Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Autoscaler Flink
Panoramica
Le versioni 6.15.0 e successive di Amazon EMR supportano l'autoscaler di Flink. La funzionalità di autoscaler dei processi raccoglie i parametri relativi all'esecuzione dei processi di streaming Flink e dimensiona automaticamente i singoli vertici di lavoro. Questo riduce la contropressione e soddisfa l'obiettivo di utilizzo impostato.
Per ulteriori informazioni, consulta la sezione Autoscaler
Considerazioni
-
L'autoscaler di Flink è supportato dalle versioni 6.15.0 e successive di Amazon EMR.
-
L'autoscaler Flink è supportato solo per i processi di streaming.
-
È supportato solo il pianificatore adattivo. Il pianificatore predefinito non è supportato.
-
Per consentire la fornitura dinamica di risorse, raccomandiamo di abilitare il dimensionamento dei cluster. La scalabilità gestita di Amazon EMR è preferita perché la valutazione dei parametri avviene ogni 5-10 secondi. A questo intervallo, il cluster può adattarsi più facilmente alla modifica delle risorse del cluster richieste.
Abilita autoscaler
Utilizza i seguenti passaggi per abilitare l'autoscaler Flink quando crei un Amazon EMR su cluster. EC2
-
Crea un nuovo cluster EMR nella console Amazon EMR:
-
Scegli la versione
emr-6.15.0o una successiva di Amazon EMR. Seleziona il bundle di applicazioni Flink e poi tutte le altre applicazioni che potresti voler includere nel tuo cluster.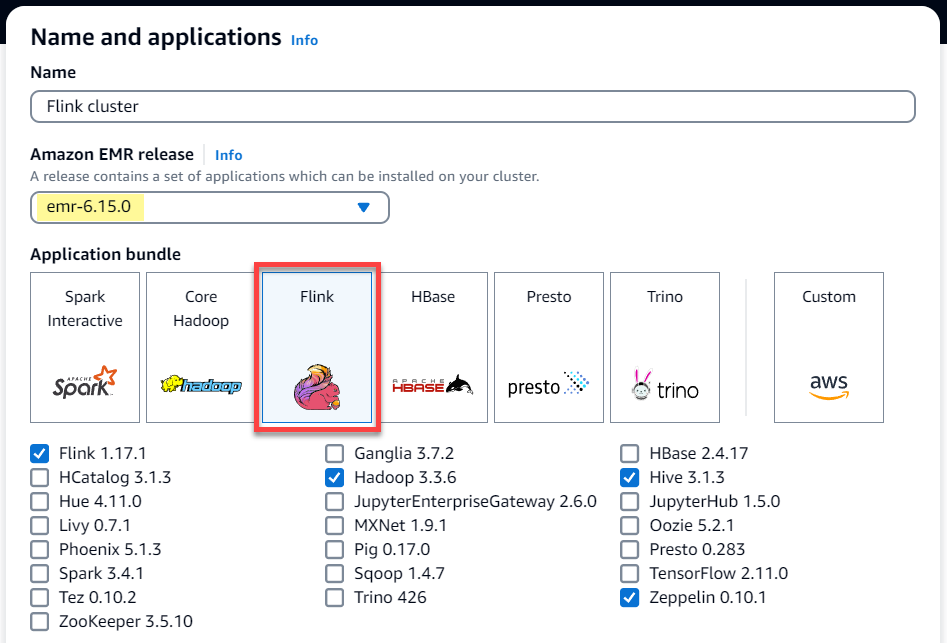
-
Nell'opzione Dimensionamento e provisioning del cluster, scegli Utilizza il dimensionamento gestito da EMR.

-
-
Nella sezione Impostazioni software, inserisci la seguente configurazione per abilitare l'autoscaler Flink. Nel caso dei test, imposta l'intervallo di decisione, l'intervallo della finestra dei parametri e l'intervallo di stabilizzazione su un valore inferiore in modo che il processo prenda immediatamente una decisione sul dimensionamento per eseguire una verifica più semplice.
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
Seleziona o configura qualsiasi altra impostazione come preferisci e crea il cluster abilitato per autoscaler Flink.
Configurazioni di autoscaler
Questa sezione copre la maggior parte delle configurazioni che puoi modificare in base alle tue esigenze specifiche.
Nota
Con configurazioni basate sul tempo come le impostazioni time, interval e window, l'unità predefinita quando non ne viene specificata una in particolare è i millisecondi. Quindi un valore di 30 senza suffisso equivale a 30 millisecondi. Per altre unità di tempo, includi il suffisso appropriato di s per secondi, m per minuti o h per ore.
Argomenti
Configurazioni dei loop di autoscaler
Autoscaler recupera i parametri a livello di vertice del lavoro per ogni intervallo di tempo configurabile, li converte in elementi utilizzabili su vasta scala, stima il nuovo parallelismo dei vertici del lavoro e lo consiglia al pianificatore di processi. I parametri vengono raccolti solo dopo l'ora di riavvio del processo e l'intervallo di stabilizzazione del cluster.
| Chiave di configurazione | Valore predefinito | Descrizione | Valori di esempio |
|---|---|---|---|
job.autoscaler.enabled |
false |
Abilita il dimensionamento automatico sul cluster Flink. | true, false |
job.autoscaler.decision.interval |
60s |
Intervallo di decisione di autoscaler. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.restart.time |
3m |
Tempo di riavvio previsto da utilizzare fino a quando l'operatore non sarà in grado di determinarlo in modo affidabile dalla cronologia. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.stabilization.interval |
300s |
Periodo di stabilizzazione in cui non verrà eseguito alcun nuovo dimensionamento. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.debug.logs.interval |
300s |
Intervallo di log per il debug di autoscaler. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
Aggregazione dei parametri e configurazioni cronologiche
Autoscaler recupera i parametri e li aggrega in base alla finestra temporale scorrevole; poi vengono valutati per poter prendere decisioni sul dimensionamento. La cronologia delle decisioni sul dimensionamento per ogni vertice di lavoro viene utilizzata per stimare il nuovo parallelismo. C'è sia una scadenza basata sull'età che una dimensione della cronologia (almeno 1).
| Chiave di configurazione | Valore predefinito | Descrizione | Valori di esempio |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.history.max.count |
3 |
Numero massimo di decisioni precedenti sul dimensionamento da mantenere per vertice. | 1 Da a Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
Numero minimo di decisioni precedenti sul dimensionamento da mantenere per vertice. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
Configurazioni a livello di vertice di lavoro
Il parallelismo di ciascun vertice di lavoro viene modificato in base all'utilizzo del target e limitato dai limiti di parallelismo min-max. Non è consigliabile impostare un utilizzo target vicino al 100% (ovvero il valore 1) e il limite di utilizzo funge da buffer per gestire le fluttuazioni di carico intermedie.
| Chiave di configurazione | Valore predefinito | Descrizione | Valori di esempio |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
Utilizzo del vertice target. | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
Limite di utilizzo del vertice target. Il dimensionamento non verrà eseguito se la velocità di elaborazione corrente è compresa tra [target_rate /
(target_utilization - boundary) e (target_rate /
(target_utilization + boundary)] |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
Il parallelismo minimo che l'autoscaler può utilizzare. | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
Il parallelismo massimo che l'autoscaler può utilizzare. Ricorda che autoscaler ignora questo limite se è superiore al parallelismo massimo configurato nella configurazione di Flink o direttamente su ciascun operatore. | 0 - 200 |
Configurazioni di elaborazione del backlog
Il vertice di lavoro necessita di risorse aggiuntive per gestire gli eventi in sospeso, o i backlog, che si accumulano durante il periodo delle operazioni di dimensionamento. In questo caso si parla anche di durata catch-up. Se il tempo di elaborazione del backlog supera il valore lag -threshold configurato, l'utilizzo del vertice di lavoro target aumenta fino al livello massimo. Questo aiuta a prevenire operazioni di dimensionamento non necessarie durante l'elaborazione del backlog.
| Chiave di configurazione | Valore predefinito | Descrizione | Valori di esempio |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
La soglia di ritardo eviterà dimensionamenti non necessari rimuovendo i messaggi in sospeso responsabili del ritardo. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.catch-up.duration |
15m |
La durata prevista per l'elaborazione completa di qualsiasi backlog dopo un'operazione di dimensionamento. Imposta su 0 per disabilitare il dimensionamento basato sul backlog. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
Configurazioni delle operazioni di dimensionamento
Autoscaler non esegue operazioni di riduzione immediatamente dopo un'operazione di aumento entro il periodo di grazia. In questo modo si evitano cicli di operazioni di scalabilità non necessari causati da fluttuazioni temporanee del carico up-down-up-down.
Possiamo utilizzare il rapporto operativo di riduzione per diminuire gradualmente il parallelismo e liberare risorse per far fronte a picchi di carico temporanei. Inoltre, questo aiuta a prevenire le operazioni di aumento minori non necessarie dopo un'operazione di riduzione importante.
Possiamo rilevare un'operazione di aumento inefficace in base alla cronologia delle decisioni dei vertici di lavoro precedenti in questo ambito per prevenire ulteriori modifiche al parallelismo.
| Chiave di configurazione | Valore predefinito | Descrizione | Valori di esempio |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
Durata in cui non è consentita la riduzione di un vertice dopo un aumento. | 30 (l'unità predefinita è in millisecondi), 5m, 1h |
job.autoscaler.scale-down.max-factor |
0.6 |
Fattore di dimensionamento massimo verso il basso. Un valore di 1 indica che non ci sono limiti alla riduzione, mentre 0.6 significa che il lavoro può essere ridotto solo con il 60% del parallelismo originale. |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
Rapporto massimo di aumento. Il valore 2.0 significa che sul lavoro può essere eseguito un aumento solo con il 200% del parallelismo attuale. |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
Se consentire il rilevamento di operazioni di dimensionamento inefficaci e consentire all'autoscaler di bloccare ulteriori processi di aumento. | true, false |
