Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Caratteristiche e limiti della ricerca vettoriale
Disponibilità della ricerca vettoriale
La configurazione MemoryDB abilitata alla ricerca vettoriale è supportata sui tipi di nodi R6g, R7g e T4g ed è disponibile in tutte le regioni in cui è disponibile MemoryDB. AWS
I cluster esistenti non possono essere modificati per abilitare la ricerca. Tuttavia, i cluster abilitati alla ricerca possono essere creati da istantanee di cluster con la ricerca disattivata.
Restrizioni parametriche
La tabella seguente mostra i limiti per vari elementi di ricerca vettoriale:
| Elemento | Valore massimo |
|---|---|
| Numero di dimensioni in un vettore | 32768 |
| Numero di indici che possono essere creati | 10 |
| Numero di campi in un indice | 50 |
| Clausole FT.SEARCH e FT.AGGREGATE TIMEOUT (millisecondi) | 10000 |
| Numero di fasi della pipeline nel comando FT.AGGREGATE | 32 |
| Numero di campi nella clausola FT.AGGREGATE LOAD | 1.024 |
| Numero di campi nella clausola FT.AGGREGATE GROUPBY | 16 |
| Numero di campi nella clausola FT.AGGREGATE SORTBY | 16 |
| Numero di parametri nella clausola FT.AGGREGATE PARAM | 32 |
| Parametro HNSW M | 512 |
| Parametro HNSW EF_CONSTRUCTION | 4096 |
| Parametro HNSW EF_RUNTIME | 4096 |
Limiti di scalabilità
La ricerca vettoriale per MemoryDB è attualmente limitata a un singolo frammento e la scalatura orizzontale non è supportata. La ricerca vettoriale supporta il ridimensionamento verticale e di replica.
Restrizioni operative
Persistenza e riempimento dell'indice
La funzione di ricerca vettoriale mantiene la definizione degli indici e il contenuto dell'indice. Ciò significa che durante qualsiasi richiesta o evento operativo che causa l'avvio o il riavvio di un nodo, la definizione e il contenuto dell'indice vengono ripristinati dall'istantanea più recente e tutte le transazioni in sospeso vengono lette dal registro delle transazioni Multi-AZ. Non è richiesta alcuna azione da parte dell'utente per avviare questa operazione. La ricostruzione viene eseguita come operazione di riempimento non appena i dati vengono ripristinati. Dal punto di vista funzionale, ciò equivale all'esecuzione automatica da parte del sistema di un comando FT.CREATE per ogni indice definito. Si noti che il nodo diventa disponibile per le operazioni dell'applicazione non appena i dati vengono ripristinati, ma probabilmente prima del completamento del riempimento dell'indice, il che significa che i backfill diventeranno nuovamente visibili alle applicazioni; ad esempio, i comandi di ricerca che utilizzano gli indici di riempimento potrebbero essere rifiutati. Per ulteriori informazioni sul backfilling, vedere. Panoramica della ricerca vettoriale
Il completamento del riempimento dell'indice non è sincronizzato tra un primario e una replica. Questa mancanza di sincronizzazione può diventare inaspettatamente visibile alle applicazioni, pertanto è consigliabile che le applicazioni verifichino il completamento del backfill sui file primari e su tutte le repliche prima di iniziare le operazioni di ricerca.
Istantanea e migrazione in tempo reale import/export
La presenza di indici di ricerca in un file RDB limita la trasportabilità compatibile di tali dati. Il formato degli indici vettoriali definiti dalla funzionalità di ricerca vettoriale di MemoryDB è compreso solo da un altro cluster abilitato ai vettori di MemoryDB. Inoltre, i file RDB dei cluster di anteprima possono essere importati dalla versione GA dei cluster MemoryDB, che ricostruirà il contenuto dell'indice durante il caricamento del file RDB.
Tuttavia, i file RDB che non contengono indici non sono soggetti a restrizioni in questo modo. Pertanto i dati all'interno di un cluster di anteprima possono essere esportati in cluster non di anteprima eliminando gli indici prima dell'esportazione.
Consumo di memoria
Il consumo di memoria si basa sul numero di vettori, sul numero di dimensioni, sul valore M e sulla quantità di dati non vettoriali, come i metadati associati al vettore o altri dati memorizzati all'interno dell'istanza.
La memoria totale richiesta è una combinazione dello spazio necessario per i dati vettoriali effettivi e dello spazio richiesto per gli indici vettoriali. Lo spazio richiesto per i dati vettoriali viene calcolato misurando la capacità effettiva richiesta per archiviare i vettori all'interno di strutture di dati HASH o JSON e il sovraccarico delle lastre di memoria più vicine, per allocazioni di memoria ottimali. Ciascuno degli indici vettoriali utilizza riferimenti ai dati vettoriali memorizzati in queste strutture di dati e utilizza ottimizzazioni di memoria efficienti per rimuovere eventuali copie duplicate dei dati vettoriali nell'indice.
Il numero di vettori dipende da come decidete di rappresentare i dati come vettori. Ad esempio, puoi scegliere di rappresentare un singolo documento in più blocchi, in cui ogni blocco rappresenta un vettore. In alternativa, puoi scegliere di rappresentare l'intero documento come un unico vettore.
Il numero di dimensioni dei vettori dipende dal modello di incorporamento scelto. Ad esempio, se scegli di utilizzare il modello di incorporamento AWS Titan
Il parametro M rappresenta il numero di link bidirezionali creati per ogni nuovo elemento durante la costruzione dell'indice. Il valore predefinito di MemoryDB è 16; tuttavia, è possibile sovrascriverlo. Un parametro M più alto funziona meglio per requisiti di richiamo elevati ad and/or alta dimensionalità, mentre parametri M bassi funzionano meglio per requisiti di richiamo bassi. and/or Il valore M aumenta il consumo di memoria man mano che l'indice aumenta, aumentando il consumo di memoria.
Nell'esperienza della console, MemoryDB offre un modo semplice per scegliere il tipo di istanza giusto in base alle caratteristiche del carico di lavoro vettoriale dopo aver selezionato Abilita la ricerca vettoriale nelle impostazioni del cluster.
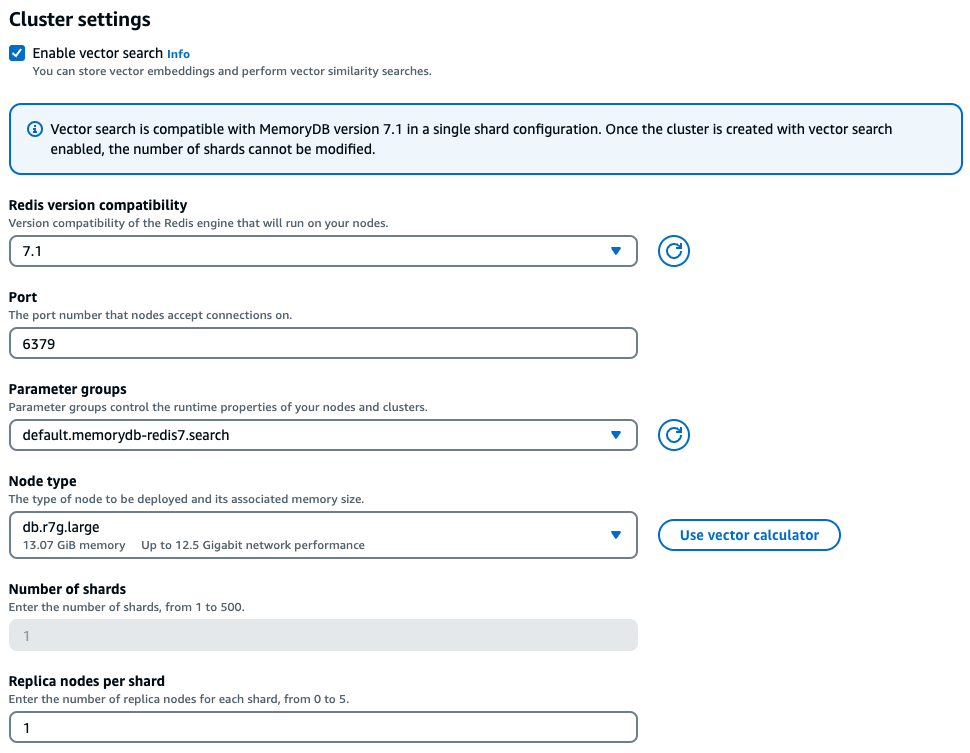
Esempio di carico di lavoro
Un cliente desidera creare un motore di ricerca semantico basato sui propri documenti finanziari interni. Attualmente detengono 1 milione di documenti finanziari suddivisi in 10 vettori per documento utilizzando il modello di incorporamento Titan con 1536 dimensioni e non contengono dati non vettoriali. Il cliente decide di utilizzare il valore predefinito di 16 come parametro M.
Vettori: 1 M * 10 blocchi = 10 milioni di vettori
Dimensioni: 1536
Dati non vettoriali (GB): 0 GB
Parametro M: 16
Con questi dati, il cliente può fare clic sul pulsante Usa calcolatrice vettoriale all'interno della console per ottenere un tipo di istanza consigliato in base ai relativi parametri:
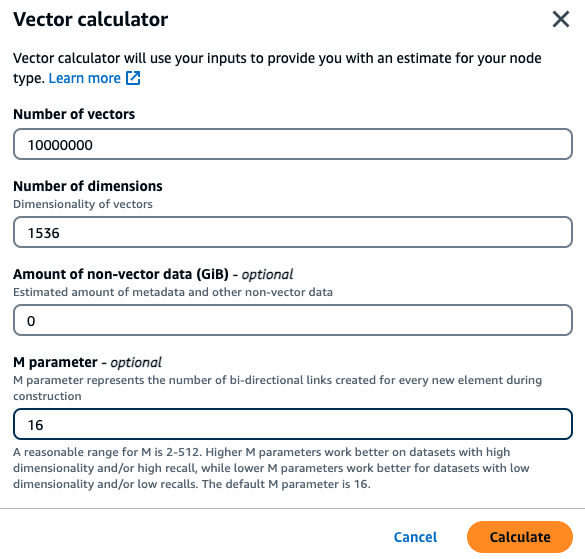

In questo esempio, la calcolatrice vettoriale cercherà il tipo di nodo MemoryDB r7g
In base al metodo di calcolo sopra riportato e ai parametri del carico di lavoro di esempio, questi dati vettoriali richiederebbero 104,9 GB per archiviare i dati e un singolo indice. In questo caso, il tipo di db.r7g.4xlarge istanza è consigliato in quanto dispone di 105,81 GB di memoria utilizzabile. Il successivo tipo di nodo più piccolo sarebbe troppo piccolo per contenere il carico di lavoro vettoriale.
Poiché ciascuno degli indici vettoriali utilizza riferimenti ai dati vettoriali memorizzati e non crea copie aggiuntive dei dati vettoriali nell'indice vettoriale, gli indici occuperanno anche uno spazio relativamente inferiore. Ciò è molto utile per creare più indici e anche in situazioni in cui parti dei dati vettoriali sono state eliminate e la ricostruzione del grafico HNSW aiuterebbe a creare connessioni tra i nodi ottimali per risultati di ricerca vettoriali di alta qualità.
Memoria insufficiente durante il riempimento
Analogamente alle operazioni di scrittura di Valkey e Redis OSS, un riempimento dell'indice è soggetto a limitazioni. out-of-memory Se la memoria del motore è piena mentre è in corso un riempimento, tutti i riempimenti vengono messi in pausa. Se la memoria diventa disponibile, il processo di riempimento viene ripreso. È anche possibile eliminare e indicizzare quando il riempimento è in pausa a causa dell'esaurimento della memoria.
Transazioni
I comandiFT.CREATE,, FT.DROPINDEX FT.ALIASADDFT.ALIASDEL, e FT.ALIASUPDATE non possono essere eseguiti in un contesto transazionale, cioè non all'interno di un MULTI/EXEC blocco o all'interno di uno script LUA o FUNCTION.
