture, la frequenza dei MemStore flush e il numero di StoreFiles presenze durante le compattazioni minori e maggiori possono contribuire in modo significativo all'aumento dei tempi di risposta dei Region Server. Per prestazioni ottimali, prendete in considerazione l'aumento delle dimensioni del moltiplicatore di MemStore flush e HRegion block, che aumenta il tempo trascorso tra le compattazioni principali, ma aumenta anche il ritardo di coerenza se utilizzate una replica di lettura. In alcuni casi, è possibile migliorare le prestazioni utilizzando dimensioni dei blocchi di file più grandi (ma inferiori a 5 GB) per attivare la funzionalità di caricamento in più parti Amazon S3 in EMRFS. La dimensione predefinita del blocco di Amazon EMR è 128 MB. Per ulteriori informazioni, consulta Configurazione HDFS. Raramente vediamo clienti che superano le dimensioni dei blocchi da 1 GB mentre eseguono il benchmarking delle prestazioni con scarichi e compattazioni. Inoltre, le HBase compattazioni e i server regionali funzionano in modo ottimale quando è necessario compattarne un numero inferiore. StoreFiles
Il rilascio delle tabelle su Amazon S3 può richiedere molto tempo perché è necessario rinominare directory di grandi dimensioni. Valuta se disabilitare le tabelle anziché rilasciarle.
Esiste un processo HBase più pulito che pulisce i vecchi file WAL e archivia i file. Con Amazon EMR versione 5.17.0 e successive, il processo di eliminazione è abilitato a livello globale e le seguenti proprietà di configurazione possono essere utilizzate per controllare il comportamento di tale processo.
| Proprietà di configurazione | Valore predefinito | Descrizione |
|---|---|---|
|
|
1 |
Il numero di thread assegnati a clean è scaduto elevato. HFiles |
|
|
1 |
Il numero di thread assegnati a clean è scaduto. HFiles |
|
|
Impostato su un quarto di tutti i core disponibili. |
Il numero di thread per scansionare le vecchie directory. WALs |
|
|
2 |
Il numero di thread da pulire nella vecchia WALs directory. WALs |
Con Amazon EMR versione 5.17.0 e precedenti, l'operazione del processo di eliminazione può influenzare le prestazioni delle query durante l'esecuzione di carichi di lavoro gravosi, pertanto ti consigliamo di abilitare il processo di eliminazione solo durante gli orari non di punta. Il pulitore ha i seguenti comandi di HBase shell:
cleaner_chore_enabledesegue la query se il processo di pulitura è abilitato.cleaner_chore_runesegue manualmente il processo di pulitura per rimuovere file.cleaner_chore_switchabilita o disabilita il processo di pulitura e restituisce lo stato precedente del processo di pulitura. Ad esempio,cleaner_chore_switch trueabilita il processo di pulitura.
Proprietà per l' HBase ottimizzazione delle prestazioni su Amazon S3
I seguenti parametri possono essere regolati per ottimizzare le prestazioni del carico di lavoro quando lo utilizzi HBase su Amazon S3.
| Proprietà di configurazione | Valore predefinito | Descrizione |
|---|---|---|
|
|
8,192 |
La quantità di spazio su disco, in MB, riservata agli archivi di EC2 istanze Amazon del server regionale e ai volumi EBS per BucketCache lo storage. L'impostazione si applica a tutte le istanze del server della regione. BucketCache Dimensioni più grandi in genere corrispondono a prestazioni migliori |
|
|
134217728 |
Il limite di dati, in byte, in corrispondenza del quale viene attivato uno svuotamento memstore in Amazon S3. |
|
|
4 |
Un moltiplicatore che determina il limite MemStore superiore al quale gli aggiornamenti vengono bloccati. Se il MemStore superamento viene |
|
|
10 |
Il numero massimo di questi dati può esistere in un negozio prima StoreFiles che gli aggiornamenti vengano bloccati. |
|
|
10737418240 |
Le dimensioni massime di una regione prima che venga divisa. |
Chiusura e ripristino di un cluster senza perdita di dati
Per chiudere un cluster Amazon EMR senza perdere dati che non sono stati scritti su Amazon S3, è necessario svuotare la cache su Amazon S3 MemStore per scrivere nuovi file di archiviazione. In primo luogo, dovrai disabilitare tutte le tabelle. La seguente configurazione di fase può essere utilizzata quando si aggiunge una fase al cluster. Per ulteriori informazioni, consulta Utilizzo di fasi mediante la AWS CLI e la console nella Guida alla gestione di Amazon EMR.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
In alternativa, puoi eseguire direttamente il seguente comando bash.
bash /usr/lib/hbase/bin/disable_all_tables.sh
Dopo aver disabilitato tutte le tabelle, svuota la hbase:meta tabella usando la shell e il HBase seguente comando.
flush 'hbase:meta'
Quindi, puoi eseguire uno script di shell fornito sul cluster Amazon EMR per svuotare la cache. MemStore Puoi aggiungerlo come una fase o eseguirlo direttamente utilizzando la AWS CLI sul cluster. Lo script disabilita tutte le HBase tabelle, il che fa sì che il MemStore server di ogni regione venga trasferito ad Amazon S3. Se lo script viene completato correttamente, i dati vengono mantenuti in Amazon S3 e il cluster può essere terminato.
Per riavviare un cluster con gli stessi HBase dati, specifica la stessa posizione Amazon S3 del cluster precedente nella proprietà di configurazione AWS Management Console o utilizzando la proprietà di hbase.rootdir configurazione.
