Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Analisi di traccia per Amazon OpenSearch Service
È possibile utilizzare Trace Analytics, che fa parte del plug-in OpenSearch Observability, per analizzare i dati di traccia provenienti da applicazioni distribuite. Trace Analytics richiede Elasticsearch 7.9 OpenSearch o versioni successive.
In un'applicazione distribuita, una singola operazione, ad esempio un utente che fa clic su un pulsante, può attivare una serie estesa di eventi. Ad esempio, il front-end dell'applicazione potrebbe chiamare un servizio di back-end, che a sua volta chiama un altro servizio, che esegue una query su un database, che elabora la query e restituisce un risultato. Quindi il primo servizio di back-end invia una conferma al front-end, che aggiorna l'interfaccia utente.
È possibile utilizzare Analisi di traccia per visualizzare questo flusso di eventi e identificare i problemi legati alle prestazioni.
Nota
Questa documentazione fornisce una breve panoramica di Trace Analytics. Per una documentazione completa, consulta Trace Analytics

Prerequisiti
Trace Analytics richiede l'aggiunta di strumentazione
Dopo aver aggiunto la strumentazione all'applicazione, OpenTelemetryCollector
Infine, è possibile utilizzare Panoramica di Amazon OpenSearch Ingestion per formattare i OpenTelemetry dati per utilizzarli con OpenSearch.
OpenTelemetry Configurazione di esempio di Collector
Per utilizzare il OpenTelemetry CollectorPanoramica di Amazon OpenSearch Ingestion, provare la seguente configurazione di esempio:
extensions: sigv4auth: region: "us-east-1" service: "osis" receivers: jaeger: protocols: grpc: exporters: otlphttp: traces_endpoint: "https://pipeline-endpoint.us-east-1.osis.amazonaws.com/opentelemetry.proto.collector.trace.v1.TraceService/Export" auth: authenticator: sigv4auth compression: none service: extensions: [sigv4auth] pipelines: traces: receivers: [jaeger] exporters: [otlphttp]
OpenSearch Configurazione di esempio di ingestione
Per inviare i dati di traccia a un dominio OpenSearch di Service, provare la seguente configurazione di esempio OpenSearch di Ingestion. Per istruzioni su come creare una pipeline, vedere. Creazione di pipeline Amazon OpenSearch Ingestion
version: "2" otel-trace-pipeline: source: otel_trace_source: "/${pipelineName}/ingest" processor: - trace_peer_forwarder: sink: - pipeline: name: "trace_pipeline" - pipeline: name: "service_map_pipeline" trace-pipeline: source: pipeline: name: "otel-trace-pipeline" processor: - otel_traces: sink: - opensearch: hosts: ["https://domain-endpoint"] index_type: trace-analytics-raw aws: # IAM role that OpenSearch Ingestion assumes to access the domain sink sts_role_arn: "arn:aws:iam::{account-id}:role/pipeline-role" region: "us-east-1" service-map-pipeline: source: pipeline: name: "otel-trace-pipeline" processor: - service_map: sink: - opensearch: hosts: ["https://domain-endpoint"] index_type: trace-analytics-service-map aws: # IAM role that the pipeline assumes to access the domain sink sts_role_arn: "arn:aws:iam::{account-id}:role/pipeline-role" region: "us-east-1"
Il ruolo della pipeline specificato nell'sts_role_arnopzione deve disporre di autorizzazioni di scrittura al sink. Per istruzioni su come configurare le autorizzazioni per il ruolo pipeline, consulta. Configurazione di ruoli e utenti in Amazon OpenSearch Ingestion
Esplorazione dei dati di traccia
La vista Pannello di controllo raggruppa le tracce in base al metodo HTTP e al percorso in modo da poter visualizzare la latenza media, il tasso di errore e le tendenze associati a una particolare operazione. Per una vista più mirata, provare a filtrare in base al nome del gruppo di traccia.

Per eseguire il drill-down delle tracce che costituiscono un gruppo di traccia, scegliere il numero di tracce nella colonna di destra. Quindi scegliere una singola traccia per un riepilogo dettagliato.
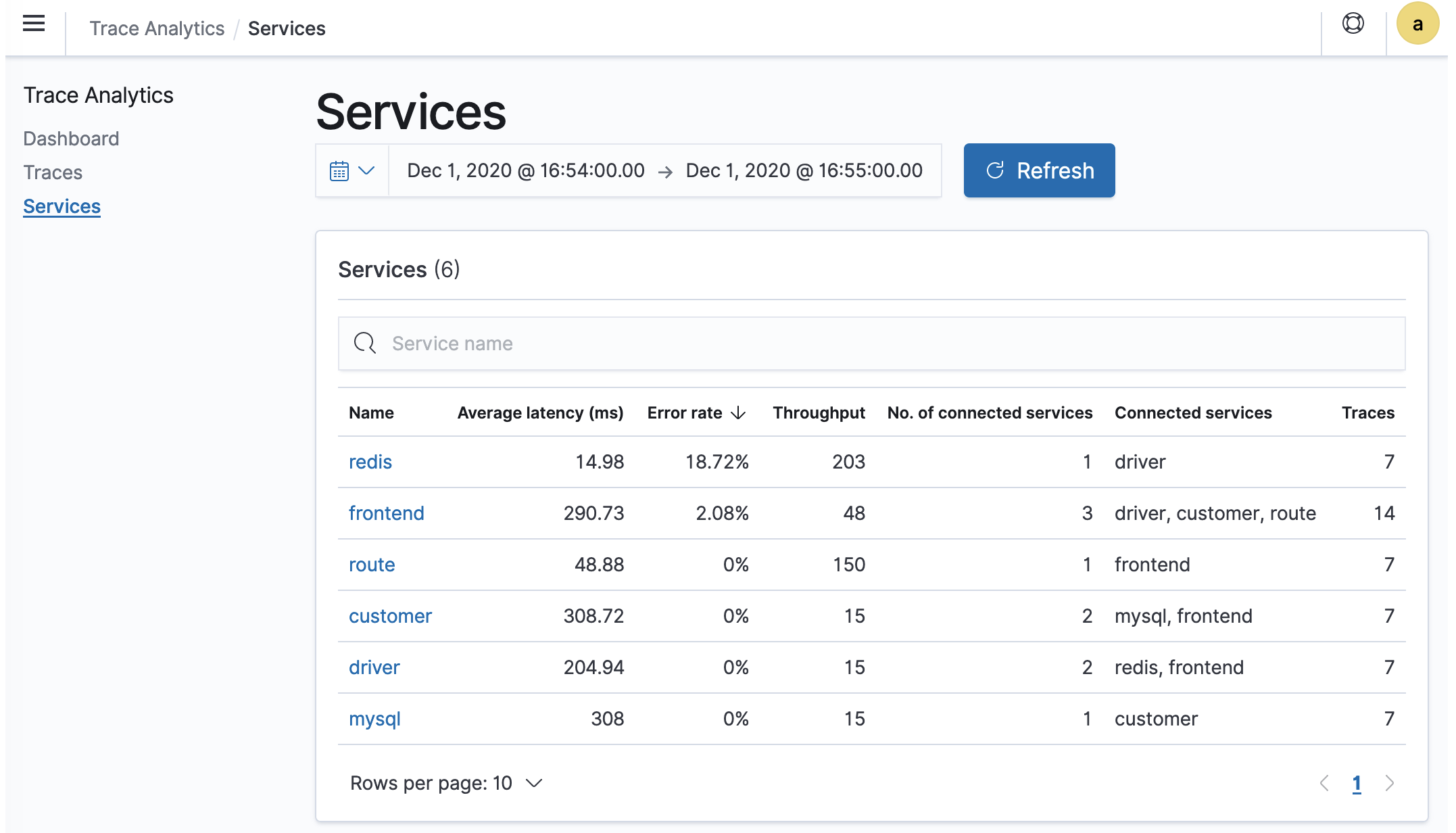
La vista Servizi riporta tutti i servizi dell'applicazione, oltre a una mappa interattiva che mostra come i vari servizi si connettono tra loro. A differenza del pannello di controllo (che consente di identificare i problemi in base all'operazione), la mappa del servizio consente di identificare i problemi in base al servizio. Provare a ordinare in base al tasso di errore o alla latenza per avere un'idea delle potenziali aree problematiche dell'applicazione.