Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase 2. Creare un'origine dati di addestramento
Dopo aver caricato il banking.csv set di dati nella tua posizione Amazon Simple Storage Service (Amazon S3), lo usi per creare un'origine dati di formazione. Un'origine dati è un oggetto Amazon Machine Learning (Amazon ML) che contiene la posizione dei dati di input e metadati importanti sui dati di input. Amazon ML utilizza l'origine dati per operazioni come la formazione e la valutazione dei modelli ML.
Per creare un'origine dati, è necessario fornire quanto segue:
-
Ubicazione dei dati in Amazon S3 e autorizzazione ad accedere ai dati
-
Lo schema, che include i nomi degli attributi dei dati e il tipo di ogni attributo (Numeric, Text, Categorical o Binary)
-
Il nome dell'attributo che contiene la risposta che vuoi che Amazon ML impari a prevedere, l'attributo target
Nota
Nell'origine dati non vengono memorizzati i dati, ma solo i riferimenti ad essi. Evita di spostare o modificare i file archiviati in Amazon S3. Se li sposti o li modifichi, Amazon ML non può accedervi per creare un modello di machine learning, generare valutazioni o generare previsioni.
Per creare un'origine dati di addestramento
Apri la console Amazon Machine Learning all'indirizzo https://console.aws.amazon.com/machinelearning/
. -
Scegli Avvia.
Nota
Questo tutorial presuppone che sia la prima volta che utilizzi Amazon ML. Se hai già utilizzato Amazon ML, puoi utilizzare il comando Crea nuovo... elenco a discesa nella dashboard di Amazon ML per creare una nuova origine dati.
-
Nella pagina Guida introduttiva ad Amazon Machine Learning, scegli Launch.
-
Nella pagina Input Data (Dati di input), per Where is your data located? (Dove si trovano i tuoi dati?), assicurarsi che sia stato selezionato S3.

-
Per S3 Location (Posizione S3), digitare il percorso completo del file
banking.csvdella Fase 1. Preparare i dati. Ad esempio:your-bucket/banking.csv. Amazon ML aggiunge s3://al tuo nome del bucket. -
Per Datasource name (Nome origine dati), digitare
Banking Data 1.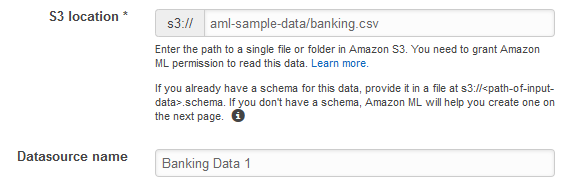
-
Selezionare Verify (Verifica).
-
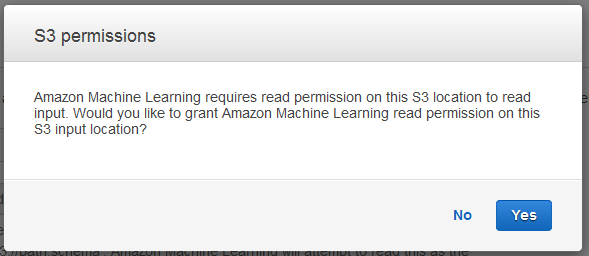
Nella finestra di dialogo S3 permissions (Autorizzazioni S3), scegliere Yes (Sì).
-
Se Amazon ML è in grado di accedere e leggere il file di dati nella posizione S3, verrà visualizzata una pagina simile alla seguente. Verificare le proprietà e scegliere Continue (Continua).

Dopo occorre stabilire uno schema. Uno schema è l'informazione di cui Amazon ML ha bisogno per interpretare i dati di input per un modello ML, inclusi i nomi degli attributi e i tipi di dati assegnati e i nomi degli attributi speciali. Esistono due modi per fornire ad Amazon ML uno schema:
-
Fornisci un file di schema separato quando carichi i dati di Amazon S3.
-
Consenti ad Amazon ML di dedurre i tipi di attributi e creare uno schema per te.
In questo tutorial, chiederemo ad Amazon ML di dedurre lo schema.
Per informazioni sulla creazione di un file di schema separato, consultare Creazione di uno schema di dati per Amazon ML.
Per consentire ad Amazon ML di dedurre lo schema
-
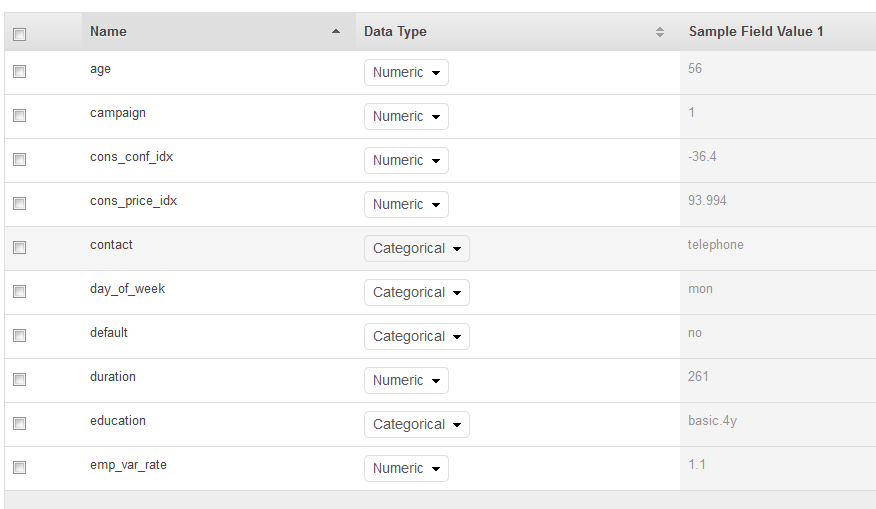
Nella pagina Schema, Amazon ML mostra lo schema che ha dedotto. Esamina i tipi di dati che Amazon ML ha dedotto per gli attributi. È importante che agli attributi venga assegnato il tipo di dati corretto per consentire ad Amazon ML di assimilare correttamente i dati e consentire la corretta elaborazione delle funzionalità sugli attributi.
-
Gli attributi che hanno solo due stati possibili, come ad esempio sì o no, devono essere contrassegnati come Binary (Binario).
-
Gli attributi che sono numeri o stringhe utilizzati per denotare una categoria devono essere contrassegnati come Categorical (Categorico).
-
Gli attributi che sono quantità numeriche per le quali l'ordine è significativo devono essere contrassegnati come Numeric (Numerico).
-
Gli attributi che sono stringhe che si desidera trattare come parole delimitate da spazi devono essere contrassegnati come Text (Testo).
-
-
In questo tutorial, Amazon ML ha identificato correttamente i tipi di dati per tutti gli attributi, quindi scegli Continua.
Quindi, selezionare un attributo di destinazione.
Ricordare che la destinazione è l'attributo che il modello ML deve imparare a prevedere. L'attributo y indica se un singolo ha aderito a una campagna in passato: 1 (sì) o 0 (no).
Nota
Scegliere un attributo di destinazione solo se si utilizza l'origine dati per l'addestramento e la valutazione di modelli ML.
Per selezionare y come attributo di destinazione
-
In basso a destra nella tabella, scegliere la freccia singola per passare all'ultima pagina della tabella, dove è visualizzato l'attributo denominato
y.
-
Nella colonna Target (Destinazione), selezionare
y.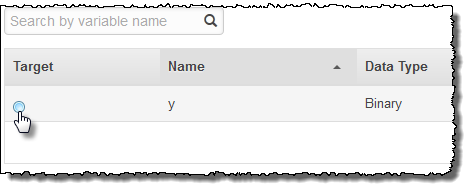
Amazon ML conferma che y è selezionato come obiettivo.
-
Scegli Continua.
-
Nella pagina Row ID (ID riga) per Does your data contain an identifier? (I dati contengono un identificatore?), assicurarsi che sia selezionata l'impostazione predefinita No.
-
Selezionare Review (Rivedi), quindi Continue (Continua).
Ora che si dispone di un'origine dati di addestramento, è possibile creare il proprio modello.
