Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Divisione dei dati
L'obiettivo fondamentale di un modello ML è fare previsioni accurate su future istanze di dati al di là di quelle usate per addestrare i modelli. Prima di utilizzare un modello ML per fare previsioni, è necessario valutare le prestazioni predittive del modello. Per stimare la qualità delle previsioni di un modello ML con dati che non abbia visto, è possibile prenotare o dividere una parte dei dati per i quali si conosce già la risposta come proxy per i dati futuri e valutare quanto sono precise le previsioni del modello ML riguardo alle risposte corrette per tali dati. È possibile ripartire l'origine dati tra un'origine dati di addestramento e un'origine dati di valutazione.
Amazon ML offre tre opzioni per suddividere i dati:
-
Suddividi in anticipo i dati: puoi suddividere i dati in due posizioni di input dei dati, prima di caricarli su Amazon Simple Storage Service (Amazon S3) e creare due origini dati separate con essi.
-
Divisione sequenziale di Amazon ML: puoi dire ad Amazon ML di suddividere i dati in sequenza durante la creazione delle origini dati di formazione e valutazione.
-
Divisione casuale di Amazon ML: puoi chiedere ad Amazon ML di suddividere i dati utilizzando un metodo casuale predefinito durante la creazione delle origini dati di formazione e valutazione.
Pre-divisione dei dati
Se si desidera un controllo esplicito sui dati delle origini dati di addestramento e di valutazione, è possibile dividere i dati in ubicazioni dati distinte e creare origini dati separate per l'ubicazione di input e quella di valutazione.
Divisione sequenziale dei dati
Un modo semplice per dividere i dati di input per l'addestramento e la valutazione è selezionare sottoinsiemi non sovrapposti dei dati mantenendo l'ordine dei record dei dati. Questo approccio è utile se si desidera valutare i modelli ML sui dati per una determinata data o all'interno di un determinato intervallo di tempo. Ad esempio, supponiamo di avere a disposizione i dati relativi al coinvolgimento dei clienti negli ultimi cinque mesi e di volere utilizzare questi dati storici per prevedere il coinvolgimento dei clienti nel mese successivo. L'uso dell'inizio dell'intervallo per l'addestramento e dei dati dalla fine dell'intervallo per la valutazione potrebbe produrre una stima più precisa della qualità del modello rispetto all'utilizzo di record di dati provenienti dall'intero intervallo di dati.
La figura seguente mostra esempi di quando è preferibile utilizzare una strategia di divisione sequenziale rispetto a una strategia casuale.
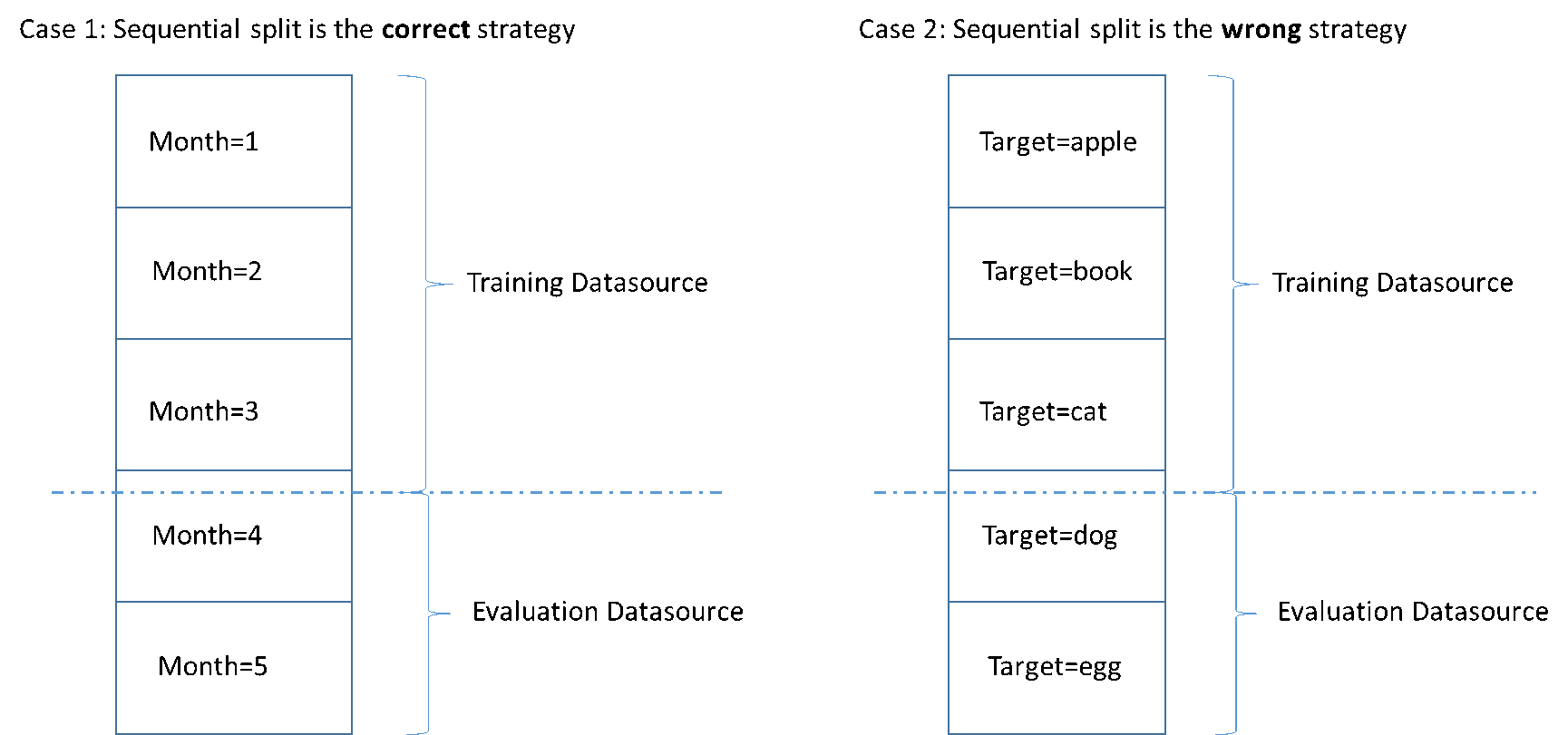
Quando crei un'origine dati, puoi scegliere di suddividerla in sequenza e Amazon ML utilizza il primo 70 percento dei dati per la formazione e il restante 30 percento dei dati per la valutazione. Questo è l'approccio predefinito quando usi la console Amazon ML per dividere i dati.
Divisione casuale dei dati
La divisione casuale dei dati di input in origini dati per l'addestramento e per la valutazione garantisce che la distribuzione dei dati sia simile per le origini dati di addestramento e di valutazione. Si sceglie questa opzione quando non è necessario conservare l'ordine dei dati di input.
Amazon ML utilizza un metodo predefinito di generazione di numeri pseudo-casuali per suddividere i dati. La partenza si basa parzialmente su un valore di stringa di input e parzialmente sul contenuto degli stessi dati. Per impostazione predefinita, la console Amazon ML utilizza la posizione S3 dei dati di input come stringa. Gli utenti API possono fornire una stringa personalizzata. Ciò significa che, con lo stesso bucket S3 e gli stessi dati, Amazon ML divide i dati sempre nello stesso modo. Per modificare il modo in cui Amazon ML divide i dati, puoi utilizzare l'CreateDatasourceFromRDSAPI CreateDatasourceFromS3CreateDatasourceFromRedshift, o e fornire un valore per la stringa seed. Quando li utilizzi per APIs creare origini dati separate per la formazione e la valutazione, è importante utilizzare lo stesso valore della stringa iniziale per entrambe le origini dati e il flag di complemento per un'origine dati, per garantire che non vi siano sovrapposizioni tra i dati di formazione e di valutazione.
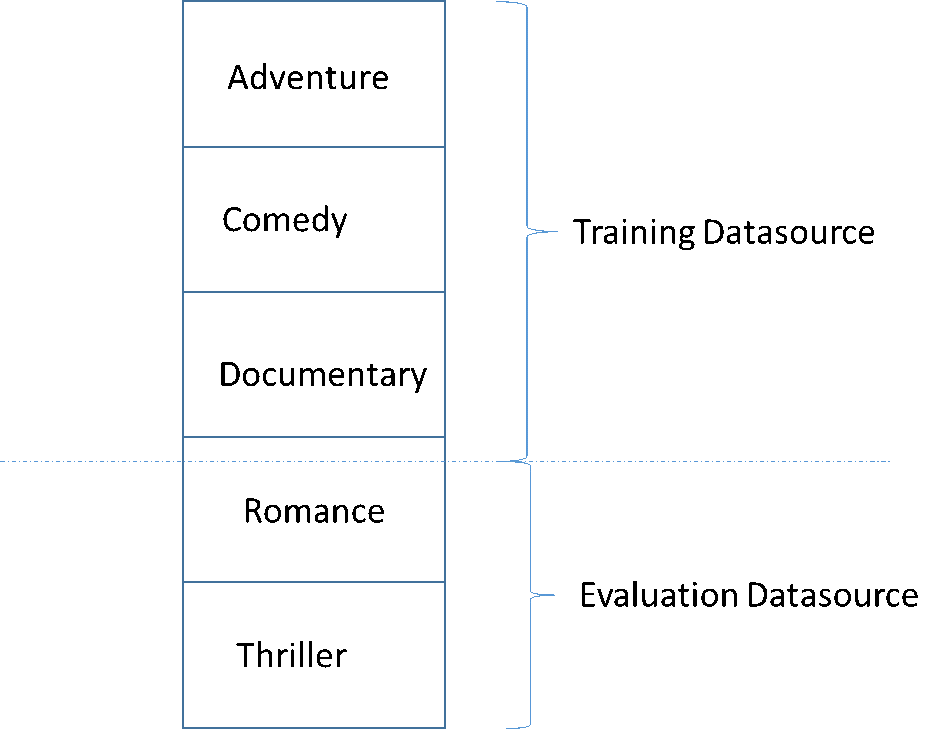
Un problema comune nello sviluppo di un modello di ML di alta qualità è valutare il modello ML su dati che non siano simili a quelli utilizzati per l'addestramento. Ad esempio, supponiamo di utilizzare ML per prevedere il genere dei film e che i dati di addestramento contengano film dei generi Avventura, Commedia e Documentario. Tuttavia, i dati di valutazione contengono solo i dati dei generi Romantico e Thriller. In questo caso, il modello ML non apprende le informazioni sui generi Romantico e Thriller e la valutazione non consente di capire quanto è elevata la qualità delle prestazioni di apprendimento del modello per i generi Avventura, Commedia e Documentario. Di conseguenza, le informazioni sul genere sono inutili e la qualità delle previsioni del modello ML per tutti i generi è compromessa. Il modello e la valutazione sono troppo diversi (hanno statistiche descrittive estremamente diverse) per essere utili. Questo può accadere quando i dati di input sono ordinati per una delle colonne del set di dati e quindi divisi sequenzialmente.
Se le origini dati di addestramento e di valutazione hanno diverse distribuzioni dei dati, verrà visualizzato un avviso di valutazione nel modello di valutazione. Per ulteriori informazioni sugli avvisi di valutazione, consultare Avvisi relativi alla valutazione.
Non è necessario utilizzare la suddivisione casuale in Amazon ML se hai già randomizzato i dati di input, ad esempio mescolando casualmente i dati di input in Amazon S3 o utilizzando una funzione di query SQL di Amazon Redshift o una random() funzione di query SQL MySQL durante la creazione delle origini dati. rand() In questi casi, è possibile utilizzare l'opzione di divisione sequenziale per creare origini dati di addestramento e valutazione con distribuzioni simili.
