Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un flusso di lavoro di abbinamento basato su regole con il tipo di regola semplice
La procedura seguente mostra come creare un flusso di lavoro di abbinamento basato su regole con il tipo di regola Simple utilizzando la console o l'API. AWS Entity Resolution CreateMatchingWorkflow
- Console
-
Per creare un flusso di lavoro di abbinamento basato su regole con il tipo di regola Simple utilizzando la console
-
Accedi a AWS Management Console e apri la AWS Entity Resolution console all'indirizzo. https://console.aws.amazon.com/entityresolution/
-
Nel riquadro di navigazione a sinistra, in Flussi di lavoro, scegli Matching.
-
Nella pagina Flussi di lavoro corrispondenti, nell'angolo in alto a destra, scegli Crea flusso di lavoro corrispondente.
-
Per il passaggio 1: Specificare i dettagli del flusso di lavoro corrispondente, procedi come segue:
-
Immettete un nome del flusso di lavoro corrispondente e una descrizione opzionale.
-
Per l'immissione dei dati, scegli un AWS Glue database dal menu a discesa, seleziona la AWS Glue tabella e quindi la mappatura dello schema corrispondente.
È possibile aggiungere fino a 19 input di dati.
-
L'opzione Normalizza dati è selezionata per impostazione predefinita, in modo che gli input di dati vengano normalizzati prima della corrispondenza. Se non desiderate normalizzare i dati, deselezionate l'opzione Normalizza dati.
Nota
La normalizzazione è supportata solo per i seguenti scenari in Create schema mapping:
-
Se i seguenti sottotipi di nome sono raggruppati: Nome, Secondo nome, Cognome.
-
Se i seguenti sottotipi di indirizzo sono raggruppati: Indirizzo 1, Indirizzo 2, Indirizzo 3, Città, Stato, Paese, Codice postale.
-
Se i seguenti sottotipi di telefono sono raggruppati: Numero di telefono, Prefisso telefonico del paese.
-
-
Per specificare le autorizzazioni di accesso al servizio, scegli un'opzione e intraprendi l'azione consigliata.
Opzione Azione consigliata Crea e utilizza un nuovo ruolo di servizio -
AWS Entity Resolution crea un ruolo di servizio con la politica richiesta per questa tabella.
-
Il nome del ruolo di servizio predefinito è
entityresolution-matching-workflow-<timestamp>. -
È necessario disporre delle autorizzazioni per creare ruoli e allegare politiche.
-
Se i dati di input sono crittografati, puoi scegliere l'opzione Questi dati sono crittografati con una chiave KMS e quindi inserire una AWS KMS chiave che verrà utilizzata per decrittografare i dati di input.
Usa un ruolo di servizio esistente -
Scegli il nome di un ruolo di servizio esistente dall'elenco a discesa.
L'elenco dei ruoli viene visualizzato se si dispone delle autorizzazioni per elencare i ruoli.
Se non disponi delle autorizzazioni per elencare i ruoli, puoi inserire l'Amazon Resource Name (ARN) del ruolo che desideri utilizzare.
Se non ci sono ruoli di servizio esistenti, l'opzione Usa un ruolo di servizio esistente non è disponibile.
-
Visualizza il ruolo di servizio scegliendo il link esterno View in IAM.
Per impostazione predefinita, AWS Entity Resolution non tenta di aggiornare la politica esistente sui ruoli per aggiungere le autorizzazioni necessarie.
-
-
(Facoltativo) Per abilitare i tag per la risorsa, scegliete Aggiungi nuovo tag, quindi immettete la coppia Chiave e Valore.
-
Scegli Next (Successivo).
-
-
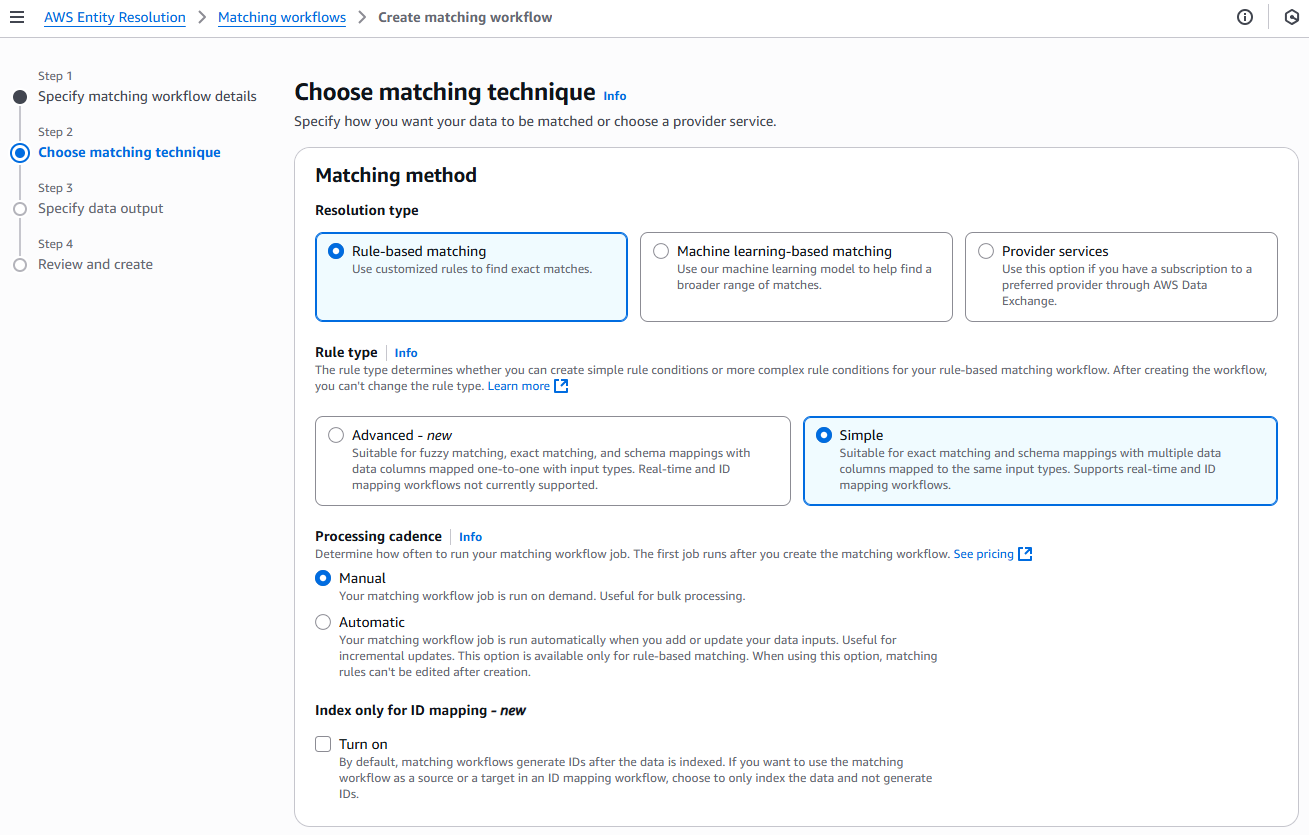
Per la fase 2: Scegli la tecnica di abbinamento:
-
Per il metodo di abbinamento, scegli Abbinamento basato su regole.
-
Per Tipo di regola, scegli Semplice.
-
Per Processing cadence, selezionate una delle seguenti opzioni.
-
Scegliete Manuale per eseguire un flusso di lavoro su richiesta per un aggiornamento collettivo
-
Scegli Automatico per eseguire un flusso di lavoro non appena nuovi dati sono presenti nel tuo bucket S3
Nota
Se scegli Automatico, assicurati di avere EventBridge le notifiche Amazon attivate per il tuo bucket S3. Per istruzioni su come abilitare Amazon EventBridge tramite la console S3, consulta Enabling Amazon EventBridge nella Amazon S3 User Guide.
-
-
(Facoltativo) Per Indicizza solo per la mappatura degli ID, puoi scegliere di attivare la capacità di indicizzare solo i dati e non di generarli. IDs
Per impostazione predefinita, il flusso di lavoro corrispondente viene generato IDs dopo l'indicizzazione dei dati.
-
Per le regole di corrispondenza, inserisci il nome di una regola, quindi scegli i tasti di corrispondenza per quella regola.
Puoi creare fino a 15 regole e applicare fino a 15 chiavi di abbinamento diverse alle regole per definire i criteri di corrispondenza.

-
Per Tipo di confronto, scegli una delle seguenti opzioni in base al tuo obiettivo.
Il tuo obiettivo Opzione consigliata Trova qualsiasi combinazione di corrispondenze tra i dati archiviati in più campi di input Campi di input multipli Limita il confronto a un singolo campo di input Campo di input singolo 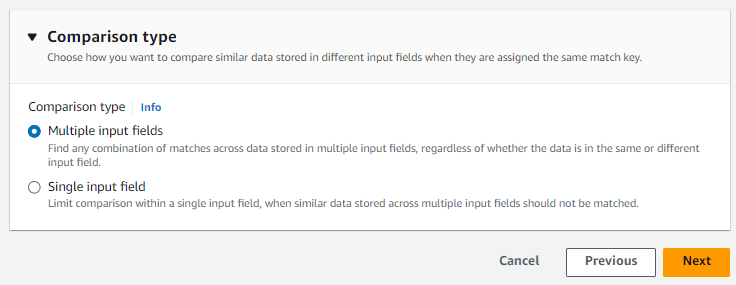
-
Scegli Next (Successivo).
-
-
Per la fase 3: Specificare l'output e il formato dei dati:
-
Per Destinazione e formato di output dei dati, scegli la posizione Amazon S3 per l'output dei dati e se il formato dei dati sarà Dati normalizzati o Dati originali.
-
Per la crittografia, se scegli di personalizzare le impostazioni di crittografia, inserisci la AWS KMS chiave ARN.
-
Visualizza l'output generato dal sistema.
-
Per l'output dei dati, decidi quali campi includere, nascondere o mascherare, quindi intraprendi le azioni consigliate in base ai tuoi obiettivi.
Il tuo obiettivo Azione consigliata Includi campi Mantieni lo stato di output come incluso. Nascondi i campi (escludi dall'output) Scegli il campo Output, quindi scegli Nascondi. Maschera i campi Scegli il campo Output, quindi scegli Hash output. Ripristina le impostazioni precedenti Scegliere Reimposta. -
Scegli Next (Successivo).
-
-
Per il passaggio 4: rivedi e crea:
-
Rivedi le selezioni effettuate per i passaggi precedenti e modificale se necessario.
-
Scegli Create and run (Crea ed esegui).
Viene visualizzato un messaggio che indica che il flusso di lavoro corrispondente è stato creato e che il processo è iniziato.
-
-
Nella pagina dei dettagli del flusso di lavoro corrispondente, nella scheda Metriche, visualizza quanto segue in Metriche dell'ultimo lavoro:
-
Il Job ID.
-
Lo stato del processo del flusso di lavoro corrispondente: In coda, In corso, Completato, Non riuscito
-
Il tempo di completamento del processo del flusso di lavoro.
-
Il numero di record elaborati.
-
Il numero di record non elaborati.
-
La corrispondenza unica IDs generata.
-
Il numero di record di input.
Puoi anche visualizzare le metriche dei job per i job corrispondenti ai job del flusso di lavoro che sono stati eseguiti in precedenza nella cronologia Job.
-
-
Una volta completato il processo del flusso di lavoro corrispondente (lo stato è completato), puoi andare alla scheda Data output e quindi selezionare la tua sede Amazon S3 per visualizzare i risultati.
-
(Solo tipo di elaborazione manuale) Se hai creato un flusso di lavoro di abbinamento basato su regole con il tipo di elaborazione manuale, puoi eseguire il flusso di lavoro corrispondente in qualsiasi momento selezionando Esegui flusso di lavoro nella pagina dei dettagli del flusso di lavoro corrispondente.
-
- API
-
Per creare un flusso di lavoro di abbinamento basato su regole con il tipo di regola semplice utilizzando l'API
Nota
Per impostazione predefinita, il flusso di lavoro utilizza l'elaborazione standard (batch). Per utilizzare l'elaborazione incrementale (automatica), è necessario configurarla in modo esplicito.
-
Apri un terminale o un prompt dei comandi per effettuare la richiesta API.
-
Crea una richiesta POST per il seguente endpoint:
/matchingworkflows -
Nell'intestazione della richiesta, imposta il Content-type su application/json.
-
Per il corpo della richiesta, fornisci i seguenti parametri JSON richiesti:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringDove:
-
workflowName(obbligatorio) — Deve essere univoco e deve contenere da 1 a 255 caratteri e corrispondere allo schema [a-zA-Z_0-9-] * -
inputSourceConfig(obbligatorio) — Elenco di 1—20 configurazioni delle sorgenti di ingresso -
outputSourceConfig(richiesto) — Esattamente una configurazione della sorgente di uscita -
resolutionTechniques(obbligatorio) — Imposta su «RULE_MATCHING» per la corrispondenza basata su regole -
roleArn(obbligatorio) — Ruolo IAM ARN per l'esecuzione del flusso di lavoro -
ruleConditionProperties(obbligatorio): elenco delle condizioni della regola e nome della regola corrispondente.
I parametri opzionali includono:
-
description— Fino a 255 caratteri -
incrementalRunConfig— Configurazione incrementale del tipo di esecuzione -
tags— Fino a 200 coppie chiave-valore
-
-
(Facoltativo) Per utilizzare l'elaborazione incrementale anziché l'elaborazione standard predefinita (batch), aggiungete il seguente parametro al corpo della richiesta:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Inviare la richiesta .
-
In caso di successo, riceverai una risposta con il codice di stato 200 e un corpo JSON contenente:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Se la chiamata non va a buon fine, potresti ricevere uno di questi errori:
-
400 — ConflictException se il nome del flusso di lavoro esiste già
-
400 — ValidationException se la convalida dell'input non supera
-
402 — ExceedsLimitException se i limiti dell'account vengono superati
-
403 — AccessDeniedException se non disponi di un accesso sufficiente
-
429 — ThrottlingException se la richiesta è stata limitata
-
500 — InternalServerException se si verifica un errore interno del servizio
-
-
