Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funzionano le configurazioni di processo
Le configurazioni di rollout e di interruzione si utilizzano durante l'implementazione di un processo, mentre le configurazioni di timeout e nuovo tentativo si utilizzano per l'esecuzione di un processo. Nelle sezioni seguenti sono visualizzate ulteriori informazioni sul funzionamento di queste configurazioni.
Argomenti
Configurazioni di rollout, pianificazione e interruzione dei processi
È possibile utilizzare le configurazioni di rollout, interruzione e pianificazione dei processi per definire quanti dispositivi ricevono il documento del processo, pianificare una configurazione dei rollout del processo e determinare i criteri di annullamento di un processo.
Puoi specificare con che velocità vengono inviate ai target le notifiche relative all'esecuzione di un processo in sospeso. È inoltre possibile creare un rollout per fasi per gestire aggiornamenti, riavvii e altre operazioni. Per specificare le modalità di invio delle notifiche agli obiettivi, usa le velocità di rollout del processo.
Velocità di rollout del processo
Puoi creare una configurazione di rollout utilizzando una velocità di rollout costante o esponenziale. Per specificare il numero massimo di obiettivi di processo a cui inviare notifiche ogni minuto, utilizza una velocità di rollout costante.
AWS IoT i lavori possono essere implementati utilizzando tassi di implementazione esponenziali man mano che vengono soddisfatti vari criteri e soglie. Se il numero di processi non riusciti corrisponde a un insieme di criteri che specifichi, il rollout di processo viene annullato. Puoi impostare i criteri della velocità di rollout del processo quando crei un processo utilizzando l'oggetto JobExecutionsRolloutConfig. Anche i criteri di interruzione del processo vanno impostati al momento della creazione di un processo mediante l'oggetto AbortConfig.
L'esempio seguente mostra come funziona la velocità di rollout. Ad esempio, un processo di rollout con una frequenza di base di 50 al minuto, un fattore di incremento di 2 e un numero di dispositivi notificati ed esecuzioni riuscite pari a 1.000, funziona come segue: il processo inizia con una frequenza di 50 esecuzioni del processo al minuto e prosegue a tale frequenza fino a quando 1.000 oggetti non hanno ricevuto notifiche di esecuzione del processo o non si sono verificate 1.000 esecuzioni del processo.
La tabella riportata di seguito mostra il modo in cui il rollout dovrebbe procedere oltre i primi quattro incrementi.
|
Velocità di rollout al minuto |
50 |
100 |
200 |
400 |
|
Numero di dispositivi notificati o di esecuzioni del processo riuscite per soddisfare l'incremento della velocità |
1.000 |
2.000 |
3.000 |
4.000 |
Nota
Se è stato raggiunto il limite massimo di 500 processi simultanei (isConcurrent = True), tutti i processi attivi rimarranno in uno stato IN-PROGRESS e non verranno implementate nuove esecuzioni del processo finché il numero di processi simultanei non sarà pari o inferiore a 499 (isConcurrent = False)). Questo si applica a processi continui e a processi snapshot.
Se isConcurrent = True, il processo sta attualmente implementando esecuzioni del processo in tutti i dispositivi del gruppo di destinazione. Se isConcurrent = False, il processo ha completato il rollout di tutte le esecuzioni del processo in tutti i dispositivi del gruppo di destinazione. Aggiornerà il suo stato quando tutti i dispositivi nel gruppo di destinazione raggiungono uno stato terminale o una percentuale di soglia del gruppo di destinazione, se è stata selezionata una configurazione di interruzione del processo. Gli stati di livello del processo per isConcurrent = True e isConcurrent = False sono entrambi IN_PROGRESS.
Per ulteriori informazioni sui limiti di processi attivi e simultanei, consulta Limiti dei processi attivi e simultanei.
Velocità di rollout per processi continui che utilizzano gruppi di oggetti dinamici
Quando utilizzi un processo continuo per implementare operazioni remote sulla tua flotta, AWS IoT Jobs implementa le esecuzioni di lavoro per i dispositivi del gruppo di oggetti target. Per i nuovi dispositivi aggiunti al gruppo di oggetti dinamico, queste esecuzioni dei processi continuano a essere implementate per questi dispositivi anche dopo la creazione del processo.
La configurazione di rollout può controllare la velocità di rollout solo per i dispositivi aggiunti al gruppo fino alla creazione del processo. Una volta creato il processo, per qualsiasi nuovo dispositivo, le esecuzioni del processo vengono create pressoché in tempo reale non appena i dispositivi vengono aggiunti al gruppo di destinazione.
È possibile pianificare un processo continuo o snapshot fino a un anno in anticipo utilizzando un'ora di inizio, un'ora di fine predeterminati e un comportamento di fine per ciò che accadrà a ogni esecuzione del processo quando si raggiunge l'ora di fine. Inoltre, è possibile creare una finestra di manutenzione ricorrente opzionale con una frequenza, un'ora di inizio e una durata flessibili per processi continui per distribuire un documento del processo in tutti i dispositivi all'interno del gruppo di destinazione.
Configurazioni di pianificazione del processo
Ora di inizio
L'ora di inizio di un processo pianificato è la data e l'ora future di inizio del rollout del documento del processo in tutti i dispositivi del gruppo di destinazione. L'ora di inizio di un processo pianificato si applica ai processi continui e ai processi snapshot. Quando un processo pianificato viene creato, all’inizio mantiene lo stato di SCHEDULED. Non appena arriva la startTime selezionata, lo stato viene aggiornato in IN_PROGRESS e viene avviato il rollout del documento del processo. La startTime deve essere inferiore o uguale ad un anno dalla data e ora iniziali in cui hai creato il processo pianificato.
Per un processo in cui la configurazione della pianificazione opzionale viene eseguita durante una finestra di manutenzione ricorrente in una località in cui vige l'ora legale (DST), la durata cambierà di un'ora quando si passa dall'ora legale all'ora solare e dall'ora solare all'ora legale.
Nota
Il fuso orario visualizzato in AWS Management Console è il fuso orario corrente del sistema. Tuttavia, questi fusi orari verranno convertiti in UTC nel sistema.
Ora di fine
L'ora di fine di un processo pianificato è la data e l'ora future in cui il processo interromperà il rollout del documento del processo nei dispositivi rimanenti del gruppo di destinazione. L'ora di fine di un processo pianificato si applica ai processi continui e ai processi snapshot. Una volta che un processo arriva alla endTime selezionata e tutte le esecuzioni del processo hanno raggiunto uno stato terminale, il suo stato viene aggiornato da IN_PROGRESS a COMPLETED. La endTime deve essere inferiore o uguale a due anni dalla data e ora iniziali in cui hai creato il processo pianificato. La durata minima compresa tra startTime e endTime è di 30 minuti. I tentativi di ripetizione dell'esecuzione del processo verranno eseguiti finché il processo non raggiunge la endTime, dopo di che endBehavior indicherà come procedere.
Per ulteriori informazioni sulla sintassi da utilizzare con un comando API o il AWS CLI, consulta Timestamp. endTime
Per un processo in cui la configurazione della pianificazione opzionale viene eseguita durante una finestra di manutenzione ricorrente in una località in cui vige l'ora legale (DST), la durata cambierà di un'ora quando si passa dall'ora legale all'ora solare e dall'ora solare all'ora legale.
Nota
Il fuso orario visualizzato in AWS Management Console è il fuso orario corrente del sistema. Tuttavia, questi fusi orari verranno convertiti in UTC nel sistema.
Comportamento di fine
Il comportamento di fine di un processo pianificato determina cosa accade al processo e a tutte le esecuzioni del processo non completate quando il processo raggiunge endTime selezionata.
Di seguito sono elencati i comportamenti finali che puoi utilizzare durante la creazione del processo o del modello di processo:
-
STOP_ROLLOUT-
STOP_ROLLOUTinterrompe il rollout del documento del processo in tutti i dispositivi rimanenti nel gruppo di destinazione del processo. Inoltre, tutte le esecuzioni del processoQUEUEDeIN_PROGRESScontinueranno finché non raggiungono uno stato terminale. Questo è il comportamento di fine predefinito a meno che non si selezioniCANCELoFORCE_CANCEL.
-
-
CANCEL-
CANCELinterrompe il rollout del documento del processo in tutti i dispositivi rimanenti nel gruppo di destinazione del processo. Inoltre, tutte le esecuzioni del processoQUEUEDverranno annullate mentre tutte le esecuzioni del processoIN_PROGRESScontinueranno finché non raggiungono uno stato terminale.
-
-
FORCE_CANCEL-
FORCE_CANCELinterrompe il rollout del documento del processo in tutti i dispositivi rimanenti nel gruppo di destinazione del processo. Inoltre, tutte le esecuzioni del processoQUEUEDeIN_PROGRESSverranno annullate.
-
Nota
Per selezionare unendbehavior, è necessario selezionare un endtime
Durata massima
La durata massima di un processo pianificato deve essere inferiore o uguale a due anni a prescindere da startTime e endTime.
Nella tabella seguente sono elencati gli scenari di durata comuni di un processo pianificato:
| Numero del processo pianificato di esempio | startTime | endTime | Durata massima |
|---|---|---|---|
|
1 |
Subito dopo la creazione del processo iniziale. |
Un anno dopo la creazione del processo iniziale. |
Un anno |
|
2 |
Un mese dopo la creazione del processo iniziale. |
13 mesi dopo la creazione del processo iniziale. |
Un anno |
|
3 |
Un anno dopo la creazione del processo iniziale. |
Due anni dopo la creazione del processo iniziale. |
Un anno |
|
4 |
Subito dopo la creazione del processo iniziale. |
Due anni dopo la creazione del processo iniziale. |
Due anni |
Finestra di manutenzione ricorrente
La finestra di manutenzione è una configurazione opzionale all'interno della configurazione di pianificazione di AWS Management Console e all'SchedulingConfiginterno della CreateJob e CreateJobTemplate APIs. È possibile impostare una finestra di manutenzione ricorrente con un'ora di inizio, una durata e una frequenza predeterminate (giornaliera, settimanale o mensile) in cui si verifica la finestra di manutenzione. Le finestre di manutenzione si applicano solo ai processi continui. La durata massima di una finestra di manutenzione ricorrente è di 23 ore e 50 minuti.
Nel diagramma seguente vengono illustrati gli stati del processo per diversi scenari di processi pianificati con una finestra di manutenzione opzionale:
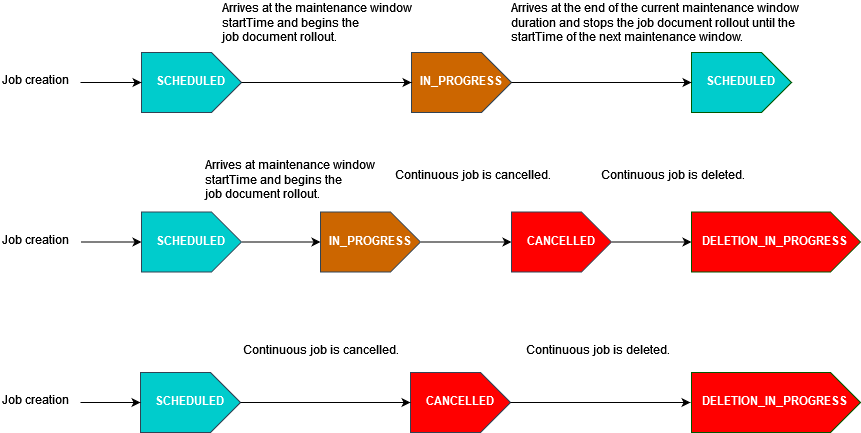
Per ulteriori informazioni sugli stati dei processi, consulta Processi e stati di esecuzione dei processi.
Nota
Se un lavoro arriva a endTime durante una finestra di manutenzione, verrà aggiornato da IN_PROGRESS a COMPLETED. Inoltre, tutte le esecuzioni del processo rimanenti seguiranno il endBehavior per il processo.
Espressioni cron
Per i processi pianificati che distribuiscono il documento di processo durante una finestra di manutenzione con una frequenza personalizzata, la frequenza personalizzata viene immessa utilizzando un'espressione cron. Un'espressione cron contiene sei campi obbligatori che sono separati da uno spazio vuoto.
Sintassi
cron(fields)
| Campo | Valori | Caratteri jolly |
|---|---|---|
|
Minuti |
0-59 |
, - * / |
|
Ore |
0-23 |
, - * / |
|
D ay-of-month |
1-31 |
, - * ? / L W |
|
Mese |
1-12 o JAN-DEC |
, - * / |
|
D ay-of-week |
1-7 o SUN-SAT |
, - * ? L # |
|
Anno |
1970-2199 |
, - * / |
Caratteri jolly
-
Il carattere jolly , (virgola) include valori aggiuntivi. Nel campo Month (Mese), JAN,FEB,MAR (GEN,FEB,MAR) include gennaio, febbraio e marzo.
-
Il carattere jolly - (trattino) specifica gli intervalli. Nel campo Day (Giorno), 1-15 include i giorni dall'1 al 15 del mese specificato.
-
Il carattere jolly * (asterisco) include tutti i valori nel campo. Nel campo Hours (Ore), * include ogni ora. Non puoi usare * in entrambi i Day-of-week campi Day-of-month e. Se viene utilizzato in uno di tali campi, è necessario utilizzare ? nell'altro.
-
Il carattere jolly / (barra) specifica gli incrementi. Nel campo Minutes (Minuti), puoi inserire 1/10 per specificare ogni decimo minuto, a partire dal primo minuto dell'ora (ad esempio, l'11°, il 21° e il 31° minuto e così via).
-
Il carattere jolly ? (punto interrogativo) specifica un valore. Nel Day-of-month campo puoi inserire 7 e se non ti interessa in che giorno della settimana è il 7, puoi inserire? sul Day-of-week campo.
-
Il carattere jolly L nel campo Day-of-month o Day-of-week specifica l'ultimo giorno del mese o della settimana.
-
Il carattere
Wjolly nel Day-of-month campo specifica un giorno della settimana. Nel Day-of-month campo,3Wspecifica il giorno della settimana più vicino al terzo giorno del mese. -
Il carattere jolly # nel Day-of-week campo specifica una determinata istanza del giorno della settimana specificato nell'arco di un mese. Ad esempio, 3#2 sarebbe il secondo martedì del mese: il 3 fa riferimento a martedì perché è il terzo giorno di ogni settimana e il 2 fa riferimento al secondo giorno di questo tipo in un mese.
Nota
Se si utilizza un carattere '#', è possibile definire una sola espressione nel day-of-week campo. Ad esempio,
"3#1,6#3"non è valido perché viene interpretato come due espressioni.
Restrizioni
-
Non puoi specificare i campi Day-of-month e Day-of-week nella stessa espressione cron. Se specifichi un valore (o un *) in uno dei campi, devi usare un carattere ? nell'altro campo.
Examples (Esempi)
Fare riferimento alle stringhe cron di esempio seguenti durante l'utilizzo di un'espressione cron per la startTime di una finestra di manutenzione ricorrente.
| Minuti | Ore | Giorno del mese | Mese | Giorno della settimana | Anno | Significato |
|---|---|---|---|---|---|---|
| 0 | 10 | * | * | ? | * |
Esegui ogni giorno alle 10:00 (UTC) |
| 15 | 12 | * | * | ? | * |
Esegui ogni giorno alle 12:15 (UTC) |
| 0 | 18 | ? | * | LUN-VEN | * |
Esegui dal lunedì al venerdì alle 18:00 (UTC) |
| 0 | 8 | 1 | * | ? | * |
Esegui ogni primo giorno del mese alle 8.00 (UTC) |
Logica di fine durata della finestra di manutenzione ricorrente
Quando la distribuzione di un processo durante una finestra di manutenzione raggiunge la durata di occorrenza della finestra di manutenzione corrente, si verificheranno le seguenti azioni:
-
Il processo interromperà tutte le distribuzioni del documento del processo negli eventuali dispositivi rimanenti nel gruppo di destinazione. Riprenderà alle
startTimedella finestra di manutenzione successiva. -
Tutte le esecuzioni dei processi con stato
QUEUEDrimarranno nello statoQUEUEDfino alstartTimedella finestra di manutenzione successiva. Nella finestra successiva, possono passare aIN_PROGRESSquando il dispositivo è pronto per iniziare a eseguire le azioni specificate nel documento di processo. -
Tutte le esecuzioni del processo con uno stato di
IN_PROGRESScontinueranno a eseguire le azioni specificate nel documento del processo finché non raggiungono uno stato terminale. Qualsiasi tentativo di ripetizione come specificato inJobExecutionsRetryConfigverrà eseguito allestartTimedella finestra di manutenzione successiva.
Utilizza questa configurazione per creare un criterio per annullare un processo quando una percentuale di soglia dei dispositivi soddisfa tale criterio. Ad esempio, puoi utilizzare questa configurazione per annullare un processo nei seguenti casi:
-
Quando una percentuale soglia di dispositivi non riceve le notifiche di esecuzione del lavoro, ad esempio quando il dispositivo non è compatibile per un aggiornamento Over-The-Air (OTA). In questo caso, il dispositivo può segnalare uno stato
REJECTED. -
Quando una percentuale di soglia dei dispositivi segnala un errore nell'esecuzione del processo, ad esempio nel caso in cui il dispositivo rilevi una disconnessione quando tenta di effettuare il download del documento di processo da un URL Amazon S3. In questi casi, il dispositivo deve essere programmato in modo da segnalare a AWS IoT lo stato
FAILURE. -
Quando viene segnalato lo stato
TIMED_OUTin seguito al timeout dell'esecuzione del processo per una percentuale di soglia dei dispositivi dopo l'avvio dell'esecuzione del processo. -
Quando si verificano più tentativi falliti. Quando aggiungi una configurazione di nuovo tentativo, ogni nuovo tentativo può comportare costi aggiuntivi per il tuo Account AWS. In questi casi, l'annullamento del processo può annullare le esecuzioni del processo in coda ed evitare nuovi tentativi per queste esecuzioni. Per ulteriori informazioni sulla configurazione del nuovo tentativo e sul suo utilizzo con la configurazione di interruzione, consulta Configurazioni di timeout e di nuovo tentativo di esecuzione del processo.
Puoi impostare una condizione di interruzione del lavoro utilizzando la AWS IoT console o l'API AWS IoT Jobs.
Configurazioni di timeout e di nuovo tentativo di esecuzione del processo
Utilizza la configurazione del timeout di esecuzione del processo per ricevere Notifiche dei processi quando l'esecuzione di un processo è in corso per un periodo più lungo della durata impostata. Utilizza la configurazione del nuovo tentativo di esecuzione del processo per ritentare l'esecuzione quando il processo fallisce o scade.
Utilizza la configurazione del timeout di esecuzione del processo per ricevere notifiche ogni volta che l'esecuzione di un processo si blocca nello stato IN_PROGRESS per un periodo di tempo inaspettatamente lungo. Quando il processo è IN_PROGRESS, è possibile monitorare il progresso dell'esecuzione del processo.
Timer per i timeout di processo
Sono disponibili due tipi di timer: in corso e della fase.
Timer in corso
Quando crei un processo o un modello di processo, puoi specificare un valore per il timer in corso compreso tra 1 minuto e 7 giorni. Puoi aggiornare il valore di questo timer fino all'avvio dell'esecuzione del processo. Dopo l'avvio del timer, il valore non può più essere aggiornato e il valore del timer viene applicato a tutte le esecuzioni del processo. Ogni volta che l'esecuzione di un job rimane nello IN_PROGRESS stato per un periodo superiore a questo intervallo, l'esecuzione fallisce e passa allo stato del terminale. TIMED_OUT AWS IoT pubblica anche una notifica MQTT.
Timer della fase
Puoi anche impostare un timer della fase applicabile solo all'esecuzione del processo che desideri aggiornare. Questo timer non ha alcun effetto sul timer in corso. Puoi impostare un nuovo valore per questo timer ogni volta che aggiorni l'esecuzione di un processo. Puoi anche creare un nuovo timer della fase all'avvio della successiva esecuzione del processo in sospeso per un oggetto. Se l'esecuzione del processo resta nello stato IN_PROGRESS per un periodo di tempo superiore a quello consentito dall'intervallo del timer della fase, l'esecuzione del processo non va a buon fine e viene impostato lo stato TIMED_OUT terminale.
Nota
È possibile impostare il timer in corso utilizzando la AWS IoT console o l' AWS IoT API Jobs. Per specificare il timer della fase, utilizza l'API.
Come funzionano i timer per i timeout di processo
Il seguente esempio illustra le varie interazioni fra i timeout in corso e quelli della fase in un periodo di timeout di 20 minuti.
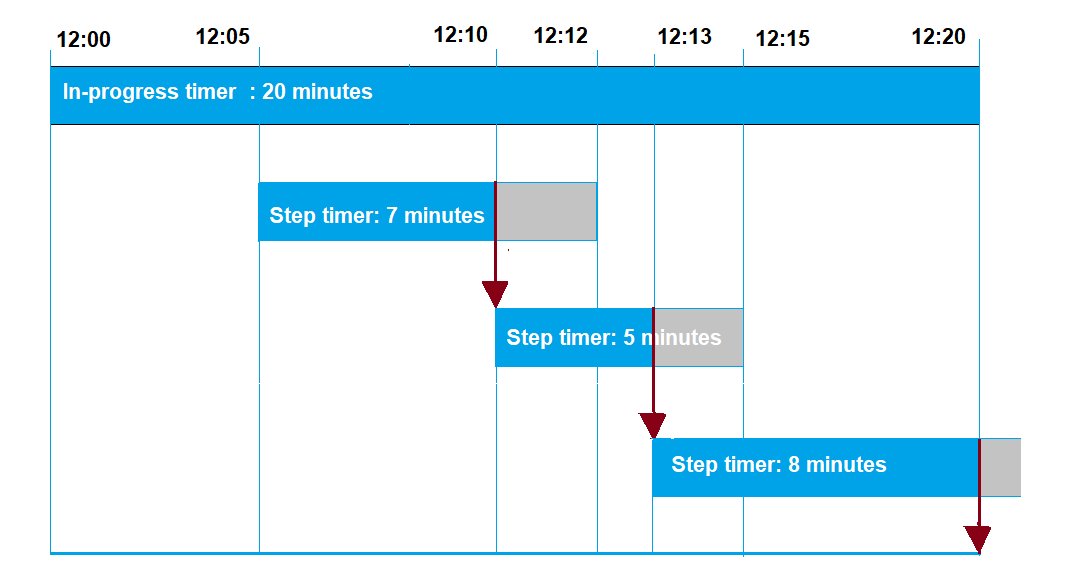
Di seguito vengono illustrate le diverse fasi:
-
12:00
Viene creato un nuovo processo; durante la creazione dello stesso, viene avviato un timer in corso per venti minuti. Il timer in corso avvia l'esecuzione e l'esecuzione del processo passa allo stato
IN_PROGRESS. -
12:05
Viene creato un nuovo timer della fase con un valore di 7 minuti. L'esecuzione del processo ora scadrà alle 12:12.
-
12:10
Viene creato un nuovo timer della fase con un valore di 5 minuti. Quando viene creato il nuovo timer della fase, il timer della fase precedente viene eliminato e l'esecuzione del processo ora scadrà alle 12:15.
-
12:13
Viene creato un nuovo timer della fase con un valore di 9 minuti. Il timer della fase precedente viene eliminato e l'esecuzione del processo ora scadrà alle 12:20, perché il timer in corso scadrà alle 12:20. Il timer della fase non può superare il limite assoluto creato dal timer in corso.
Puoi utilizzare la configurazione del nuovo tentativo per ritentare l'esecuzione del processo quando viene soddisfatto un determinato set di criteri. È possibile effettuare un nuovo tentativo quando un processo scade o quando un dispositivo sperimenta un errore. Per ritentare l'esecuzione a causa di un errore di timeout, è necessario abilitare la configurazione del timeout.
Come utilizzare la configurazione del nuovo tentativo
Segui la procedura riportata di seguito per questa configurazione:
-
Stabilisci se utilizzare la configurazione di nuovo tentativo per
FAILED, perTIMED_OUTo per entrambi i criteri di errore. Per quanto riguarda loTIMED_OUT -
Per lo stato
FAILED, controlla se l'esecuzione del processo fallita può essere ritentata. Se l'errore è ritentabile, programma il dispositivo in modo da segnalare a AWS IoT lo statoFAILURE. Nella sezione seguente vengono fornite ulteriori informazioni sugli errori ritentabili e non ritentabili. -
Specifica il numero di tentativi da effettuare per ciascun tipo di errore utilizzando le informazioni precedenti. Per ciascun dispositivo, puoi specificare fino a 10 tentativi per entrambi i tipi di errore combinati. I nuovi tentativi si arrestano automaticamente quando un'esecuzione ha esito positivo o al raggiungimento del numero di tentativi specificato.
-
Aggiungi una configurazione di interruzione per annullare il processo in caso di tentativi ripetuti non riusciti per evitare di incorrere in addebiti aggiuntivi se il numero di nuovi tentativi è elevato.
Nota
Quando un processo raggiunge la fine di un'occorrenza della finestra di manutenzione ricorrente, tutte le esecuzioni del processo IN_PROGRESS continueranno a eseguire le azioni identificate nel documento del processo finché non raggiungono lo stato terminale. Se l'esecuzione di un processo raggiunge uno stato terminale di FAILED o TIMED_OUT all'esterno di una finestra di manutenzione, si verificherà un tentativo di ripetizione nella finestra di manutenzione successiva, se i tentativi di ripetizione non sono esauriti. All’startTime della successiva finestra di manutenzione, verrà creata una nuova esecuzione del processo che avrà lo stato di QUEUED finché il dispositivo non è pronto per iniziare.
Configurazione con nuovo tentativo e interruzione
Ogni nuovo tentativo comporta costi aggiuntivi per il tuo. Account AWS Per evitare costi aggiuntivi dovuti a ripetuti tentativi falliti, ti consigliamo di aggiungere una configurazione di interruzione. Per ulteriori informazioni sui prezzi, consulta Prezzi di AWS IoT Device Management
È possibile che si verifichino più tentativi falliti quando un'elevata percentuale di soglia dei dispositivi scade o segnala un errore. In questo caso, puoi utilizzare la configurazione di interruzione per annullare il processo ed evitare eventuali esecuzioni del processo in coda o ulteriori tentativi.
Nota
Quando vengono soddisfatti i criteri di interruzione per l'annullamento dell'esecuzione di un processo, vengono annullate solo le esecuzioni del processo QUEUED. Gli eventuali tentativi in coda per il dispositivo non vengono effettuati. Tuttavia, le attuali esecuzioni del processo con stato IN_PROGRESS non vengono annullate.
Prima di ritentare l'esecuzione di un processo non riuscita, ti consigliamo di verificare anche se l'errore dell'esecuzione del processo è ritentabile, come descritto nella sezione seguente.
Nuovo tentativo per il tipo di errore FAILED
Per effettuare nuovi tentativi per il tipo di errore FAILED, i dispositivi devono essere programmati in modo da segnalare a AWS IoT lo stato FAILURE se l'esecuzione di un processo è fallita. Imposta la configurazione del nuovo tentativo specificando i criteri per ritentare le esecuzioni del processo FAILED e il numero di tentativi da effettuare. Quando AWS IoT Jobs rileva lo FAILURE stato, tenterà automaticamente di ripetere l'esecuzione del processo per il dispositivo. I nuovi tentativi continuano fino a quando l'esecuzione del processo non ha esito positivo o fino al raggiungimento del numero massimo di nuovi tentativi.
È possibile monitorare di ciascun nuovo tentativo e il processo in esecuzione su questi dispositivi. Monitorando lo stato di esecuzione, dopo avere effettuato il numero specificato di tentativi, puoi utilizzare il dispositivo per segnalare gli errori e avviare un nuovo tentativo.
Errori ritentabili e non ritentabili
Un errore di esecuzione del processo può essere ripetibile o non ripetibile. Ogni nuovo tentativo può comportare costi aggiuntivi per il tuo Account AWS. Per evitare addebiti aggiuntivi per l'esecuzione di molteplici nuovi tentativi, ti consigliamo innanzitutto di verificare se l'errore di esecuzione del processo è ritentabile. Ad esempio, è ripetibile un errore di connessione rilevato dal dispositivo durante il tentativo di effettuare il download del documento di processo da un URL Amazon S3. Se in base all’errore è possibile ritentare l’esecuzione del processo, puoi programmare il dispositivo in modo da segnalare lo stato di FAILURE nel caso in cui l'esecuzione del processo riceva un errore. Quindi, imposta la configurazione dei tentativi per ritentare le esecuzioni FAILED.
Se l'esecuzione del processo non può essere ritentata, per evitare di ripetere il tentativo e sostenere potenziali costi aggiuntivi sul tuo account, ti consigliamo di programmare il dispositivo in modo da segnalare lo stato REJECTED a AWS IoT. Esempi di errori non ritentabili sono i casi in cui il dispositivo non è compatibile con la ricezione di un aggiornamento del processo o quando si verifica un errore di memoria durante l'esecuzione di un processo. In questi casi, AWS IoT Jobs non ritenterà l'esecuzione del lavoro perché ritenta l'esecuzione del lavoro solo quando rileva uno stato or. FAILED TIMED_OUT
Dopo avere stabilito che un errore di esecuzione del processo è ritentabile, se il nuovo tentativo continua a non riuscire, prova a esaminare i registri del dispositivo.
Nota
Quando un processo con la configurazione di pianificazione opzionale raggiunge la sua endTime, il endBehavior selezionato interromperà l'implementazione del documento di processo in tutti i dispositivi rimanenti del gruppo di destinazione e indicherà come procedere con le esecuzioni del processo rimanenti. Per poter essere ripetuti, i tentativi devono essere selezionati tramite la configurazione dei nuovi tentativi.
Nuovo tentativo per il tipo di errore TIMEOUT
Se abiliti il timeout durante la creazione di un lavoro, AWS IoT Jobs tenterà di riprovare l'esecuzione del lavoro per il dispositivo quando lo stato cambia da a. IN_PROGRESS TIMED_OUT Questa modifica dello stato può verificarsi quando il timer in corso scade o quando un timer della fase specificato è in stato IN_PROGRESS e successivamente scade. I nuovi tentativi continuano fino a quando l'esecuzione del processo non ha esito positivo o fino al raggiungimento del numero massimo di nuovi tentativi per questo tipo di errore.
Processi continui e aggiornamenti dell'appartenenza a gruppi di oggetti
Per i processi continui con stato di processo IN_PROGRESS, il numero di nuovi tentativi viene azzerato quando l'appartenenza al gruppo di un oggetto viene aggiornata. Ad esempio, poniamo che tu abbia specificato cinque nuovi tentativi e tre tentativi siano già stati effettuati. Se un oggetto viene ora rimosso da un gruppo di oggetti e successivamente aggiunto di nuovo allo stesso gruppo, come nei gruppi di oggetti dinamici, il numero di nuovi tentativi viene azzerato. Ora per il tuo gruppo di oggetti puoi effettuare cinque tentativi invece dei due rimasti. Inoltre, quando un oggetto viene rimosso da un gruppo di oggetti, eventuali nuovi tentativi vengono annullati.
