Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un flusso di lavoro
Prima di iniziare, assicurati di aver concesso al ruolo le autorizzazioni necessarie per i dati e le autorizzazioni per la localizzazione dei dati. LakeFormationWorkflowRole In questo modo il flusso di lavoro può creare tabelle di metadati nel Data Catalog e scrivere dati nelle posizioni di destinazione in Amazon S3. Per ulteriori informazioni, consultare (Facoltativo) Crea un ruolo IAM per i flussi di lavoro e Panoramica delle autorizzazioni di Lake Formation .
Nota
Lake Formation utilizza GetTemplateInstance e InstantiateTemplate opera per creare flussi di lavoro a partire dai progetti. GetTemplateInstances Queste operazioni non sono disponibili al pubblico e vengono utilizzate solo internamente per creare risorse per conto dell'utente. Ricevi CloudTrail eventi per la creazione di flussi di lavoro.
Per creare un flusso di lavoro da un blueprint
-
Apri la AWS Lake Formation console all'indirizzo https://console.aws.amazon.com/lakeformation/
. Accedi come amministratore del data lake o come utente con autorizzazioni di data engineer. Per ulteriori informazioni, consulta Riferimento ai personaggi di Lake Formation e alle autorizzazioni IAM. -
Nel riquadro di navigazione, scegli Blueprint, quindi scegli Usa blueprint.
-
Nella pagina Usa un blueprint, scegli un riquadro per selezionare il tipo di blueprint.
-
In Origine di importazione, specifica l'origine dati.
Se state importando da una fonte JDBC, specificate quanto segue:
-
Connessione al database: scegliere una connessione dall'elenco. Crea connessioni aggiuntive utilizzando la AWS Glue console. Il nome utente e la password JDBC nella connessione determinano gli oggetti del database a cui il flusso di lavoro ha accesso.
-
Percorso dei dati di origine: immettere
<database>/<schema>/<table>o<database>/<table>, a seconda del prodotto del database. Oracle Database e MySQL non supportano lo schema nel percorso. È possibile sostituire o con il carattere percentuale (%).<schema><table>Ad esempio, per un database Oracle con un identificatore di sistema (SID) diorcl, immettereorcl/%per importare tutte le tabelle a cui ha accesso l'utente indicato nella connessione.Importante
Questo campo distingue tra maiuscole e minuscole. Il flusso di lavoro avrà esito negativo in caso di mancata corrispondenza tra maiuscole e minuscole per uno qualsiasi dei componenti.
Se si specifica un database MySQL AWS Glue , ETL utilizza il driver JDBC Mysql5 per impostazione predefinita, quindi My non è supportato nativamente. SQL8 È possibile modificare lo script di lavoro ETL per utilizzare un
customJdbcDriverS3Pathparametro come descritto in JDBC ConnectionType Values nella AWS Glue Developer Guide per utilizzare un driver JDBC diverso che supporti My. SQL8
Se stai importando da un file di registro, assicurati che il ruolo specificato per il flusso di lavoro (il «ruolo del flusso di lavoro») disponga delle autorizzazioni IAM necessarie per accedere all'origine dati. Ad esempio, per importare AWS CloudTrail i log, l'utente deve disporre
cloudtrail:LookupEventsdelle autorizzazionicloudtrail:DescribeTrailse per visualizzare l'elenco dei CloudTrail log durante la creazione del flusso di lavoro e il ruolo del flusso di lavoro deve disporre delle autorizzazioni sulla posizione in CloudTrail Amazon S3. -
-
Esegui una di queste operazioni:
-
Per il tipo di blueprint Database snapshot, identifica facoltativamente un sottoinsieme di dati da importare specificando uno o più modelli di esclusione. Questi modelli di esclusione sono modelli in stile Unix.
globVengono memorizzati come proprietà delle tabelle create dal flusso di lavoro.Per i dettagli sui modelli di esclusione disponibili, consulta Includi ed escludi i modelli nella Guida per gli AWS Glue sviluppatori.
-
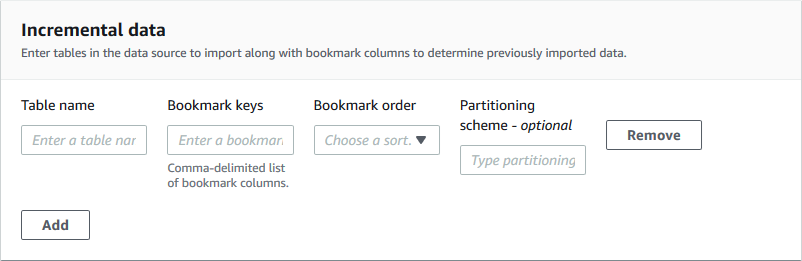
Per il tipo di blueprint del database incrementale, specificare i seguenti campi. Aggiungere una riga per ogni tabella da importare.
- Nome tabella
-
Tabella da importare. Deve essere tutto in minuscolo.
- Tasti per segnalibri
-
Elenco delimitato da virgole di nomi di colonne che definiscono le chiavi dei segnalibri. Se vuoto, la chiave primaria viene utilizzata per determinare nuovi dati. Le maiuscole e le minuscole per ogni colonna devono corrispondere a quelle definite nell'origine dati.
Nota
La chiave primaria si qualifica come chiave predefinita per i segnalibri solo se è crescente o decrescente in sequenza (senza spazi vuoti). Se desideri utilizzare la chiave primaria come chiave del segnalibro e presenta degli spazi vuoti, devi denominare la colonna della chiave primaria come chiave del segnalibro.
- Ordine dei segnalibri
-
Quando scegli Crescente, le righe con valori superiori ai valori contrassegnati dai segnalibri vengono identificate come nuove righe. Quando scegli Decrescente, le righe con valori inferiori ai valori contrassegnati dai segnalibri vengono identificate come nuove righe.
- Schema di partizionamento
-
(Facoltativo) Elenco delle colonne chiave di partizionamento, delimitate da barre (/). Esempio:.
year/month/day
Per ulteriori informazioni, consulta Tracciamento dei dati elaborati utilizzando i Job Bookmarks nella AWS Glue Developer Guide.
-
-
In Import target, specifica il database di destinazione, la posizione Amazon S3 di destinazione e il formato dei dati.
Assicurati che il ruolo del workflow disponga delle autorizzazioni Lake Formation richieste sul database e sulla posizione di destinazione di Amazon S3.
Nota
Attualmente, i blueprint non supportano la crittografia dei dati sulla destinazione.
-
Scegliete una frequenza di importazione.
È possibile specificare un'
cronespressione con l'opzione Personalizzata. -
In Opzioni di importazione:
-
Inserisci un nome per il flusso di lavoro.
-
Per ruolo, scegli il ruolo
LakeFormationWorkflowRolein cui hai creato(Facoltativo) Crea un ruolo IAM per i flussi di lavoro. -
Specificate facoltativamente un prefisso per la tabella. Il prefisso viene aggiunto ai nomi delle tabelle del catalogo dati create dal flusso di lavoro.
-
-
Scegli Crea e attendi che la console segnali che il flusso di lavoro è stato creato correttamente.
Suggerimento
Hai ricevuto il seguente messaggio di errore?
User: arn:aws:iam::<account-id>:user/<username>is not authorized to perform: iam:PassRole on resource:arn:aws:iam::<account-id>:role/<rolename>...In tal caso, verifica di aver inserito
<account-id>un numero di AWS account valido in tutte le politiche.
Consulta anche:
