Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tag SSML supportati
Amazon Polly supporta i seguenti tag SSML:
| Azione | Tag SSML | Disponibilità con voci neurali | Disponibilità con voci di lunga durata | Disponibilità con voci generative |
|---|---|---|---|---|
|
<break> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
| <emphasis> |
Non disponibile |
Non disponibile |
Non disponibile |
|
| <lang> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
| <mark> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
<p> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
<phoneme> |
Disponibilità completa |
Disponibilità completa |
Non disponibile |
|
|
Controllo del volume, della velocità di conversazione e dell'intonazione |
<prosody> |
Disponibilità parziale |
Disponibilità parziale |
Non disponibile |
|
Impostazione della durata massima per il parlato sintetizzato |
<prosody amazon:max-duration> |
Non disponibile |
Non disponibile |
Non disponibile |
|
<s> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
Controllo del modo in cui vengono pronunciati tipi speciali di parole |
<say-as> |
Disponibilità parziale |
Disponibilità parziale |
Disponibilità parziale |
|
<speak> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
<sub> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
<w> |
Disponibilità completa |
Disponibilità completa |
Disponibilità completa |
|
|
<amazon:auto-breaths> |
Non disponibile |
Non disponibile |
Non disponibile |
|
| <amazon:domain name="news"> |
Seleziona solo voci neurali |
Non disponibile |
Non disponibile |
|
|
<amazon:effect name="drc"> |
Disponibilità completa |
Disponibilità completa |
Non disponibile |
|
|
<amazon:effect phonation="soft"> |
Non disponibile |
Non disponibile |
Non disponibile |
|
|
<amazon:effect > vocal-tract-length |
Non disponibile |
Non disponibile |
Non disponibile |
|
|
<amazon:effect name="whispered"> |
Non disponibile |
Non disponibile |
Non disponibile |
Nota
Se utilizzi tag SSML non supportati in formato standard, neurale o lungo, riceverai un errore.
Identificazione del testo migliorato con SSML
<speak>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Il tag <speak> è l'elemento principale di tutto il testo SSML di Amazon Polly. Tutto il testo ottimizzato per SSML deve essere racchiuso in una coppia di tag <speak>.
<speak>Mary had a little lamb.</speak>Aggiungere una pausa
<break>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Per aggiungere una pausa al testo, utilizza il tag <break>. È possibile impostare una pausa in base all'intensità (equivalente alla pausa dopo una virgola, una frase o un paragrafo), oppure in base a un determinato intervallo di tempo in secondi o millisecondi. Se non si specifica un attributo per stabilire la durata della pausa, Amazon Polly utilizza l'impostazione predefinita <break
strength="medium"/>, che aggiunge una pausa della lunghezza di una pausa dopo la virgola.
strength valori attributo:
-
none: nessuna pausa. Utilizzanoneper rimuovere una pausa che si verifica normalmente, ad esempio dopo un punto. -
x-weak: ha la stessa forza dinone, senza pausa. -
weak: imposta una pausa della stessa durata della pausa dopo la virgola. -
medium: ha la stessa forza diweak. -
strong: imposta una pausa della stessa durata della pausa dopo una frase. -
x-strong: imposta una pausa della stessa durata della pausa dopo un paragrafo.
time valori attributo:
-
[number]s10s. -
[number]ms10000ms.
Ad esempio:
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>Se con il tag break non viene utilizzato nessun attributo, il risultato varia a seconda del testo:
-
Se non c'è altra punteggiatura accanto al tag
break, verrà creata una<break strength="medium"/>(comma-length pause). -
Se il tag è accanto a una virgola, il tag verrà aggiornato a una
<break strength="strong"/>(sentence-length pause). -
Se il tag è accanto a un punto, il tag verrà aggiornato a una
<break strength="x-strong"/>(paragraph-length pause).
Enfatizzare le parole
<emphasis>
Questo tag è supportato solo dal formato TTS standard.
Per enfatizzare le parole, utilizza il tag <emphasis>. L'enfatizzazione delle parole modifica la velocità e il volume della sintesi vocale. Una maggiore enfasi significa che Amazon Polly pronuncia il testo a voce più alta e più lentamente. Con una minore enfasi, viene pronunciato più velocemente e con tono più pacato. Per specificare il grado di enfasi, utilizzare l'attributo level.
level valori attributo:
-
Strong: aumenta il volume e rallenta la velocità di pronuncia in modo che la sintesi vocale sia più lenta e con un tono più alto. -
Moderate: aumenta il volume e rallenta la velocità di pronuncia, ma meno rispetto astrong.Moderateè il valore predefinito. -
Reduced: diminuisce il volume e accelera la velocità di pronuncia. La sintesi vocale viene pronunciata più velocemente e con tono più morbido.
Nota
Il volume e la velocità di pronuncia normali per una voce rientrano tra i livelli moderate e reduced.
Ad esempio:
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
Specificare un'altra lingua per parole specifiche
<lang>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Specifica un'altra lingua per una determinata parola o frase con il tag <lang>. Le parole e frasi di lingue straniere generalmente sono pronunciate in modo più chiaro quando vengono incluse all'interno di una coppia di tag <lang>. Per specificare la lingua, utilizzare l'attributo xml:lang. Per un elenco completo delle lingue disponibili, consultare Lingue in Amazon Polly.
Se non si applica il tag <lang>, tutte le parole del testo di input vengono pronunciate nella lingua della voce specificata in voice-id. Se si applica il tag <lang>, le parole sono pronunciate in tale lingua.
Ad esempio, se il voice-id è Joanna (che parla inglese, Stati Uniti), Amazon Polly pronuncia quanto segue con la voce di Joanna senza un accento francese:
<speak>
Je ne parle pas français.
</speak>Se si utilizza la voce Joanna con il tag <lang>, Amazon Polly pronuncia la frase nella voce di Joanna con un francese con un accento americano:
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Poiché Joanna non è madrelingua francese, la pronuncia si basa sulla sua lingua nativa, ovvero l'inglese degli Stati Uniti. Ad esempio, sebbene una perfetta pronuncia francese presenti una /R/vibrata alveolare nella parola français, la voce di Joanna in inglese americano pronuncia questo fonema con il suono corrispondente /r/.
Se utilizzi il voice-id di Giorgio, che parla italiano, con il seguente testo, Amazon Polly pronuncia la frase con la voce di Giorgio e la pronuncia in italiano:
<speak>
Mi piace Bruce Springsteen.
</speak>Se si utilizza la stessa voce con il seguente tag <lang>, Amazon Polly pronuncia Bruce Springsteen in inglese con l'accento italiano:
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>Questo tag può essere utilizzato anche come sostituto dell'opzione opzionale DefaultLangCodeper la sintesi vocale. Tuttavia, questa operazione richiede la formattazione del testo con SSML.
Inserimento di un tag personalizzato nel testo
<mark>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Per inserire un tag personalizzato nel testo, utilizza il tag <mark>. Amazon Polly non esegue alcuna operazione sul tag, ma restituisce la posizione del tag nei metadati di SSML. Questo tag può essere qualsiasi operazione per la quale si desidera effettuare la chiamata, purché mantenga il formato seguente:
<mark name="tag_name"/>Ad esempio, se il nome del tag è "animal" e il testo di input è:
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>È possibile che Amazon Polly restituisca i seguenti metadati da SSML:
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}Aggiungere una pausa tra i paragrafi
<p>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Per aggiungere una pausa tra paragrafi nel tuo testo, utilizza il tag <p>. L'utilizzo di questo tag fornisce una pausa più lunga rispetto alle pause dei madrelingua dopo le virgole o la fine di una frase. Utilizza il tag <p> per racchiudere il paragrafo:
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>Ciò equivale a specificare una pausa utilizzando <break strength="x-strong"/>.
Uso della pronuncia fonetica
<phoneme>
Questo tag è supportato dai formati TTS in formato esteso, neurali e standard.
Per fare in mode che Amazon Polly utilizzi la pronuncia fonetica per testo specifico, utilizzare il tag <phoneme>.
Con il tag <phoneme> sono necessari due attributi. Indicano l'alfabeto fonetico utilizzato da Amazon Polly e i simboli fonetici della pronuncia corretta:
-
alphabet-
ipa: indica che verrà utilizzato l'alfabeto fonetico internazionale (IPA). -
x-sampa: indica che verrà utilizzato l'alfabeto X-SAMPA (Extended Speech Assessment Methods Fonetico Alphabet).
-
-
ph-
Specifica i simboli fonetici per la pronuncia. Per ulteriori informazioni, consulta Tabelle fonemi e visemi per le lingue supportate
-
Con il tag <phoneme>, Amazon Polly utilizza la pronuncia specificata dall'attributo ph invece della pronuncia standard associata come impostazione predefinita al linguaggio utilizzato dalla voce selezionata.
Ad esempio, la parola "pecan" può essere pronunciata in due modi. Nell'esempio che segue, alla parola "pecan" viene assegnata una pronuncia personalizzata diversa in ciascuna riga. Amazon Polly pronuncia pecan come specificato negli attributi ph, anziché utilizzare la pronuncia predefinita:
Alfabeto fonetico internazionale (IPA)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
Extended Speech Assessment Methods Phonetic Alphabet (X-SAMPA)
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
Il cinese mandarino utilizza Pinyin per la pronuncia fonetica.
Pinyin
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
Il giapponese usa Yomigana e Pronuncia Kana.
Yomigana
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
Pronuncia Kana
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
Controllo del volume, della velocità di conversazione e dell'intonazione
<prosody>
Gli attributi dei tag Prosody sono completamente supportati dalle voci TTS standard. Le voci neurali e lunghe supportano gli rate attributi volume and, ma non supportano l'attributo. pitch
Per controllare il volume, la velocità o l'intonazione della voce selezionata, utilizza il tag prosody.
Il volume, la velocità della sintesi vocale e l'intonazione dipendono dalla voce specifica selezionata. Oltre alle differenze tra voci per diversi linguaggi, ci sono differenze tra le singole voci che parlano la stessa lingua. Per questo motivo, mentre gli attributi sono simili in tutti i linguaggi, ci sono chiare varianti da lingua a lingua e nessun valore assoluto è disponibile.
Il tag prosody ha tre attributi, ognuno dei quali dispone di diversi valori disponibili per impostare l'attributo. Ogni attributo utilizza la stessa sintassi:
<prosody attribute="value"></prosody>-
volume-
default: reimposta il volume sul livello di default per la voce corrente. -
silent,x-soft,soft,medium,loud,x-loud: consente di specificare il volume su un valore di default per la voce corrente. -
+ndB,-ndB: modifica il volume in relazione al livello corrente. Il valore+0dBindica che il volume rimane invariato, mentre+6dBindica circa il doppio dell'attuale volume e-6dBindica circa la metà dell'attuale volume.
Ad esempio, è possibile impostare il volume per un passaggio come segue:
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>In alternativa, puoi impostarlo in questo modo:
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fast,x-fast. Impostare l'intonazione su un valore predefinito per la voce selezionata. -
n%: Una modifica della percentuale non negativa nella velocità di pronuncia. Ad esempio, un valore di 100% significa nessun cambiamento alla velocità di pronuncia, un valore pari a 200% significa una velocità di pronuncia il doppio della velocità predefinita e un valore del 50% significa una velocità di pronuncia la metà della velocità predefinita. Questo valore ha un intervallo di 20-200%.
Ad esempio, è possibile impostare la velocità della sintesi vocale per un passaggio come segue:
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>In alternativa, puoi impostarlo in questo modo:
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: reimposta l'intonazione sul livello di default per la voce corrente. -
x-low,low,medium,high,x-high: imposta l'intonazione su un valore predefinito per la voce corrente. -
+n%o-n%: regola l'intonazione in base a una percentuale relativa. Ad esempio, un valore di+0%significa che non c'è alcun cambiamento nell'intonazione di base,+5%offre un'intonazione di base leggermente più elevata, mentre-5%avrà come risultato un'intonazione di base leggermente inferiore.
Ad esempio, è possibile impostare l'intonazione per un passaggio come segue:
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>In alternativa, puoi impostarlo in questo modo:
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
Il tag <prosody > deve contenere almeno un attributo, ma può includerne di più all'interno dello stesso tag.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
Può anche essere combinato con tag nidificati, come segue:
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
Impostazione della durata massima per il parlato sintetizzato
<prosody amazon:max-duration>
Questo tag è attualmente supportato solo dal formato TTS standard.
Per controllare la durata di un discorso quando viene sintetizzato, utilizza il tag <prosody> con l'attributo amazon:max-duration.
La durata della sintesi vocale varia leggermente a seconda della voce selezionata. Potrebbe quindi essere difficile associare la sintesi vocale a grafica o altre attività che richiedono tempi precisi. Questo problema peggiora con le applicazioni di traduzione, perché il tempo necessario per pronunciare frasi specifiche può variare ampiamente con lingue diverse.
Il tag <prosody amazon:max-duration> associa la sintesi vocale alla quantità di tempo che desidera richiedere (la durata).
Questo tag utilizza la sintassi seguente:
<prosody amazon:max-duration="time duration">Con il tag <prosody amazon:max-duration>, puoi specificare la durata in secondi o millisecondi:
-
ns -
nms
Ad esempio, il seguente testo parlato ha una durata massima di 2 secondi:
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>Il testo posizionato all'interno del tag non supera la durata specificata. Se la voce o la lingua scelta richiederebbe normalmente più tempo di tale durata, Amazon Polly accelera la sintesi vocale in modo che rientri nella durata specificata.
Se la durata specificata è superiore a quella richiesta per leggere il testo a una velocità normale, Amazon Polly legge la sintesi vocale normalmente. Non rallenta la sintesi vocale, né aggiunge silenzio, perciò l'audio risultante è più breve di quanto richiesto.
Nota
Amazon Polly aumenta la velocità non più di 5 volte rispetto alla velocità normale. Se il testo viene letto più velocemente, non è in genere comprensibile. Se una sintesi vocale non rientra nella durata specificata anche quando accelerata al massimo, l'audio sarà accelerato ma durerà più della durata specificata.
Puoi includere una sola frase o più frasi all'interno di un tag <prosody amazon:max-duration> e puoi utilizzare più tag <prosody amazon:max-duration> all'interno del testo.
Ad esempio:
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
L'utilizzo del tag <prosody amazon:max-duration> è in grado di aumentare la latenza quando Amazon Polly restituisce una sintesi vocale. Il grado di latenza dipende dal passaggio e dalla relativa lunghezza. È consigliabile utilizzare testo costituito da passaggi di testo relativamente brevi.
Limitazioni
Non vi sono limitazioni nella modalità di utilizzo del tag <prosody
amazon:max-duration> né su come funziona con altri tag SSML:
-
Il testo all'interno di un tag
<prosody amazon:max-duration>non può superare il limite di 1.500 caratteri. -
Non è possibile nidificare i tag
<prosody amazon:max-duration>. Se hai inserito un tag<prosody amazon:max-duration>all'interno di un altro, Amazon Polly ignora il tag interno.Ad esempio, nell'istruzione seguente, il tag
<prosody amazon:max-duration="5s">viene ignorato:<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
Non è possibile utilizzare i tag
<prosody>con l'attributorateall'interno di un tag<prosody amazon:max-duration>. Questo perché entrambi hanno impatto sulla velocità a cui il testo viene pronunciato.Nell'esempio seguente, Amazon Polly ignora il tag
<prosody rate="2">:<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
Pause e max-duration
Quando utilizzi il tag max-duration, puoi comunque inserire pause all'interno del testo. Tuttavia, Amazon Polly include la lunghezza della pausa quando si calcola la durata massima per sintesi vocale. Inoltre, Amazon Polly conserva le brevi pause che si verificano laddove virgole e punti vengono posizionati all'interno di un passaggio e le include nella durata massima.
Ad esempio, nel blocco seguente, l'interruzione di 600 millisecondi e le interruzioni causate dalle virgole e i punti si verificano all'interno della sintesi vocale da 8 secondi:
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
Aggiungere una pausa tra le frasi
<s>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Per aggiungere una pausa tra righe o frasi nel tuo testo, utilizzare il tag <s>. L'utilizzo del tag ha lo stesso effetto di:
-
Terminare una frase con un punto (.)
-
Specificare una pausa con
<break strength="strong"/>
A differenza del tag <break>, il tag <s > racchiude la frase. Questa funzione è utile per la sintesi vocale che è organizzata in righe, invece di frasi, ad esempio le poesie.
Nell'esempio seguente, il tag <s> crea una breve pausa dopo la prima e la seconda frase. La frase finale non presenta tag <s>, ma è anche seguita da una breve pausa perché finisce con un punto.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
Controllo del modo in cui vengono pronunciati tipi speciali di parole
<say-as>
Ad eccezione dell'charactersopzione, il <say-as> tag è supportato dai formati TTS generativi, lunghi, neurali e standard. Tieni presente che se Amazon Polly utilizza una voce neurale e incontra il <say-as> tag con l'charactersopzione in fase di esecuzione, la frase interessata verrà sintetizzata utilizzando la relativa voce standard. Tuttavia, la frase interessata verrà comunque fatturata come se utilizzasse una voce neurale.
Utilizza il tag <say-as> con l'attributo interpret-as per indicare a Amazon Polly come pronunciare determinati caratteri, parole e numeri. In tal modo è possibile fornire ulteriore contesto per eliminare qualsiasi ambiguità in merito a come deve essere effettuato il rendering del testo da parte di Amazon Polly.
Il <say-as> tag utilizza un attributointerpret-as, che utilizza una serie di possibili valori disponibili. Ogni attributo utilizza la stessa sintassi:
<say-as interpret-as="value">[text to be interpreted]</say-as>I valori seguenti sono disponibili con interpret-as:
-
charactersoppurespell-out: compila ogni lettera del testo, ad a-b-c esempio.Nota
Questa opzione non è attualmente supportata per le voci neurali. Se utilizzi una voce neurale e questo codice SSML viene rilevato da Amazon Polly in fase di esecuzione, la frase interessata verrà sintetizzata utilizzando la relativa voce standard. Tieni presente, tuttavia, che questa frase verrà comunque fatturata come se utilizzasse una voce neurale.
-
cardinalonumber: interpreta il testo numerico come un numero cardinale, come in 1.234. -
ordinal: interpreta il testo numerico come numero ordinale, come 1.234°. -
digits: pronuncia ogni cifra individualmente, come in 1-2-3-4. -
fraction: interpreta il testo numerico come frazione. Questo è valido sia per frazioni comuni, ad esempio 3/20, sia per frazioni miste, ad esempio 2 ½. Guardare qui di seguito per ulteriori informazioni. -
unit: interpreta un testo numerico come una misura. Il valore deve essere un numero o una frazione seguita da un'unità senza spazi tra i due elementi come in1/2inchoppure da un'unità come in1meter. -
date: interpreta il testo come data. Il formato della data deve essere specificato con l'attributo formato. Guardare qui di seguito per ulteriori informazioni. -
time: interpreta il testo numerico come durata espressa in minuti e secondi, come in1'21". -
address: interpreta il testo come parte di un indirizzo. -
expletive: sostituisce con un segnale acustico il contenuto incluso nel tag. -
telephone: interpreta il testo numerico come un numero di telefono di 7 cifre o 10 cifre, ad esempio2025551212. È anche possibile utilizzare questo valore per gestire le estensioni telefoniche, ad esempio2025551212x345. Guardare qui di seguito per ulteriori informazioni.Nota
Attualmente l'opzione
telephonenon è disponibile per tutte le lingue. Tuttavia, è disponibile per le varianti di lingua inglese (en-AU, en-GB, en-IN, en-US ed en-GB-WLS), varianti di lingua spagnola (es-ES, es-MX ed es-US), varianti di lingua francese (fr-FR e fr-CA) e varianti portoghesi (pt-BR e pt-PT), così come tedesco (de-DE), italiano (it-IT), giapponese (ja-JP) e russo (ru-RU). Va inoltre notato che in alcuni casi, lingue come l'arabo (arb) gestiscono automaticamente il numero impostato come numero di telefono e quindi non implementano effettivamente iltelephonetag SSML.
Frazioni
Amazon Polly interpreta i valori nel tag say-as che presentano l'attributo interpret-as="fraction" come comuni frazioni. Di seguito è riportata la sintassi per le frazioni:
-
Frazione
Sintassi:
numero cardinale/numero cardinale, ad esempio 2/9.Ad esempio:
<say-as interpret-as="fraction">2/9</say-as>si pronuncia "due noni." -
Numero misto non negativo
Sintassi:
numero cardinale+numero cardinale/numero cardinale, ad esempio 3+1/2.Ad esempio:
<say-as interpret-as="fraction">3+1/2</say-as>si pronuncia "tre e mezzo".Nota
Deve esserci un
+tra "3" e "1/2". Amazon Polly non supporta un numero misto senza+, ad esempio "3 1/2".
Date:
Quando interpret-as è impostato su date, è necessario indicare il formato della data.
Questo utilizza la sintassi seguente:
<say-as interpret-as="date" format="format">[date]</say-as>
Ad esempio:
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
I formati seguenti possono essere utilizzati con l'attributo date.
-
mdy: M. onth-day-year -
dmy: ay-month-year D. -
ymd: ear-month-day Y. -
md: mese-giorno. -
dm: giorno-mese. -
ym: anno-mese. -
my: mese-anno. -
d: giorno. -
m: mese. -
y: anno. -
yyyymmdd: ear-month-day Y. Se utilizzi questo formato, puoi fare in modo che Amazon Polly salti parti della data utilizzando punti di domanda.Ad esempio, Amazon Polly riproduce quanto segue come "22 settembre":
<say-as interpret-as="date">????0922</say-as>Formatnon è necessario.
Telefono
Amazon Polly tenta di interpretare il testo fornito correttamente in base alla formattazione del testo anche senza il tag <say-as>. Ad esempio, se il testo include "202-555-1212", Amazon Polly lo interpreta come un numero di telefono a 10 cifre e pronuncia ogni singola cifra individualmente, con una breve pausa per ogni trattino. In questo caso, non utilizzare <say-as interpret-as="telephone">. Tuttavia, se si desidera che il testo "2025551212" venga pronunciato da Amazon Polly come un numero di telefono, utilizzare <say-as
interpret-as="telephone">.
La logica per l'interpretazione di ciascun elemento è specifica per la lingua. Ad esempio, i numeri di telefono sono pronunciati in modo diverso nell'inglese americano e nell'inglese britannico (nell'inglese britannico, vengono raggruppate sequenze della stessa cifra, ad esempio "doppio cinque" o "triplo quattro"). Per mostrare la differenza, è possibile testare il seguente esempio scegliendo la voce in inglese americano e in inglese britannico:
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
Pronuncia di acronimi e abbreviazioni
<sub>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Utilizza il tag <sub> con l'attributo alias per sostituire una parola diversa (o pronuncia) per il testo selezionato, ad esempio un acronimo o un'abbreviazione.
Questo utilizza la sintassi:
<sub alias="new word">abbreviation</sub>In questo esempio, il simbolo chimico dell'elemento viene sostituito con il nome "Mercury" per rendere più chiari i contenuti audio.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
Migliorare la pronuncia specificando parti del discorso
<w>
Questo tag è supportato dai formati TTS generativi, estesi, neurali e standard.
Puoi utilizzare il tag <w> per personalizzare la pronuncia delle parole specificando la parte del discorso della parola o un altro significato. Questa operazione viene eseguita utilizzando l'attributo role.
Questo tag utilizza la sintassi seguente:
<w role="attribute">text</w>È possibile utilizzare i seguenti valori per l'attributo role:
Per specificare la parte del discorso:
-
amazon:VB: interpreta la parola come un verbo (presente semplice). -
amazon:VBD: interpreta la parola come un verbo passato. -
amazon:DT: interpreta la parola come un determinante. -
amazon:IN: interpreta la parola come una preposizione. -
amazon:JJ: interpreta la parola come un aggettivo. -
amazon:NN: interpreta la parola come un sostantivo.
Ad esempio, a seconda della parte del discorso, la pronuncia inglese americana della parola "read" varia in base al tag:
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
Per specificare un significato specifico:
-
amazon:DEFAULT: utilizza il significato predefinito della parola. -
amazon:SENSE_1: utilizza il significato non di default della parola, laddove presente. Ad esempio, il sostantivo "bass" è pronunciato in modi differenti a seconda del suo significato. Il significato predefinito è la parte inferiore della scala musicale. L'altro significato è una specie di pesce d'acqua dolce, detto anche "bass" ma pronunciato in modo diverso. Utilizzando<w role="amazon:SENSE_1">bass</w>si rende la pronuncia non di default (pesce d'acqua dolce) per il testo dell'audio.
Questa differenza di pronuncia e di significato può essere percepita sintetizzando quanto segue:
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
Nota
Alcune lingue possono avere una selezione diversa delle parti del discorso supportate.
Aggiungere il suono del respiro
<amazon:breath> e <amazon:auto-breaths>
Questo tag è supportato solo dal formato TTS standard.
Il linguaggio naturale include sia parole correttamente pronunciate sia suoni respiratori. Aggiungendo suoni respiratori alla sintesi vocale, è possibile rendere il suono più naturale. I tag <amazon:breath> e <amazon:auto-breaths> forniscono le respirazioni. Sono disponibili le seguenti opzioni:
-
Modalità manuale: puoi impostare la posizione, la durata e il volume di una respirazione all'interno del testo
-
Modalità automatica: Amazon Polly inserisce automaticamente i suoni della respirazione nell'output del discorso
-
Modalità mista: sia tu sia Amazon Polly aggiungete i suoni della respirazione
Modalità manuale
Nella modalità manuale, inserisci il tag <amazon:breath/> nel testo di input in cui desideri posizionare un respiro. Puoi personalizzare la durata e il volume delle respirazioni con, rispettivamente, gli attributi duration e volume:
-
duration: controlla la durata del respiro. I valori validi sono:default,x-short,short,medium,long,x-long. Il valore predefinito èmedium. -
volume: controlla il volume del respiro. I valori validi sono:default,x-soft,soft,medium,loud,x-loud. Il valore predefinito èmedium.
Nota
La lunghezza esatta e il volume di ogni valore dell'attributo dipendono dalla voce di Amazon Polly specifica utilizzata.
Per impostare il suono di una respirazione utilizzando le impostazioni predefinite, usa <amazon:breath/> senza attributi.
Ad esempio, per utilizzare gli attributi per impostare la durata e il volume di un respiro su un valore medio, devi configurare gli attributi come segue:
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
Per usare le impostazioni predefinite, è sufficiente utilizzare il tag:
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
Puoi aggiungere singoli suoni respiratori all'interno di un passaggio, come segue:
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
Modalità automatica
Nella modalità automatica, utilizzi il tag <amazon:auto-breaths> per dire a Amazon Polly di creare automaticamente suoni respiratori a intervalli stabiliti. Puoi impostare la frequenza degli intervalli, il volume e la durata. Posiziona il tag </amazon:auto-breaths> all'inizio del testo a cui vuoi applicare la respirazione automatica e chiudi il tag al termine.
Nota
A differenza del tag <amazon:breath/> della modalità manuale, il tag <amazon:auto-breaths> richiede un tag di chiusura (</amazon:auto-breaths>).
È possibile utilizzare i seguenti attributi opzionali con il tag <amazon:auto-breaths>:
-
volume: controlla il volume del respiro. I valori validi sono:default,x-soft,soft,medium,loud,x-loud. Il valore predefinito èmedium. -
frequency: controlla la frequenza con cui il respiro è presente nel testo. I valori validi sono:default,x-low,low,medium,high,x-high. Il valore predefinito èmedium. -
duration: controlla la durata del respiro. I valori validi sono:default,x-short,short,medium,long,x-long. Il valore predefinito èmedium.
Per impostazione predefinita, la frequenza dei suoni di respirazione dipende dal testo di input. Tuttavia, i suoni della respirazione spesso si verificano dopo virgole e punti.
Gli esempi seguenti mostrano come utilizzare il tag <amazon:auto-breaths>. Per scegliere le opzioni da utilizzare per i tuoi contenuti, copia gli esempi applicabili sulla console di Amazon Polly e ascolta le differenze.
-
Utilizzo della modalità automatica senza parametri opzionali.
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Utilizzo della modalità automatica con il controllo del volume. I parametri non specificati (
durationefrequency) sono impostati sui valori predefiniti (medium).<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Utilizzo della modalità automatica con il controllo della frequenza. I parametri non specificati (
durationevolume) sono impostati sui valori predefiniti (medium).<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Utilizzo della modalità automatica con più parametri. Per il parametro
Durationnon specificato, Amazon Polly usa il valore predefinito (medium).<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
Stile di pronuncia newscaster
<amazon:domain name="news">
Lo stile newscaster è disponibile solo per le voci di Matthew o Joanna, disponibili solo in inglese Stati Uniti (en-US), Lupe, in inglese spagnolo (es-US) e Amy, in inglese Regno Unito (en-GB). È supportato solo quando si utilizza il formato Neural.
Per utilizzare lo stile newscaster, utilizza i tag SSML e la sintassi seguente:
<amazon:domain name="news">text</amazon:domain>
Ad esempio, puoi utilizzare lo stile newscaster con la voce di Amy come segue:
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
Aggiungere la compressione della gamma dinamica
<amazon:effect name="drc">
Questo tag è supportato dai formati TTS in formato esteso, neurali e standard.
A seconda del testo, della lingua e della voce utilizzati in un file audio, la gamma sonora varia da morbida a forte. I suoni ambientali, ad esempio il suono di un veicolo in movimento, possono spesso mascherare i suoni più tenui. Ciò impedisce di percepire chiaramente la traccia audio. Per aumentare il volume di alcuni suoni nel tuo file audio, utilizza il tag (drc) per la compressione dinamica intervalli.
Il tag drc imposta una soglia di "sonorità" media per l'audio e aumenta il volume (il guadagno) dei suoni attorno a tale soglia. Applica l'aumento massimo di guadagno nel punto più vicino alla soglia, mentre l'aumento di guadagno diminuisce quanto più lontano dalla soglia.
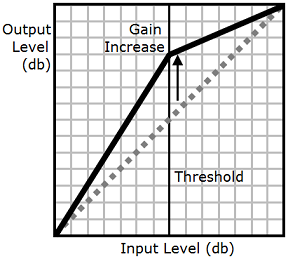
In questo modo, i suoni intermedi vengono uditi più facilmente in un ambiente rumoroso e ciò rende più chiaro l'intero file audio.
Il tag drc è un parametro Booleano (o è presente o non lo è). Utilizza la sintassi: <amazon:effect name="drc"> e viene chiuso con </amazon:effect>.
È possibile utilizzare il tag drc con qualsiasi voce o lingua supportate da Amazon Polly. È possibile applicarlo a un'intera sezione della registrazione o solo ad alcune parole. Ad esempio:
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
Nota
Quando utilizzi"drc" nella sintassi , ricorda che fa distinzione tra maiuscole e minuscole.amazon:effect
Utilizzo di drc con il tag prosody
volume
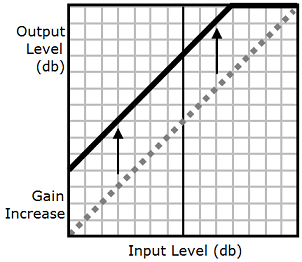
Come illustrato nel grafico che segue, il tag prosody
volume aumenta in modo uniforme il volume di un intero file audio dal livello originale (linea punteggiata) a un livello adeguato (linea continua). Per aumentare ulteriormente il volume di determinate parti del file, utilizza il tag drc con il tag prosody
volume. La combinazione dei tag non modifica le impostazioni del tag prosody volume.
Quando utilizzi i tag drc e prosody
volume insieme, Amazon Polly applica prima il tag drc, aumentando i suoni intermedi (quelli vicino alla soglia). Quindi, applica il tag prosody volume e aumenta ulteriormente il volume dell'intera traccia audio in modo uniforme.
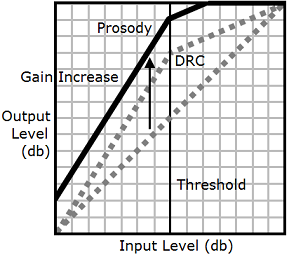
Per usare i tag in combinazione, occorre nidificarli uno all'interno dell'altro. Ad esempio:
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
In questo testo, il tag prosody volume aumenta il volume dell'intero passaggio a "loud" (alto). Il tag drc ottimizza il volume dei valori intermedi nella seconda frase.
Nota
Quando utilizzi i tag drc e prosody
volume insieme, segui le procedure XML standard per la nidificazione dei tag.
Parlando a bassa voce
<amazon:effect phonation="soft">
Questo tag è attualmente supportato solo dal formato TTS standard.
Per specificare che il testo di input deve essere pronunciato con una softer-than-normal voce, usa il <amazon:effect phonation="soft">tag.
Questo utilizza la sintassi:
<amazon:effect phonation="soft">text</amazon:effect>Ad esempio, è possibile utilizzare questo tag con la voce di Matthew come segue:
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
Controllo del timbro
<amazon:effect > vocal-tract-length
Questo tag è attualmente supportato solo dal formato TTS standard.
Il timbro è la qualità tonale di una voce che consente di stabilire la differenza tra voci, anche quando hanno la stessa intonazione e sonorità. Una delle più importanti caratteristiche fisiologiche che contribuisce al timbro della sintesi vocale è la lunghezza del tratto vocale. Il tratto vocale è una cavità di aria che si estende dalla parte superiore delle corde vocali fino al bordo delle labbra.
Per controllare il timbro dell'output vocale in Amazon Polly, utilizza il tag vocal-tract-length. Questo tag ha l'effetto di modificare la lunghezza del tratto vocale dell'oratore, che suona come una modifica delle dimensioni dello stesso. Aumentando vocal-tract-length, l'oratore dà l'impressione di essere fisicamente più grande. Diminuendolo, l'oratore dà l'impressione di essere più piccolo. Puoi utilizzare questo tag con qualsiasi voce presente nel portafoglio Text-to-Speech (Sintesi vocale) di Amazon Polly.
Per modificare il timbro, utilizza i seguenti valori:
-
+n%o-n%: regola la lunghezza del tratto vocale in base a una modifica percentuale relativa nella voce corrente. Ad esempio, +4% o -2%. I valori validi sono compresi tra +100% e -50%. I valori al di fuori di questo intervallo vengono tagliati. Ad esempio, +111% suona come+100% e -60% suona come -50%. -
n%: consente di modificare la lunghezza del tratto vocale impostando una percentuale assoluta per la lunghezza del tratto della voce corrente. Ad esempio, 110% o 75%. Un valore assoluto di 110% equivale a un valore relativo di+10%. Un valore assoluto di 100% è lo stesso valore di default per la voce corrente.
L'esempio seguente mostra come modificare la durata del tratto vocale per modificare il timbro:
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
Combinazione di tag multipli
È possibile combinare il tag vocal-tract-length con qualsiasi altro tag SSML supportato da Amazon Polly. Poiché il timbro (la lunghezza del tratto vocale) e l'intonazione sono strettamente connessi, è possibile ottenere risultati ottimali utilizzando sia il tag vocal-tract-length che il tag <prosody
pitch>. Per ottenere una voce più realistica, consigliamo di utilizzare diverse percentuali per i valori di modifica dei due tag. Per ottenere i risultati desiderati, puoi fare più prove con le diverse combinazioni.
L'esempio seguente mostra come combinare i tag.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
Sussurrare
<amazon:effect name="whispered">
Questo tag è attualmente supportato solo dal formato TTS standard.
Questo tag indica che il testo di input deve essere pronunciato con una voce sussurrata rispetto a quella utilizzata normalmente. Può essere utilizzato con qualsiasi voce presente nel portafoglio Text-to-Speech (Sintesi vocale) di Amazon Polly.
Questo utilizza la sintassi seguente:
<amazon:effect name="whispered">text</amazon:effect>Ad esempio:
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
In questo caso, la sintesi vocale pronunciata dal personaggio è sussurrata, mentre la frase "she said" viene pronunciata con la voce normalmente utilizzata per la sintesi vocale di Amazon Polly selezionata.
Puoi aumentare l'effetto "sussurrato" rallentando la velocità dell'elemento prosody fino al 10%, in base all'effetto desiderato.
Ad esempio:
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
Durante la generazione di contrassegni vocali per una voce sussurrata, il flusso audio deve includere anche la voce sussurrata per assicurare la corrispondenza con i contrassegni vocali.
