Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Gestione delle autorizzazioni sui set di dati che utilizzano metastore esterni
Con la federazione dei AWS Glue Data Catalog metadati (Data Catalog federation), puoi connettere il Data Catalog a metastore esterni che archiviano i metadati per i tuoi dati Amazon S3 e gestire in modo sicuro le autorizzazioni di accesso ai dati utilizzando. AWS Lake Formation Non è necessario migrare i metadati dal metastore esterno al Data Catalog.
Il Data Catalog fornisce un archivio centralizzato di metadati che semplifica la gestione e la scoperta dei dati su sistemi diversi. Quando la tua organizzazione gestisce i dati nel catalogo dati, puoi utilizzarli AWS Lake Formation per controllare l'accesso ai tuoi set di dati in Amazon S3.
Nota
Attualmente, supportiamo solo la federazione dei metastore di Apache Hive (versione 3 e successive).
Per configurare la federazione di Data Catalog, forniamo un'applicazione AWS Serverless Application Model (AWS SAM) chiamata GlueDataCatalogFederation - in. HiveMetastore
L'implementazione di riferimento è fornita GitHub come progetto open source presso AWS Glue Data Catalog Federation - Hive Metastore
L' AWS SAM applicazione crea e distribuisce le seguenti risorse necessarie per connettere il Data Catalog al metastore Hive:
Una AWS Lambda funzione: ospita l'implementazione del servizio federativo che comunica tra il Data Catalog e il metastore Hive. AWS Glue richiama questa funzione Lambda per recuperare oggetti di metadati dal metastore Hive.
Amazon API Gateway— L'endpoint di connessione per il metastore Hive che funge da proxy per indirizzare tutte le chiamate alla funzione Lambda.
Un ruolo IAM: un ruolo con le autorizzazioni necessarie per creare la connessione tra il Data Catalog e il metastore Hive.
AWS Glue connessione: un Amazon API Gateway tipo di AWS Glue connessione che memorizza l' Amazon API Gateway endpoint e un ruolo IAM per richiamarlo.
Quando esegui una query sulle tabelle, il AWS Glue servizio effettua una chiamata di runtime al metastore Hive e recupera i metadati. La funzione Lambda funge da traduttore tra il metastore Hive e Data Catalog.
Dopo aver stabilito la connessione, per sincronizzare i metadati nel metastore Hive con il Data Catalog, è necessario creare un database federato nel Data Catalog utilizzando i dettagli di connessione del metastore Hive e mappare questo database al database Hive. Un database viene definito database federato quando punta a un'entità esterna al Data Catalog.
Puoi applicare le autorizzazioni di Lake Formation utilizzando il controllo degli accessi basato su tag e il metodo della risorsa denominata sul database federato e condividerlo tra più Account AWS unità organizzative (). AWS Organizations OUs Puoi anche condividere il database federato direttamente con i responsabili IAM di un altro account.
Puoi definire autorizzazioni dettagliate a livello di colonna, riga e cella utilizzando i filtri dati di Lake Formation sulle tabelle Hive esterne. Puoi usare Amazon Athena, Amazon Redshift o Amazon EMR per interrogare le tabelle Hive esterne gestite da Lake Formation.
Per ulteriori informazioni sulla condivisione e il filtraggio dei dati tra account, consulta:
Fasi di alto livello per la federazione dei metadati di Data Catalog
-
Crei utenti e ruoli IAM con le autorizzazioni appropriate per distribuire l' AWS SAM applicazione e creare database federati.
-
Registri la posizione dei dati di Amazon S3 con Lake Formation selezionando l'
Enable Data Catalog federationopzione per i set di dati che utilizzano un metastore Hive esterno. È possibile configurare le impostazioni AWS SAM dell'applicazione (nome della AWS Glue connessione, URL del metastore Hive e parametri della funzione Lambda) e distribuire l'applicazione. AWS SAM
-
L' AWS SAM applicazione distribuisce le risorse necessarie per connettere il metastore Hive esterno al Data Catalog.
-
Per applicare le autorizzazioni di Lake Formation al database e alle tabelle Hive, crei un database nel Data Catalog utilizzando i dettagli di connessione del metastore Hive e mappi questo database al database Hive.
Concedi le autorizzazioni sui database federati ai responsabili del tuo account o di un altro account.
Nota
Puoi connettere il Data Catalog a un mestastore Hive esterno, creare database federati ed eseguire query e script ETL su database e tabelle Hive senza applicare le autorizzazioni di Lake Formation. Per i dati di origine in Amazon S3 che non sono registrati con Lake Formation, l'accesso è determinato dalle politiche di autorizzazione IAM per Amazon S3 e dalle azioni. AWS Glue
Per le limitazioni, consulta I metadati di Hive archiviano: considerazioni e limitazioni sulla condivisione dei dati.
Argomenti
Flusso di lavoro
Il diagramma seguente mostra il flusso di lavoro per la connessione di un metastore AWS Glue Data Catalog Hive esterno.
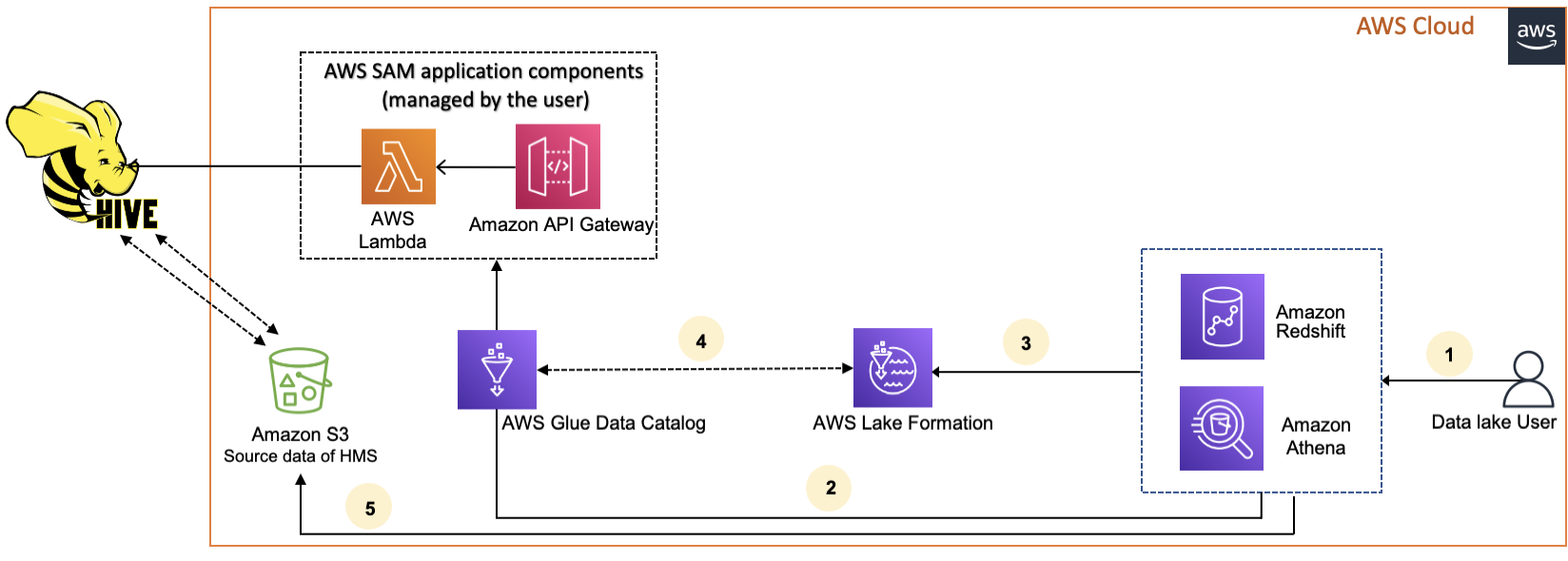
-
Un principale invia una richiesta utilizzando un servizio integrato come Athena o Redshift Spectrum.
Il servizio integrato effettua una chiamata al Data Catalog per i metadati, che a sua volta richiama l'endpoint Hive metastore disponibile e riceve risposte alle Amazon API Gateway richieste di metadati.
-
Il servizio integrato invia la richiesta a Lake Formation per verificare le informazioni sulla tabella e le credenziali per accedere alla tabella.
-
Lake Formation autorizza la richiesta e invia credenziali temporanee all'applicazione integrata, che consente l'accesso ai dati.
Utilizzando le credenziali temporanee ricevute da Lake Formation, il servizio integrato legge i dati da Amazon S3 e condivide i risultati con il responsabile.
