Amazon Managed Service for Apache Flink (Amazon MSF) era precedentemente noto come Amazon Kinesis Data Analytics for Apache Flink.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Checkpoint
I checkpoint rappresentano il meccanismo di Flink per garantire che lo stato di un'applicazione sia in grado di tollerare eventuali errori. Questo meccanismo consente a Flink di ripristinare lo stato degli operatori in caso di errori del processo, nonché di fornire all'applicazione le semantiche di un'esecuzione senza errori. Con il servizio gestito per Apache Flink, lo stato di un'applicazione viene archiviato in RocksDB, un archivio chiave-valore integrato il cui stato operativo opera su disco. Quando viene eseguito un checkpoint, lo stato viene caricato anche su Amazon S3: anche se il disco viene perso, pertanto, il checkpoint può essere utilizzato per ripristinare lo stato delle applicazioni.
Per ulteriori informazioni consulta la sezione Come funzionano gli snapshot dello stato?
Fasi di checkpoint
Le fasi principali di un'attività secondaria per effettuare il checkpoint di un operatore in Flink sono 5:
In attesa [Ritardo di avvio]: Flink utilizza le barriere di checkpoint inserite nel flusso: in questa fase, pertanto, il tempo è il periodo di attesa dell'operatore prima che la barriera del checkpoint lo raggiunga.
Allineamento [Durata dell'allineamento]: in questa fase l'attività secondaria ha raggiunto una barriera ma è in attesa delle barriere provenienti da altri flussi di input.
Sincronizzazione del checkpoint [Durata della sincronizzazione]: in questa fase l'attività secondaria effetto uno snapshot dello stato dell'operatore e blocca tutte le altre attività presenti sulla'attività secondaria.
Checkpoint asincrono [Durata asincrona]: questa fase consiste in gran parte caricamento dello stato su Amazon S3 da parte dell'attività secondaria. Durante questa fase, l'attività secondaria non è più bloccata e può elaborare i record.
Riconoscimento: di solito è una fase breve ed è semplicemente la sottoattività che invia una conferma JobManager e esegue anche eventuali messaggi di commit (ad esempio con i sinks di Kafka).
Ciascuna di queste fasi (esclusa Riconoscimento) corrisponde a un parametro di durata per i checkpoint disponibile nell'interfaccia utente Web di Flink, che può aiutare a individuare la causa del prolungamento delle tempistiche del checkpoint.
Per vedere la definizione esatta di ciascuna delle metriche disponibili sui checkpoint, visita la scheda Cronologia
Analisi
Quando si esamina la durata prolungata di un checkpoint, l'elemento più importante da determinare è il collo di bottiglia del checkpoint, vale a dire quale operatore e attività secondaria impiega la quantità maggiore di tempo ad arrivare al checkpoint e quale fase di tale attività secondaria richiede un periodo di tempo prolungato. Può essere determinato utilizzando l'interfaccia utente Web di Flink nell'attività di checkpoint dei processi. L'interfaccia web di Flink fornisce dati e informazioni che aiutano a risolvere le problematiche relative ai checkpoint. Per un'analisi completa, consulta Monitoraggio dei checkpoint
Per determinare quale operatore richiede una quantità di tempo prolungata per arrivare al checkpoint e merita approfondimenti, il primo elemento da esaminare è la durata end-to-end di ogni operatore nel grafico del processo. Conformemente alla documentazione di Flink, la definizione della durata è:
La durata a partire dal timestamp del trigger fino all'ultimo riconoscimento (o n/a se non è stato ancora ricevuto nessun riconoscimento). La durata end-to-end di un checkpoint completo è determinata dall'ultima attività secondaria che riconosce il checkpoint. Tale periodo è generalmente superiore a quello di cui le attività secondarie necessitano per effettuare la verifica dello stato.
Le diverse durate della verifica forniscono inoltre informazioni più dettagliate relativamente agli aspetti che richiedono più tempo.
Una durata della sincronizzazione elevata indica problematiche nel corso dello scatto dello snapshot. In questa fase snapshotState() è attivato per le classi che implementano l'interfaccia snapshotState; può trattarsi di codice utente, quindi i thread dump possono essere utili per indagare su questo aspetto.
Una durata asincrona prolungata suggerirebbe che il caricamento dello stato su Amazon S3 richiede una quantità di tempo prolungata. Ciò può verificarsi se le dimensioni dello stato sono importanti o se vengono caricati diversi file di stato. In tal caso, è consigliabile analizzare l'utilizzo dello stato da parte dall'applicazione, nonché assicurarsi che, dove possibile, vengano utilizzate le strutture di dati native di Flink (Utilizzare Keyed State
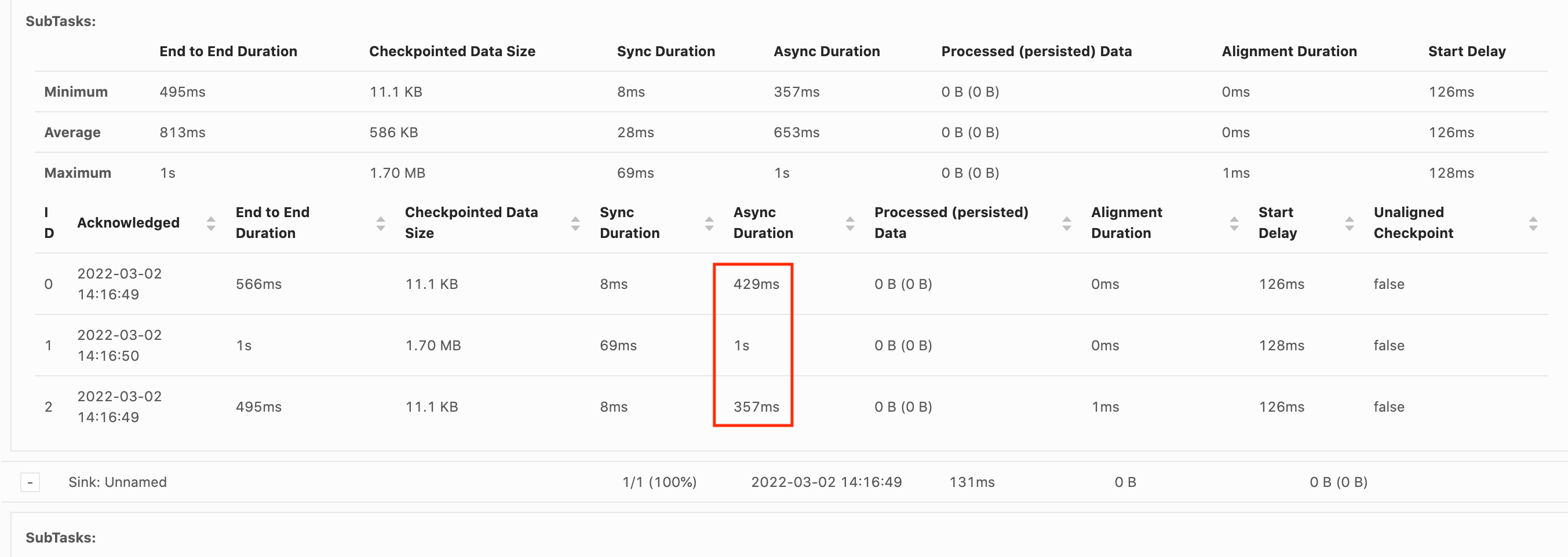
Un ritardo di avvio elevato indicherebbe che la maggior parte del tempo viene impiegata ad aspettare che la barriera del checkpoint raggiunga l'operatore. Ciò indica che l'applicazione impiega un periodo di tempo superiore per elaborare i record, il che significa che la barriera scorre lentamente attraverso il grafico del processo. Tale situazione si verficia se il processo è soggetto a contropressione o se uno o più operatori sono costantemente occupati. Di seguito è riportato un esempio di un caso in cui il secondo operatore è occupato JobGraph . KeyedProcess
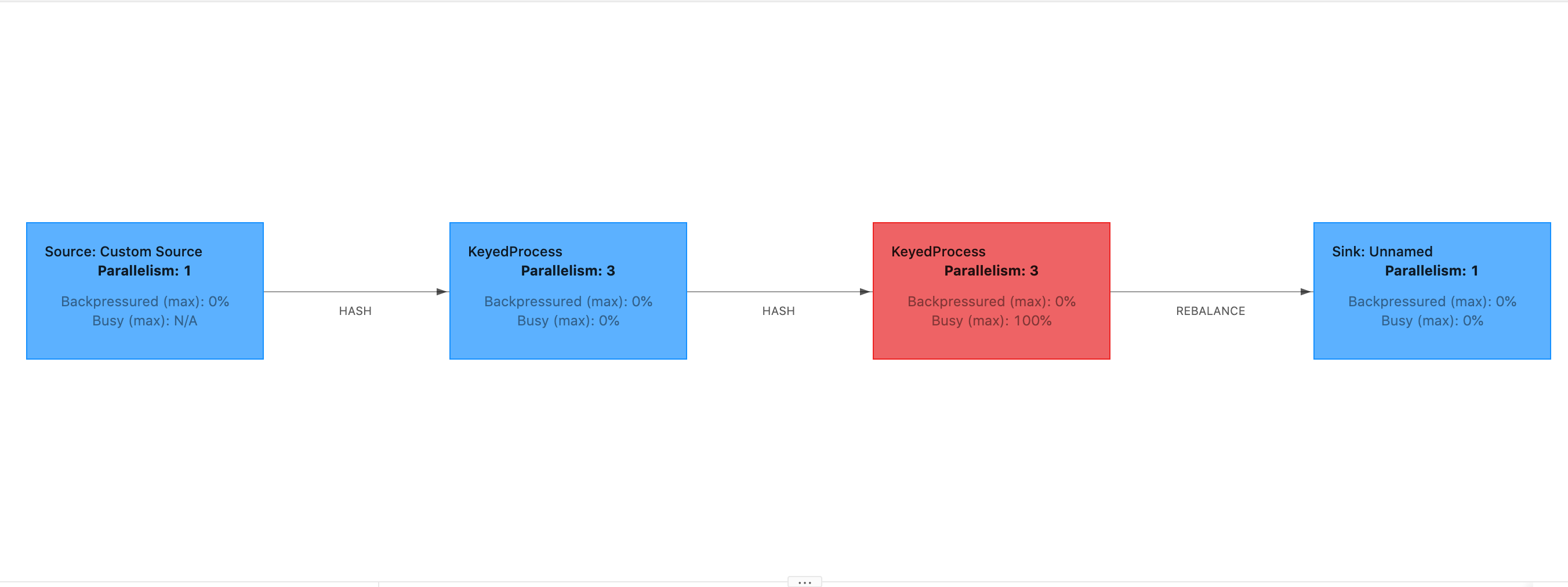
Puoi indagare su cosa sta impiegando così tanto tempo utilizzando Flink Flame Graphs o TaskManager i thread dump. Una volta identificata la problematica, è possibile analizzarla ulteriormente utilizzando i grafici a fiamma o i thread dump.
Thread dump
I thread dump sono uno strumento di debug che si trova a un livello leggermente inferiore rispetto ai grafici a fiamma. Un thread dump restituisce lo stato di esecuzione di tutti i thread in un determinato momento. Flink esegue un thread dump JVM, ossia uno stato di esecuzione di tutti i thread all'interno del processo Flink. Lo stato di un thread è rappresentato da una traccia dello stack del thread, insieme ad alcune informazioni aggiuntive. I grafici a fiamma vengono creati utilizzando diverse stack trace in rapida successione. Il grafico è una visualizzazione composta dalle stack trace, che semplifica l'identificazione dei percorsi di codice comuni.
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Qui sopra è riportato un frammento di un thread dump tratto dall'interfaccia utente di Flink per un singolo thread. La prima riga contiene alcune informazioni generali su questo thread, tra cui:
Il nome KeyedProcess del thread (1/3) #0
Priorità del thread prio=5
Un thread unico Id = 1423
Stato del thread ESEGUIBILE
Il nome di un thread solitamente fornisce informazioni sul suo scopo generale. I thread degli operatori possono essere identificati dal loro nome poiché i thread dell'operatore hanno lo stesso nome dell'operatore, oltre all'indicazione della sottoattività a cui sono correlati, ad esempio, il thread KeyedProcess (1/3) #0 proviene dall'KeyedProcessoperatore e proviene dalla prima sottoattività (su 3).
I thread possono trovarsi in uno dei seguenti stati:
NUOVO: il thread è stato creato ma non è ancora stato elaborato
ESEGUIBILE: il thread è in esecuzione sulla CPU
BLOCCATO: il thread è in attesa che un altro thread rilasci il blocco
IN ATTESA: il thread è in attesa e utilizza un metodo
wait(),join()opark()ATTESA_A TEMPO: il thread è in attesa con un metodo di sospensione, attesa, collegamento o prenotazione, ma con un tempo di attesa massimo.
Nota
La profondità massima di un singolo stacktrace nel thread dump su Flink 1.13 è limitata a 8.
Nota
I thread dump dovrebbero rappresentare l'ultima soluzione per il debug dei problemi relativi alle prestazioni in un'applicazione Flink, poiché possono essere complessi da leggere, richiedono l'acquisizione di più campioni e l'analisi manuale. Ove possibile, è preferibile utilizzare i grafici a fiamma.
Thread dump su Flink
Su Flink è possibile eseguire un thread dump scegliendo l'opzione Task Manager nella barra di navigazione a sinistra dell'interfaccia utente di Flink, selezionando un determinato task manager e accedendo alla scheda Thread dump. Il thread dump può essere scaricato, copiato in un editor di testo (o in un analizzatore di thread dump) o analizzato direttamente all'interno della visualizzazione di testo nell'interfaccia utente Web di Flink; quest'ultima opzione, però, potrebbe risultare macchinosa.
Per determinare quale Task Manager utilizzare, è possibile utilizzare un thread dump della TaskManagersscheda quando si sceglie un particolare operatore. Ciò dimostra che l'operatore è in esecuzione su diverse attività secondarie di un operatore e può essere eseguito su diversi Task Manager.

Il dump sarà composto da diverse stack trace. Quando si esamina il dump, tuttavia, i più importanti sono quelli relativi a un operatore. Possono essere individuati facilmente, poiché i thread degli operatori hanno lo stesso nome dell'operatore, oltre a un'indicazione dell'attività secondaria a cui sono legati. Ad esempio, la seguente traccia dello stack proviene dall'KeyedProcessoperatore ed è la prima sottoattività.
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Questo può creare confusione se ci sono più operatori con lo stesso nome, tuttavia per aggirare il problema è possibile rinominare gli operatori. Per esempio:
.... .process(new ExpensiveFunction).name("Expensive function")
Grafici a fiamma
I grafici a fiamma sono uno strumento per il debug che consente di visualizzare le stack trace del codice di destinazione, il che consente di identificare i percorsi di codice più frequenti. Vengono creati campionando più volte le stack trace. L'asse x di un grafico a fiamma mostra i diversi profili dello stack, mentre l'asse y mostra la profondità dello stack e ne richiama la stack trace. Un rettangolo in un grafico a fiamma rappresenta uno stack frame, mentre la larghezza di un riquadro mostra la frequenza con cui compare negli stack. Per ulteriori dettagli sui grafici a fiamma e su come usarli, consulta Grafici a fiamma
In Flink, è possibile accedere al grafico a fiamma di un operatore tramite l'interfaccia utente Web selezionando un operatore e quindi scegliendo la scheda. FlameGraph Una volta raccolto un numero sufficiente di campioni, verrà visualizzato il grafico a fiamma. Di seguito è riportato il messaggio ProcessFunction che ha impiegato molto tempo FlameGraph per arrivare al checkpoint.

Questo è un grafico a fiamma molto semplice e mostra che tutto il tempo impiegato dalla CPU viene speso in un'unica occhiata all'interno processElement dell'operatore. ExpensiveFunction È inoltre possibile ottenere il numero di riga, per determinare la posizione esatta in cui avviene l'esecuzione del codice.
