Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dei processi Flink di Zeppelin in Amazon EMR
Introduzione
I rilasci 6.10.0 e successivi di Amazon EMR supportano l'integrazione Apache Zeppelin con Apache Flink. Puoi inviare processi Flink in modo interattivo tramite i notebook Zeppelin. Con l'interprete Flink, puoi eseguire query Flink, definire lo streaming Flink e i processi in batch e visualizzare l'output all'interno dei notebook Zeppelin. L'interprete Flink è costruito sulla base della REST API di Flink. Ciò consente di accedere e manipolare i processi Flink dall'ambiente Zeppelin per eseguire l'elaborazione e l'analisi dei dati in tempo reale.
Ci sono quattro sottointerpreti nell'interprete Flink. Servono a scopi diversi, ma si trovano tutti nella JVM e condividono gli stessi punti di ingresso preconfigurati per Flink (ExecutionEnviroment, StreamExecutionEnvironment, BatchTableEnvironment, StreamTableEnvironment). Gli interpreti sono i seguenti:
-
%flink– CreaExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironmentStreamTableEnvironmente fornisce un ambiente Scala -
%flink.pyflink– Fornisce un ambiente Python -
%flink.ssql– Fornisce un ambiente SQL in streaming -
%flink.bsql– Fornisce un ambiente SQL in batch
Prerequisiti
-
L'integrazione di Zeppelin con Flink è supportata per i cluster creati con Amazon EMR 6.10.0 e versioni successive.
-
Per visualizzare le interfacce Web ospitate sui cluster EMR come richiesto per questi passaggi, è necessario configurare un tunnel SSH per consentire l'accesso in entrata. Per ulteriori informazioni, consulta la sezione Configurazione delle impostazioni proxy per visualizzare siti Web ospitati sul nodo primario.
Configurazione di Zeppelin-Flink su un cluster EMR
Utilizza i seguenti passaggi per configurare Apache Flink su Apache Zeppelin per l'esecuzione su un cluster EMR:
-
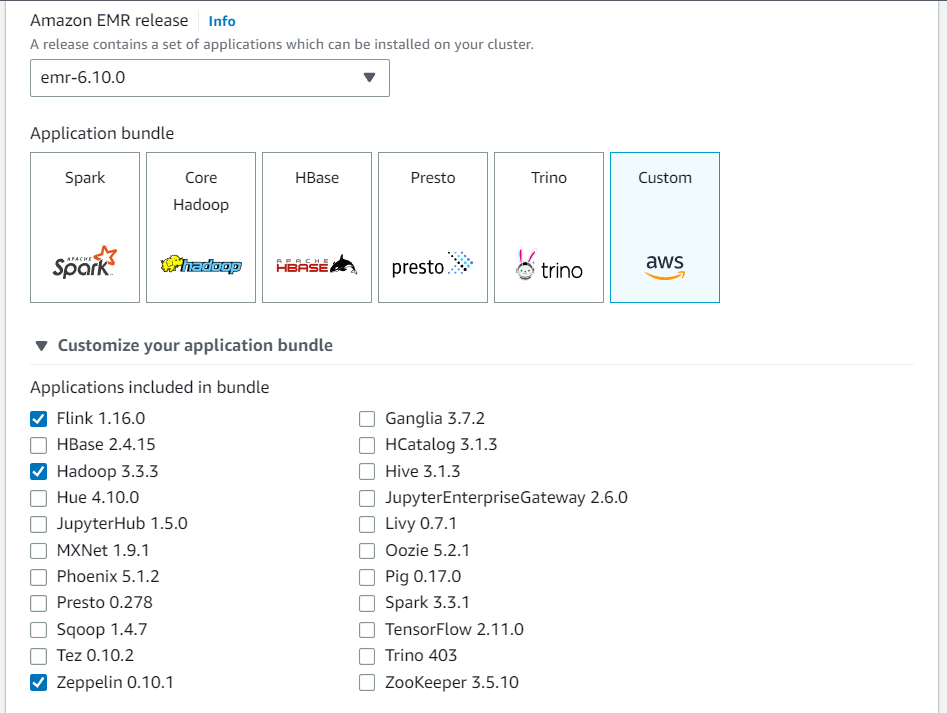
Crea un nuovo cluster dalla console Amazon EMR. Seleziona emr-6.10.0 o versioni successive per il rilascio di Amazon EMR. Quindi, scegli di personalizzare il tuo bundle di applicazioni con l'opzione Personalizzato. Includi almeno Flink, Hadoop e Zeppelin nel tuo bundle.
-
Crea il resto del cluster con le impostazioni che preferisci.
-
Una volta che il cluster è in esecuzione, selezionalo nella console per visualizzarne i dettagli e apri la scheda Applicazioni. Seleziona Zeppelin dalla sezione Interfacce utente dell'applicazione per aprire l'interfaccia Web di Zeppelin. Assicurati di aver configurato l'accesso all'interfaccia Web di Zeppelin con un tunnel SSH verso il nodo primario e una connessione proxy, come descritto in Prerequisiti.
-
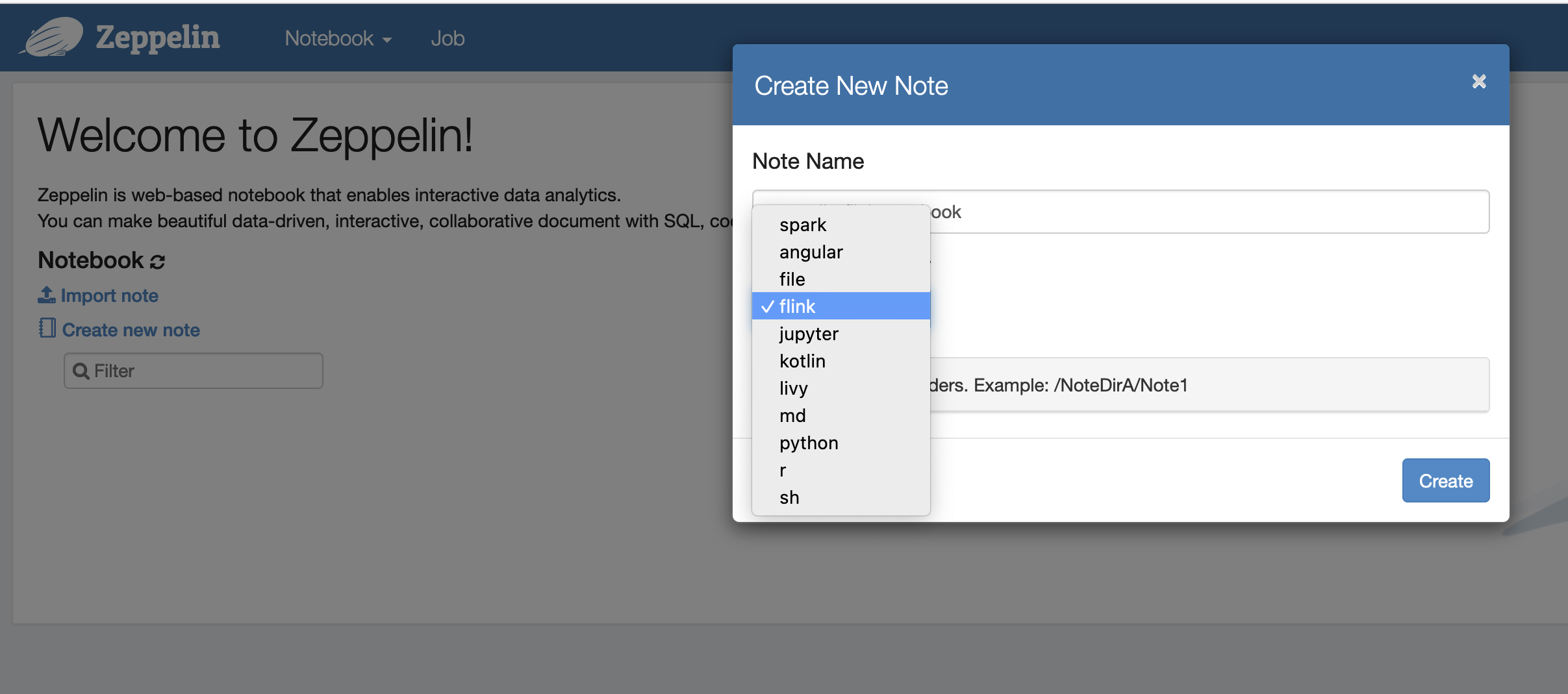
Ora puoi creare una nuova nota in un notebook Zeppelin con Flink come interprete predefinito.
-
Fai riferimento ai seguenti esempi di codice che dimostrano come eseguire i processi Flink da un notebook Zeppelin.
Esecuzione dei processi Flink con Zeppelin-Flink su un cluster EMR
-
Esempio 1, Scala in Flink
a) WordCount Esempio di Batch (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Esempio di streaming (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()
-
Esempio 2, Streaming SQL in Flink
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;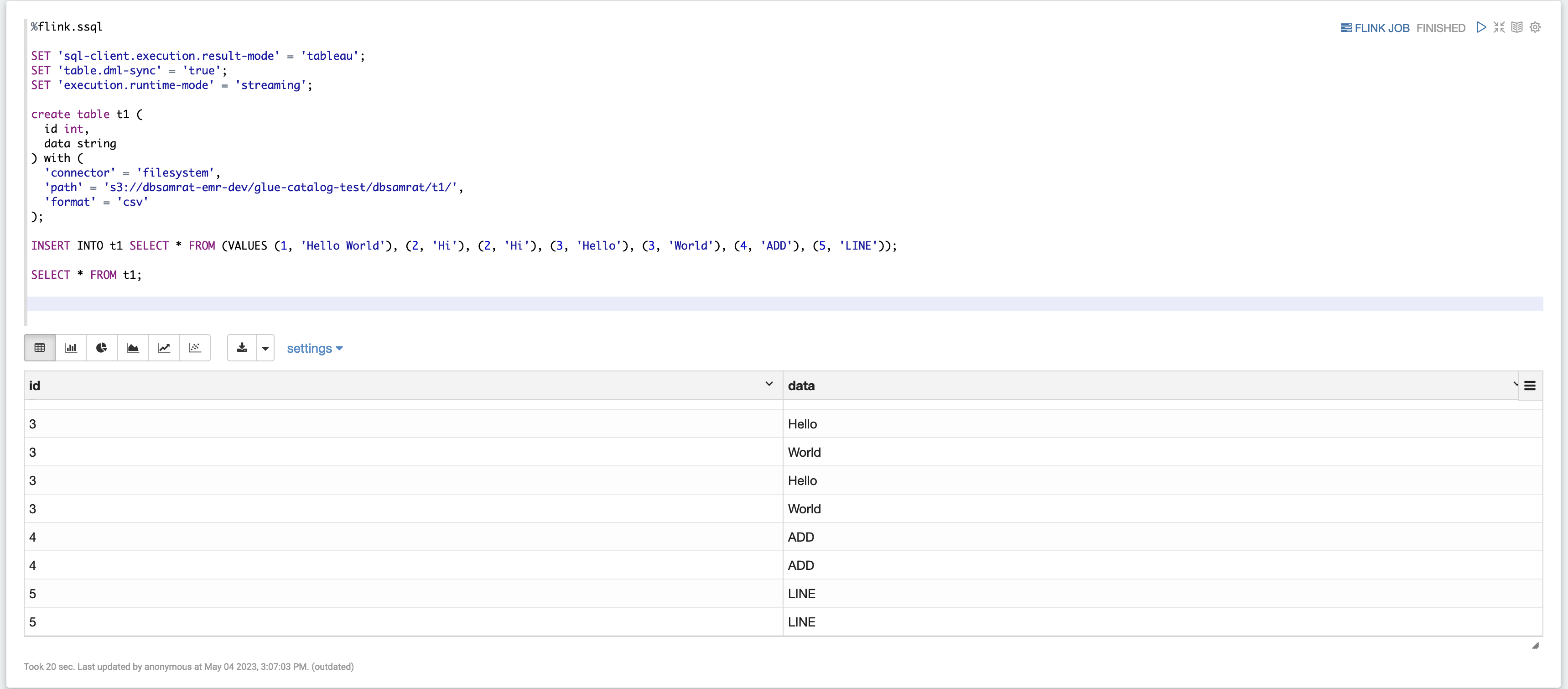
-
Esempio 3, Pyflink. Tieni presente che devi caricare il tuo file di testo di esempio denominato nel tuo
word.txtbucket S3.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
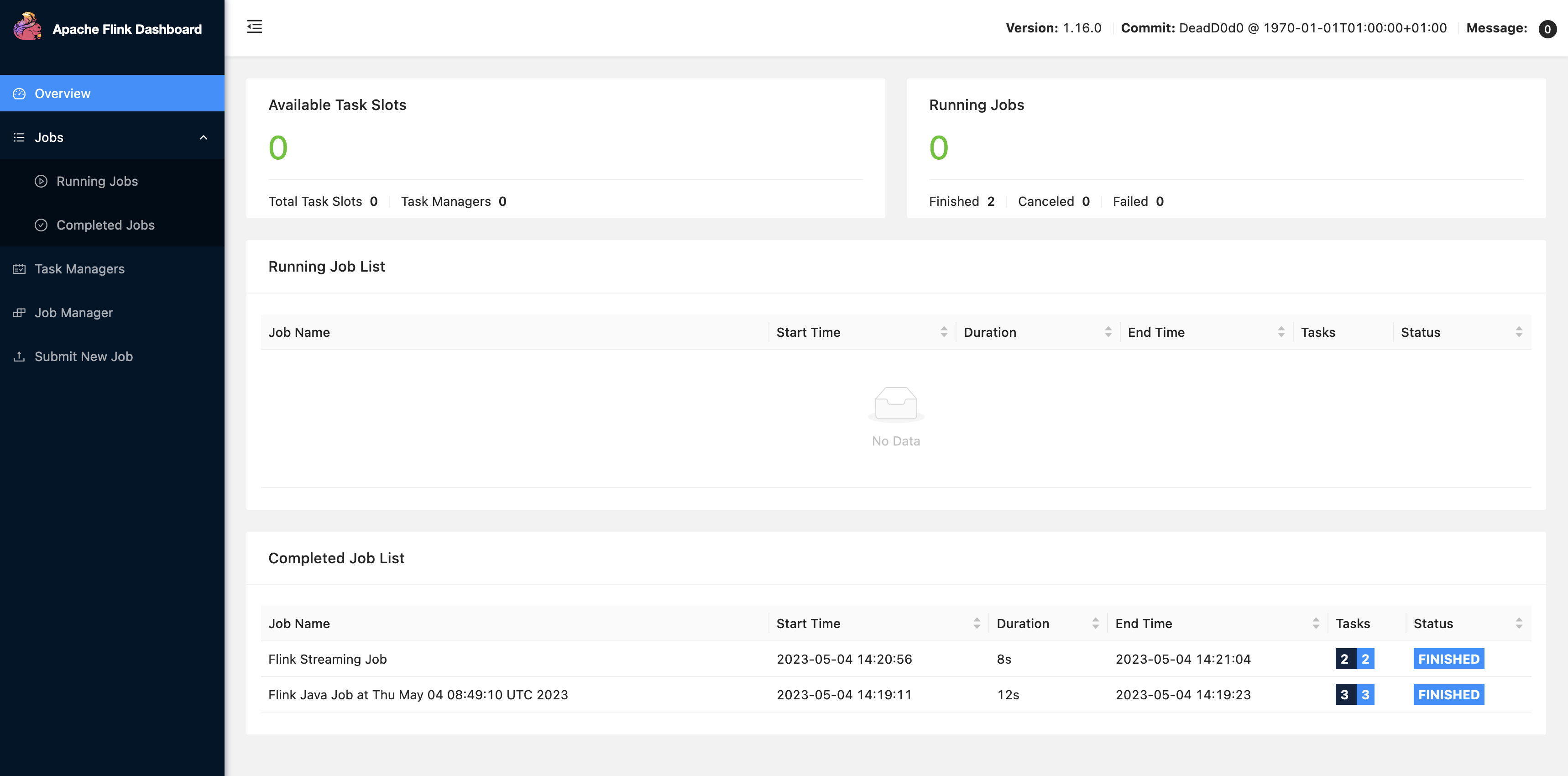
Scegli FLINK JOB nell'interfaccia utente di Zeppelin per accedere e visualizzare l'interfaccia utente Web di Flink.
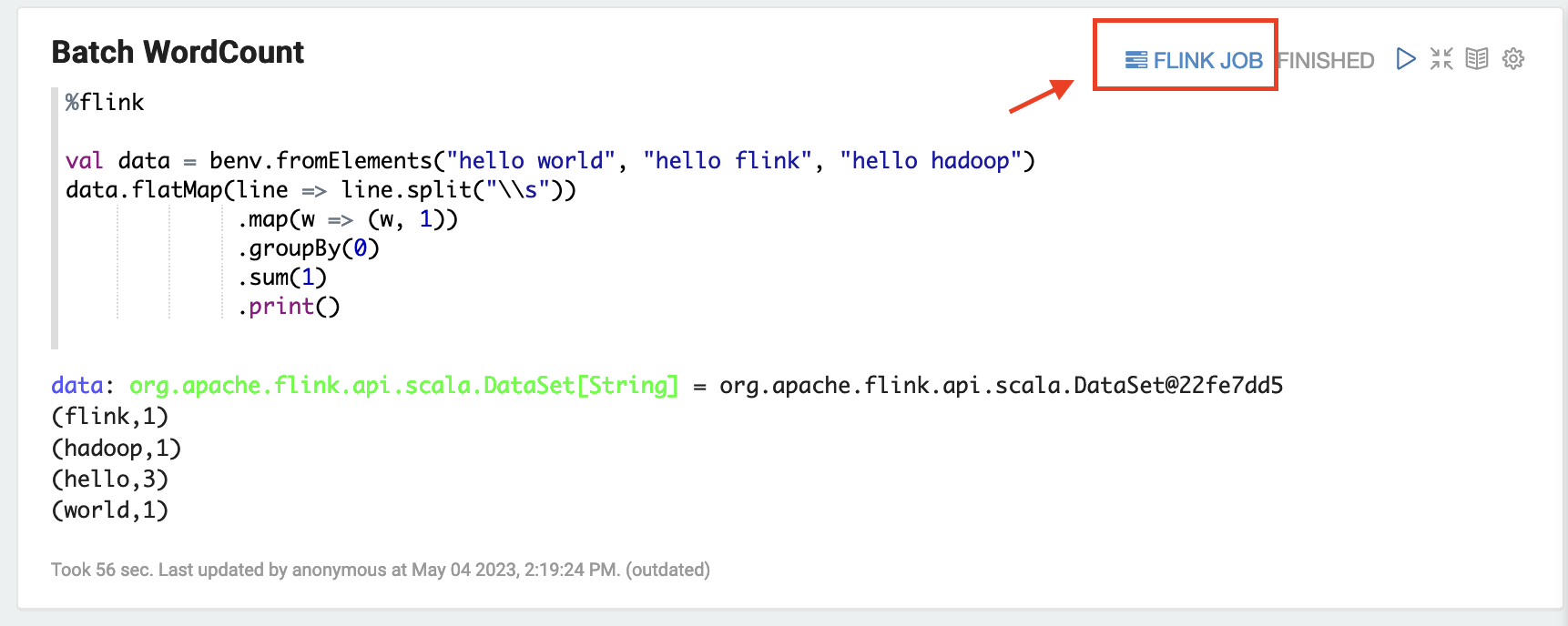
-
Scegliendo FLINK JOB si accede alla console Web di Flink in un'altra scheda del browser.