Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Nozioni di base su Amazon Neptune
Amazon Neptune è un servizio di database a grafo completamente gestito e scalabile per gestire miliardi di relazioni e consente di eseguire query su di esse con una latenza di millisecondi, a un costo contenuto per tale tipo di capacità.
Per informazioni più dettagliate su Neptune, consulta Panoramica delle funzionalità di Amazon Neptune.
Se hai già familiarità con i grafi, passa a Usare Neptune con quaderni a grafi. Oppure, se desideri creare subito un database Neptune, consulta Creazione di un cluster Amazon Neptune utilizzando AWS CloudFormation.
In caso contrario, puoi approfondire i concetti relativi ai database a grafo prima di iniziare.
Concetti chiave del database grafico
I database a grafo sono ottimizzati per archiviare le relazioni tra gli elementi di dati ed eseguire query su di esse.
Archiviano gli elementi di dati stessi come vertici del grafo e le relazioni tra di essi come archi. Ogni arco è di un tipo specifico ed è diretto da un vertice (l'inizio) all'altro (la fine). Le relazioni possono essere denominate predicati oltre che archi e i vertici vengono talvolta chiamati anche nodi. Nei cosiddetti grafi di proprietà, sia ai vertici che agli archi possono essere associate anche proprietà aggiuntive.
Ecco un piccolo grafo che rappresenta amici e hobby in un social network:

Gli archi sono rappresentati da frecce denominate e i vertici rappresentano persone e hobby specifici a cui si connettono.
Un semplice attraversamento di questo grafo ti consente di conoscere quali sono le cose che gli amici di Justin amano.
Perché usare un database a grafo?
Un database a grafo è la scelta migliore nei casi in cui le connessioni o relazioni tra entità sono al centro dei dati che si vogliono modellare.
Innanzitutto, modellare le interconnessioni di dati sotto forma di grafo e quindi scrivere query complesse che estraggono informazioni reali dal grafo è facile.
Lo sviluppo di un'applicazione equivalente utilizzando un database relazionale richiede la creazione di molte tabelle con più chiavi esterne e quindi la scrittura di query SQL annidate e join complessi. Questo approccio non solo diventa rapidamente macchinoso dal punto di vista della scrittura del codice, ma le sue prestazioni peggiorano velocemente con l'aumentare della quantità di dati.
Al contrario, un database a grafo come Neptune può eseguire query sulle relazioni tra miliardi di vertici senza rimanere bloccato.
Cosa è possibile fare con un database a grafo?
I grafi possono rappresentare le interrelazioni tra le entità del mondo reale in molti modi, in termini di azioni, proprietà, parentela, scelte di acquisto, legami personali, legami familiari e così via.
Ecco alcune delle aree più comuni in cui vengono utilizzati i database a grafo:
-
Grafi della conoscenza: i grafi della conoscenza consentono di organizzare tutti i tipi di informazioni connesse ed eseguire query su di esse per rispondere a domande generali. Utilizzando un grafo della conoscenza, puoi aggiungere informazioni tematiche a cataloghi di prodotti e modellare informazioni eterogenee come quelle contenute in Wikidata
. Per saperne di più su come funzionano i grafi della conoscenza e su dove vengono utilizzati, consulta Grafi della conoscenza in AWS
. -
Grafi di identità: in un database a grafo, puoi archiviare le relazioni tra categorie di informazioni, come interessi dei clienti, amici e cronologia degli acquisti, e quindi eseguire query su tali dati per formulare raccomandazioni personalizzate e pertinenti.
Ad esempio, puoi utilizzare un database a grafo per raccomandare a un utente prodotti da acquistare in base ai prodotti acquistati da altri che seguono lo stesso sport e hanno una cronologia di acquisto simile. Oppure puoi identificare le persone che hanno un amico in comune ma non si conoscono ancora e suggerire amicizie.
I grafi di questo tipo sono noti come grafi di identità e sono ampiamente utilizzati per personalizzare le interazioni con gli utenti. Per saperne di più, consulta Grafi di identità in AWS
. Per creare il tuo grafo di identità, puoi iniziare con l'esempio Identity Graph Using Amazon Neptune . -
Grafi di rilevamento delle frodi: si tratta di un utilizzo comune per i database a grafo. Possono aiutarti a monitorare gli acquisti con carta di credito e le località di acquisto per individuare utilizzi insoliti o per rilevare che un acquirente sta tentando di utilizzare lo stesso indirizzo e-mail e la stessa carta di credito usati in un caso di frode noto. Ti permettono inoltre di verificare se esistono sono più persone associate a un indirizzo e-mail personale o più persone in luoghi fisici diversi che condividono lo stesso indirizzo IP.
Considera il grafo seguente. Il grafo seguente mostra le relazioni tra tre persone e le informazioni relative alla loro identità. Ogni persona dispone di un indirizzo, un conto corrente e un social security number. Tuttavia, si può notare che Matt e Justin condividono lo stesso codice SSN, fatto irregolare che indica una possibile frode da parte di uno di essi. Una query su un grafo di rilevamento delle frodi può rivelare connessioni di questo tipo affinché possano essere esaminate.
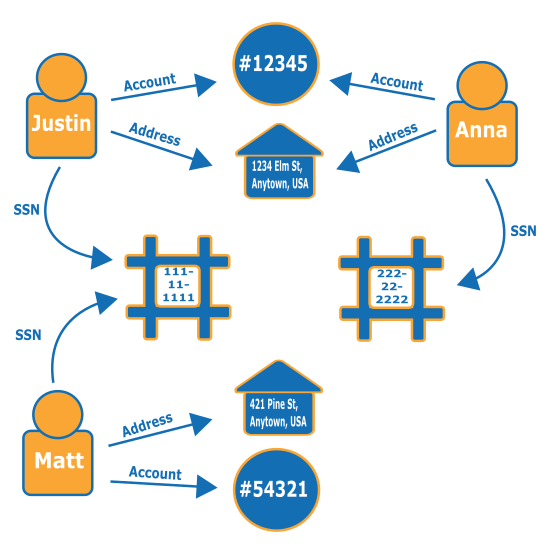
Per saperne di più su come funzionano i grafi di rilevamento di attività fraudolente e su dove vengono utilizzati, consulta Fraud Graphs on AWS
. -
Social network: le applicazioni di social network costituiscono una delle aree principali e più comuni in cui vengono utilizzati i database a grafo.
Supponiamo, ad esempio, che tu voglia creare un social feed in un sito Web. Puoi utilizzare facilmente un database a grafo sul back-end per fornire agli utenti risultati che riflettano gli ultimi aggiornamenti relativi a familiari, amici, persone con aggiornamenti a cui si è risposto con "Mi piace" e persone che vivono nelle vicinanze.
Indicazioni stradali: un grafo può aiutare a individuare il percorso migliore da un punto di partenza a una destinazione, in base al traffico attuale e ai modelli di traffico tipici.
Logistica: i grafi consentono di identificare il modo più efficiente di utilizzare le risorse di spedizione e distribuzione disponibili per soddisfare le esigenze dei clienti.
Diagnostica: i grafi possono rappresentare alberi diagnostici complessi su cui si possono eseguire query per identificare l'origine dei problemi e degli errori osservati.
Ricerca scientifica: con un database a grafo, è possibile creare applicazioni per archiviare ed esplorare i dati scientifici e persino le informazioni mediche sensibili utilizzando la crittografia dei dati inattivi. È ad esempio possibile archiviare i modelli di interazioni tra geni e patologie. È possibile cercare modelli di grafo all’interno di percorsi di proteine per trovare altri geni che potrebbero essere associati a una patologia. Puoi modellare composti chimici come grafi ed eseguire query per individuare modelli nelle strutture molecolari. È possibile correlare i dati dei pazienti contenuti nelle cartelle cliniche in sistemi diversi. Puoi organizzare in modo topico le pubblicazioni delle ricerche per trovare informazioni rilevanti in modo rapido.
Regole normative: è possibile archiviare requisiti normativi complessi sotto forma di grafici e interrogarli per rilevare situazioni in cui potrebbero applicarsi alle operazioni day-to-day aziendali.
-
Topologia ed eventi di rete: un database a grafo può aiutarti a gestire e proteggere una rete IT. Quando si archivia la topologia di rete come grafo, è anche possibile archiviare ed elaborare molti tipi diversi di eventi sulla rete. È possibile rispondere a varie domande, ad esempio quanti host eseguono un'applicazione specifica. È possibile eseguire query sui modelli che potrebbero dimostrare che un determinato host è stato compromesso da un programma dannoso e cercare i dati delle connessioni per risalire all'host originale che ha scaricato il programma.
Come si eseguono le query su un grafo?
Neptune supporta tre linguaggi di query speciali progettati per l'esecuzione di query sui dati dei grafi di tipi diversi. È possibile utilizzare questi linguaggi per aggiungere, modificare, eliminare ed eseguire query sui dati in un database a grafo Neptune:
-
Gremlin è un linguaggio di attraversamento del grafo per grafi di proprietà. Una query in Gremlin è un attraversamento composto da passaggi discreti, ognuno dei quali segue un arco fino a un nodo. Per ulteriori informazioni, consulta la documentazione di Gremlin su Apache TinkerPop 3
. L'implementazione di Gremlin in Neptune differisce da altre implementazioni, soprattutto se utilizzi Gremlin-Groovy (query Gremlin inviate come testo serializzato). Per ulteriori informazioni, consulta Conformità agli standard Gremlin in Amazon Neptune.
-
openCypher: openCypher è un linguaggio di query dichiarativo per grafi di proprietà che è stato sviluppato originariamente da Neo4j, per poi diventare open source nel 2015, e che ha contribuito al progetto openCypher
con una licenza open source Apache 2. Consulta i documenti Cypher Query Language Reference (versione 9) per le specifiche del linguaggio e Cypher Style Guide per ulteriori informazioni. -
SPARQL è un linguaggio di query dichiarativo per i dati RDF
basato sul tipo di corrispondenza del modello di grafo standardizzato dal World Wide Web Consortium (W3C) e descritto in SPARQL 1.1 Overview e nella specifica SPARQL 1.1 Query Language . Consulta Conformità agli standard SPARQL in Amazon Neptune per dettagli specifici sull'implementazione Neptune di SPARQL.
Esempi di corrispondenza delle query Gremlin e SPARQL
Considerati i seguenti grafi di persone (nodi) e le relative relazioni (archi), puoi scoprire che "gli amici di amici" di una persona specifica sono, ad esempio, amici di amici di Howard.
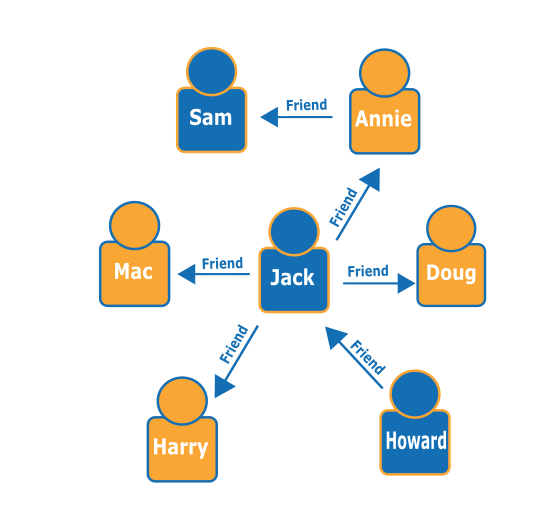
Guardando il grafico, è possibile verificare che Howard ha un amico, Jack e Jack ha quattro amici: Annie, Harry, Doug e Mac. Questo è un esempio semplice con un grafo semplice, ma questi tipi di query possono scalare in termini di complessità, set di dati e dimensione dei risultati.
Di seguito è riportata una query di attraversamento Gremlin che restituisce i nomi degli amici degli amici di Howard.
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
Di seguito è riportata una query SPARQL che restituisce i nomi degli amici degli amici di Howard.
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
Nota
Ogni parte di qualsiasi tripla in Resource Description Framework (RDF) dispone di un URI associato. In questo esempio, il prefisso dell'URI è intenzionalmente breve.
Segui un corso online sull'utilizzo di Amazon Neptune
Se ti piace imparare con i video, AWS offre corsi online negli AWS Online Tech Talks
Graph Database introduction, deep-dive and demo with Amazon Neptune
Approfondimenti sull'architettura di riferimento dei grafi
Se pensate ai problemi che un database a grafi potrebbe risolvere per voi e a come affrontarli, uno dei migliori punti di partenza è il progetto Neptune graph
Qui puoi trovare descrizioni dettagliate dei tipi di carichi di lavoro dei grafi e tre sezioni per aiutarti a progettare un database a grafo efficace:
Modelli di dati e linguaggi di query
: questa sezione illustra le differenze tra Gremlin e SPARQL e come scegliere il linguaggio più adatto. Modellazione dei dati dei grafi
: si tratta di una discussione approfondita su come prendere decisioni sulla modellazione dei dati dei grafi, incluse procedure dettagliate sulla modellazione dei grafi di proprietà con Gremlin e sulla modellazione RDF con SPARQL. Conversione di altri modelli di dati in un modello a grafo
: fornisce informazioni su come convertire un modello di dati relazionale in un modello a grafo.
Sono inoltre disponibili tre sezioni che illustrano i passaggi specifici per l'utilizzo di Neptune:
Connessione ad Amazon Neptune da client esterni al VPC di Neptune
: questa sezione mostra numerose opzioni per la connessione a Neptune dall'esterno del VPC in cui si trova il cluster database. Accesso ad Amazon Neptune AWS da Lambda
Functions: qui scoprirai come connetterti in modo affidabile a Neptune dalle funzioni Lambda. Scrittura su Amazon Neptune da un flusso di dati Amazon Kinesis
: questa sezione fornisce informazioni su come gestire scenari con velocità effettiva di scrittura elevata con Neptune.
