Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Stati Aurora e macchine a stati Step Functions
Questa sezione descrive i processi e le macchine a stati specifici per il failover e il failback dei cluster Amazon Aurora. I cluster sono configurati come database globale.
Nota
A scopo dimostrativo, questo esempio utilizza Aurora MySQL Compatible Edition. È possibile utilizzare passaggi simili per Aurora PostgreSQL Compatible Edition.
Stato stazionario
Nello stato stazionario, è stato creato un database globale compatibile con Amazon Aurora MySQL dr-globaldb-cluster-mysql () con due cluster DB. Il primo cluster DB (db-cluster-01) è stato creato nel sistema primario Regione AWS
(us-east-1) per servire il carico di lavoro di lettura/scrittura. Il secondo cluster DB (db-cluster-02) è stato creato nella regione secondaria (us-west-2) per gestire il carico di lavoro di sola lettura.
Oltre a fornire la soluzione DR, è possibile ridurre il carico sul cluster DB primario instradando le query di lettura dalle applicazioni al cluster DB secondario. Ciascuno di questi cluster contiene un'istanza di database denominata dbcluster-01-use1-instance-1 edbcluster-02-usw2-instance-2, rispettivamente.
Stato dell'evento
Utilizzando un database globale di Amazon Aurora, puoi pianificare e ripristinare i dati in caso di emergenza abbastanza rapidamente. Il ripristino in caso di emergenza viene in genere misurato utilizzando i valori di Recovery Time Objective (RTO) e Recovery Point Objective (RPO). Per ulteriori informazioni, consulta Utilizzo dello switchover o del failover in un database globale Amazon Aurora.
Con un database globale Aurora, esistono due diversi approcci al failover:
-
Switchover (failover pianificato gestito)
-
Failover (failover manuale non pianificato o scollegamento e promozione)
Passaggio
Lo switchover è destinato ad ambienti controllati, come la manutenzione operativa e altre procedure operative pianificate. Utilizzando un failover pianificato gestito, è possibile trasferire il cluster DB primario del database globale Aurora in una delle regioni secondarie. Poiché lo switchover attende che i cluster DB secondari siano sincronizzati con il database primario, l'RPO è 0 (nessuna perdita di dati). Per ulteriori informazioni, consulta Esecuzione degli switchover per i database globali di Amazon Aurora.
La macchina a dr-orchestrator-stepfunction-FAILOVER stati viene richiamata durante lo stato dell'evento per trasferire il cluster primario alla regione secondaria prescelta (). us-west-2
Per eseguire lo switchover, effettuate le seguenti operazioni:
-
Accedi alla AWS Management Console.
-
Cambiate la regione nella regione DR ()
us-west-2. -
Vai a Services e scegli Step Functions.
-
Passa alla macchina a
dr-orchestrator-stepfunction-FAILOVERstati. -
Scegli Avvia esecuzione e inserisci il seguente codice JSON nella
Input - optionalsezione:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
La macchina a
dr-orchestrator-stepfunction-FAILOVERstati legge il tipo di risorsa comePlannedFailoverAuroraMySQL e chiama la macchina adr-orchestrator-stepfunction-planned-Aurora-failoverstati per eseguire il failover del database globale Aurora.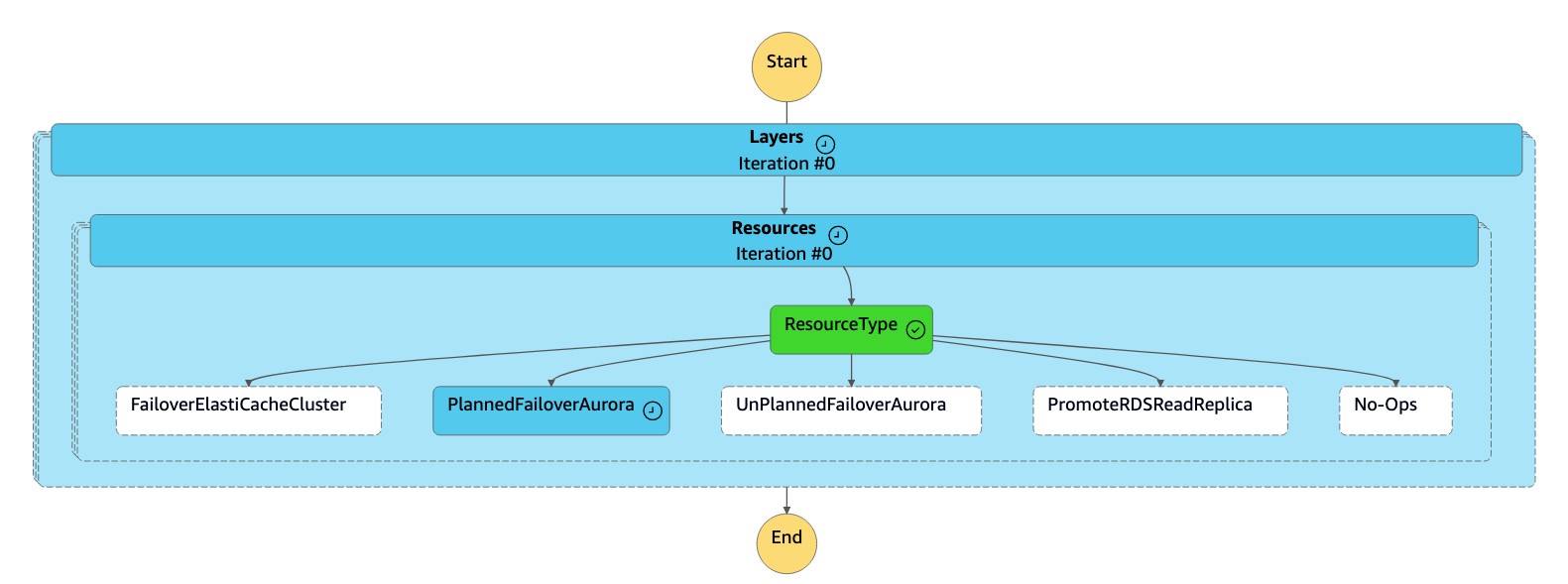
-
La macchina a
dr-orchestrator-stepfunction-planned-Aurora-failoverstati esegue i seguenti passaggi per passare al ruolo di database globale compatibile con Aurora MySQL.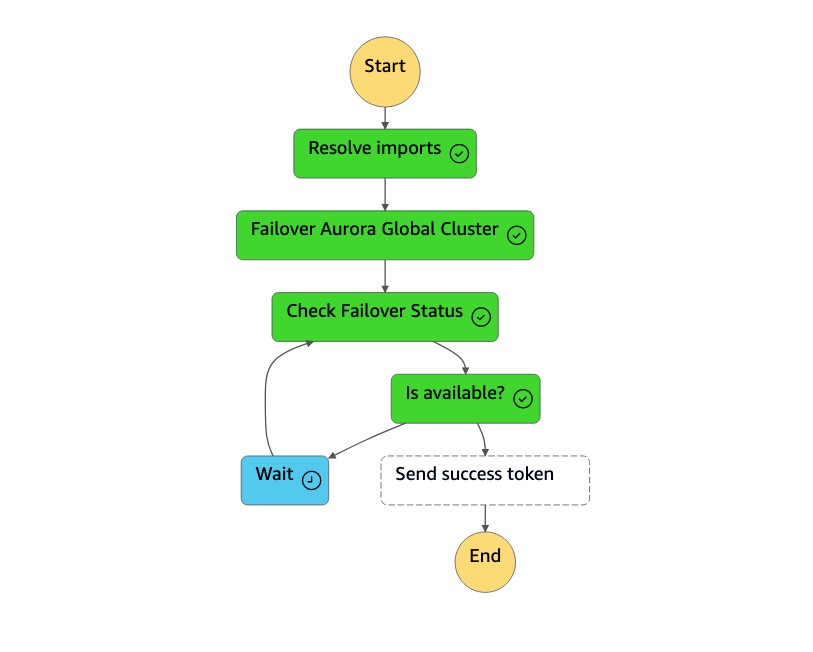
Fase Descrizione Valori previsti Risolvi le importazioni Una funzione Lambda sostituisce !Import <variable name>i valori con il nome effettivo."!Import dr-globaldb-cluster-mysql-global-identifier"viene sostituito da."dr-globaldb-cluster-mysql"Failover del cluster globale Aurora Una funzione Lambda chiama le API failover_global_cluster Boto3 per eseguire il failover del database globale Aurora. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Verifica lo stato del failover Una funzione Lambda chiama le API describe_db_clusters Boto3 per verificare lo stato del failover. modifica, disponibile Invia token di successo Una funzione Lambda chiama le API send_task_success Boto3 e invia un token di successo alla macchina a stati. DR Orchestrator FailoverRiCdLtdH7x dMccoxlzFhglsdkzp /83p1e0 K9MBvkzsp7d9yrt1w -
Accedi alla console Amazon RDS. In Status, i valori per il database globale Aurora cambieranno da Disponibile a Commutazione o Modifica.
-
Una volta completata, la macchina a
dr-orchestrator-stepfunction-planned-Aurora-failoverstati invia un token di successo alla macchina adr-orchestrator-stepfunction-FAILOVERstati.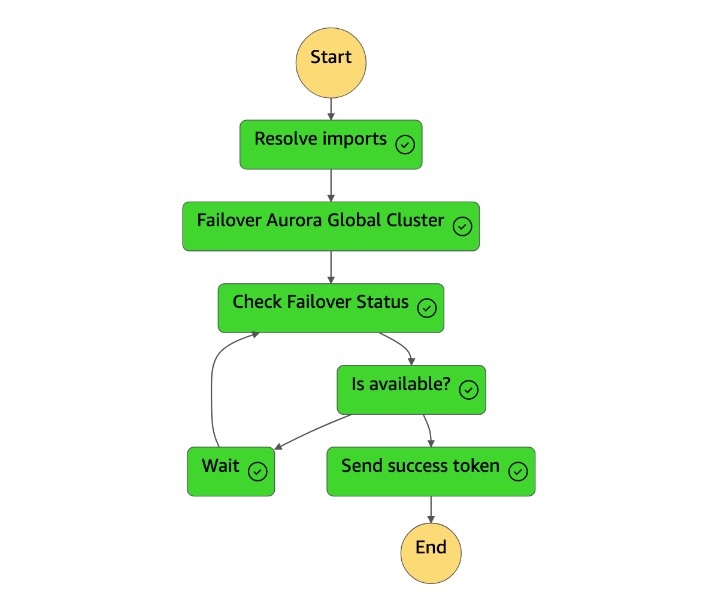
-
La macchina a
dr-orchestrator-stepfunction-FAILOVERstati è completata.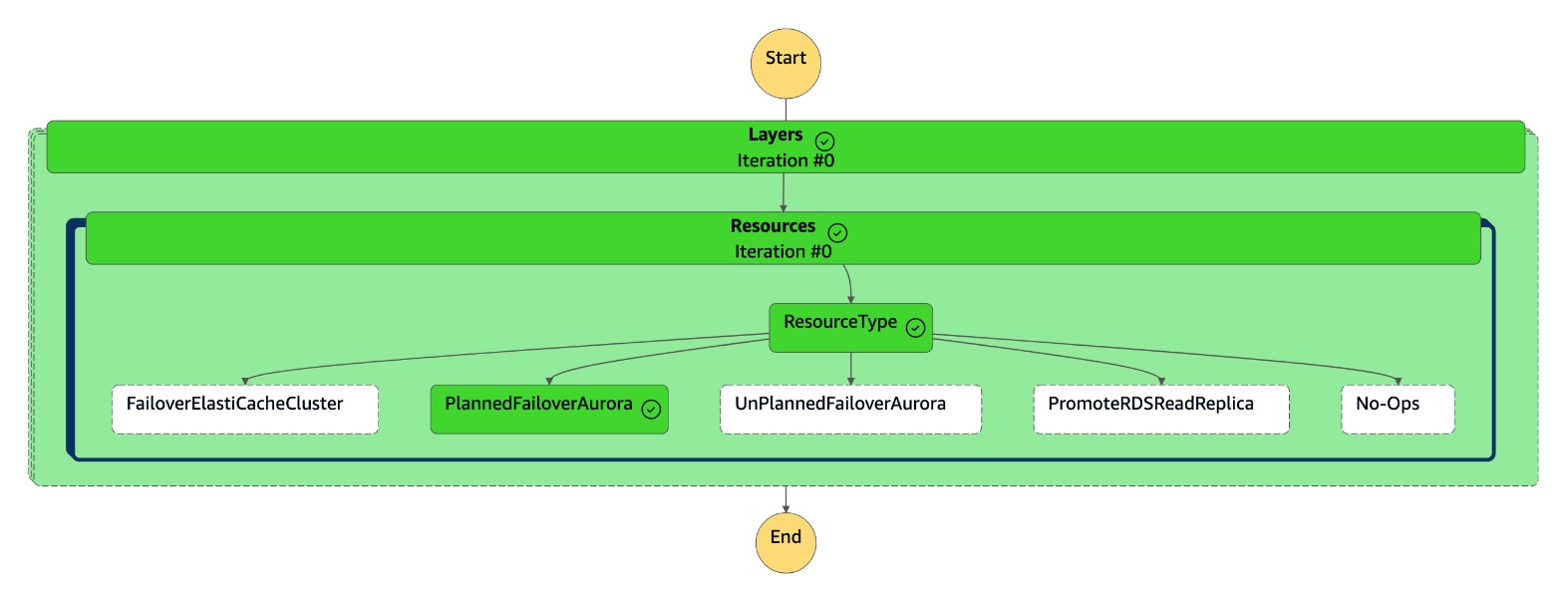
Sulla console, il ruolo del cluster secondario (dbcluster-02) è ora cluster primario e il cluster è pronto per servire carichi di lavoro di lettura/scrittura. Il ruolo del cluster primario originale (dbcluster-01) è ora elencato come Cluster secondario.
Failover manuale non pianificato
In rare occasioni, il database globale Aurora potrebbe subire un'interruzione imprevista del database primario. Regione AWS In questo caso, il cluster di database Aurora primario e il relativo nodo di scrittura non sono disponibili e la replica tra il cluster primario e i secondari cessa. Per ridurre al minimo sia i tempi di inattività (RTO) che la perdita di dati (RPO), lavora rapidamente per eseguire un failover tra regioni e ricostruire il database globale Aurora. Per ulteriori informazioni, consulta Ripristino di un database globale Amazon Aurora da un'interruzione non pianificata.
Per eseguire un failover non pianificato è necessario scollegare il cluster secondario dal database globale Aurora. Prima di eseguire il failover non pianificato, interrompi le scritture delle applicazioni sul cluster Aurora DB primario. Una volta completato correttamente il failover, riconfigura l'applicazione per la scrittura sul nuovo cluster DB primario. Questo approccio aiuta a prevenire la perdita di dati. Inoltre, aiuta a evitare incongruenze nei dati se il nodo di scrittura principale torna online durante il processo di failover.
Per eseguire il failover non pianificato, chiamate la macchina a stati. dr-orchestrator-stepfunction-FAILOVER In questo esempio, il cluster secondario (db-cluster-02) si trova nella regione DR (us-west-2) in stato stazionario.
Per eseguire il failover, effettuate le seguenti operazioni:
-
Accedi alla console .
-
Cambiate la regione nella regione DR (
us-west-2). -
Vai a Services e scegli Step Functions.
-
Passa alla macchina a
dr-orchestrator-stepfunction-FAILOVERstati. -
Scegli Avvia esecuzione e inserisci il seguente codice JSON nella
Input - optionalsezione, usandoUnPlannedFailoverAuroracome:resourceType{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
La macchina a
dr-orchestrator-stepfunction-FAILOVERstati legge il tipo di risorsaUnPlannedFailoverAuroraMySQLe chiama l'operazioneDetach Cluster from Global Databasedalla macchina adr-orchestrator-stepfunction-unplanned-Aurora-failoverstati.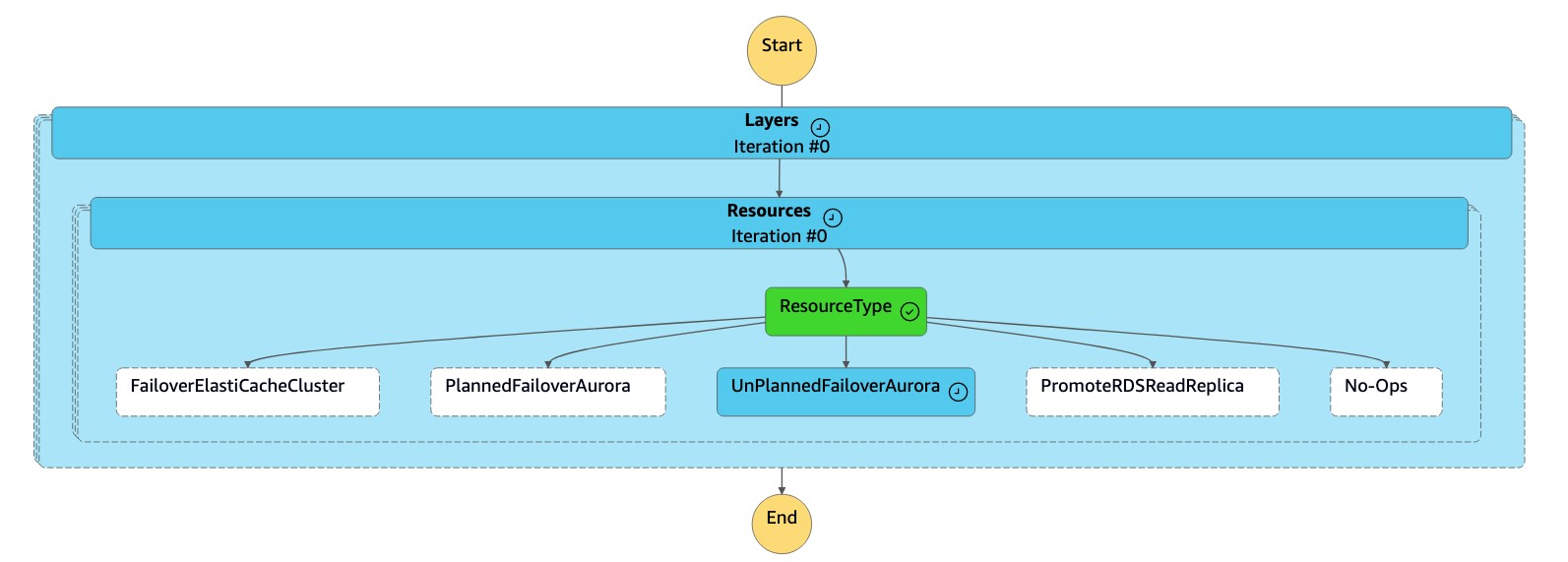
-
L'
Detach Cluster from Global Databaseattività scollega (rimuove) il cluster secondario dal database globale.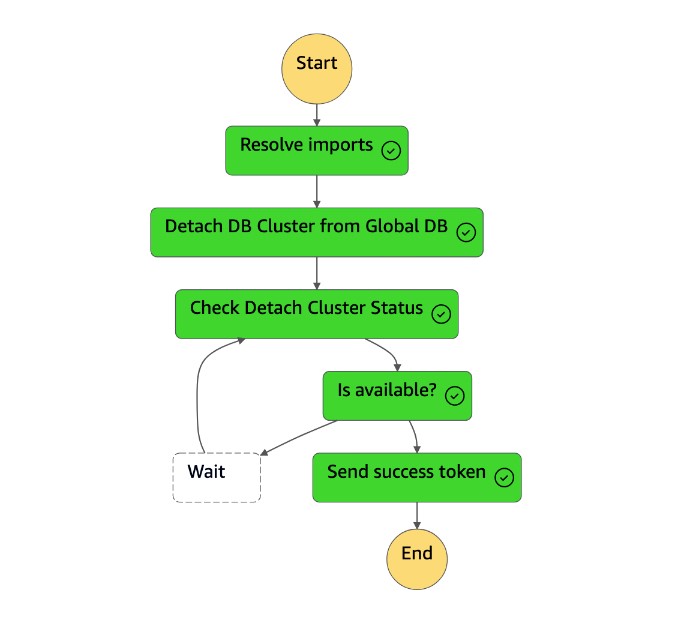
-
Il cluster secondario (
dbcluster-02) viene promosso a diventare un cluster autonomo e può servire carichi di lavoro di lettura/scrittura. -
La macchina a
dr-orchestrator-stepfunction-FAILOVERstati è completata.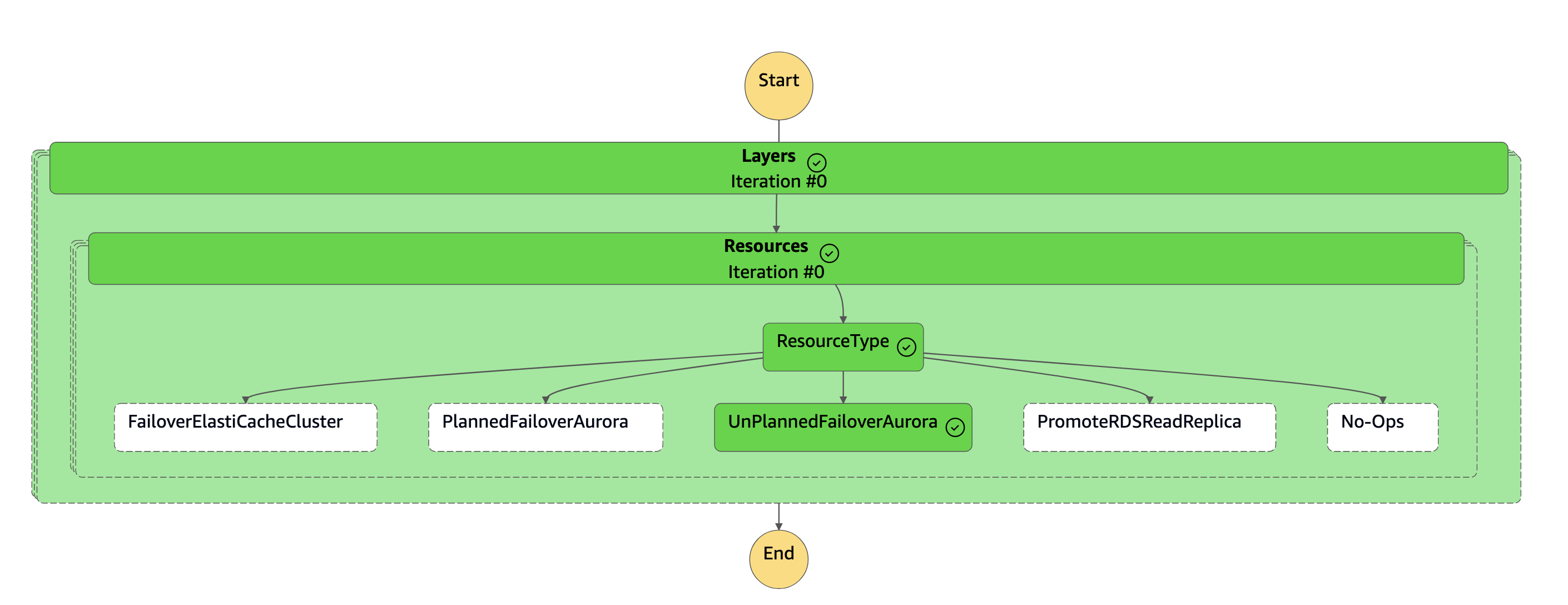
-
Il cluster secondario (
dbcluster-02) viene scollegato dal database globale Aurora e diventa un cluster autonomo per servire il carico di lavoro di lettura/scrittura. -
Riconfigura l'applicazione per inviare tutte le operazioni di scrittura a questo nuovo cluster Aurora DB autonomo utilizzando il suo nuovo endpoint del cluster.
Failback
Un failback riporta il database alla posizione principale originale (o nuova) dopo la risoluzione di un disastro (o di un evento pianificato). Una volta risolta l'interruzione non pianificata, potresti voler aggiungere nuovamente la tua regione principale precedente al database globale di Aurora. È necessario innanzitutto eliminare il cluster DB esistente dalla precedente regione primaria, creare un nuovo cluster DB dalla nuova regione primaria e quindi utilizzare il processo di failover pianificato gestito per passare al ruolo del nuovo cluster.
Questa può essere considerata un'attività pianificata che è possibile eseguire durante le ore non di punta o nei fine settimana.
È necessario modificare manualmente il cluster Amazon Aurora DB e disabilitarlo DeletionProtection prima di eseguire la macchina a DR Orchestrator FAILBACK stati dalla precedente regione primaria (us-east-1) perché è stata creata con. DeletionProtection
DR Orchestrator Framework utilizza la macchina a dr-orchestrator-stepfunction-FAILBACK stati per automatizzare i passaggi per eliminare il cluster esistente e creare un nuovo cluster nella precedente regione primaria.
Per disabilitarloDeletionProtection, procedi come segue:
-
Accedi alla console .
-
Cambia la regione con la precedente regione principale (
us-east-1). -
Accedi alla console Amazon RDS, seleziona il nome del cluster (
dbcluster-01) e scegli Modifica. -
In Protezione da eliminazione, deseleziona la casella di controllo Abilita protezione dall'eliminazione e scegli Continua.
-
Scegli Applica immediatamente, quindi scegli Modifica cluster.
La macchina a DR Orchestrator FAILBACK stati viene richiamata durante il processo di failback dalla precedente regione primaria ()us-east-1.
Per eseguire il failback, effettuate le seguenti operazioni:
-
Accedi alla console .
-
Cambia la regione con la precedente regione principale (
us-east-1). -
Vai a Servizi, quindi scegli Step Functions.
-
Passa alla macchina a
DR Orchestrator FAILBACKstati. -
Scegli Avvia esecuzione e inserisci il seguente codice JSON nella
Input - optionalsezione:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
La macchina a
DR Orchestrator FAILBACKstati legge il tipo di risorsa comeCreateAuroraSecondaryDBClustere chiama la macchina adr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstati.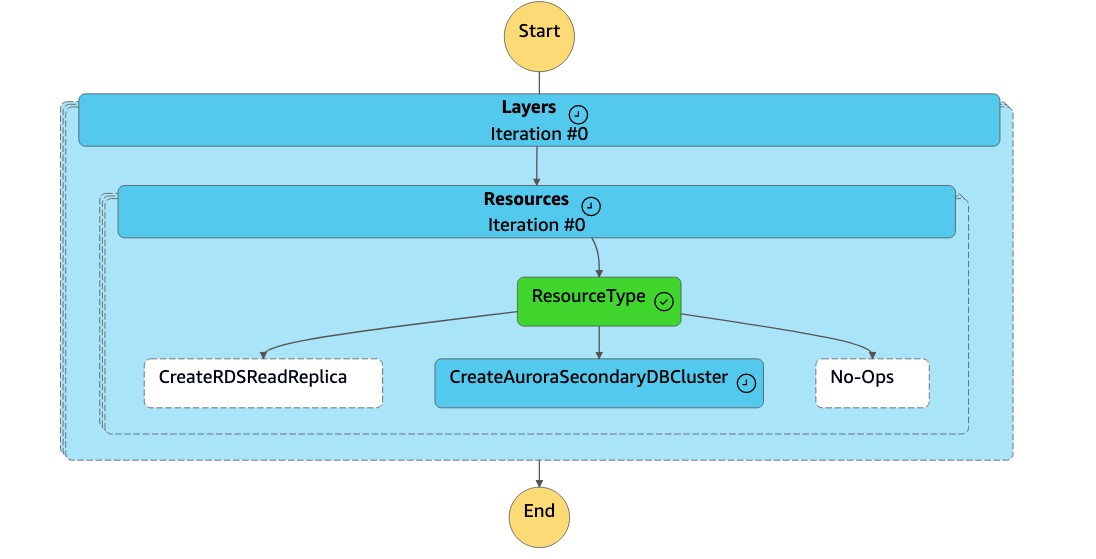
-
La macchina a
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstati elimina il cluster esistente (dbcluster-01) dalla precedente regione primaria (us-east-1).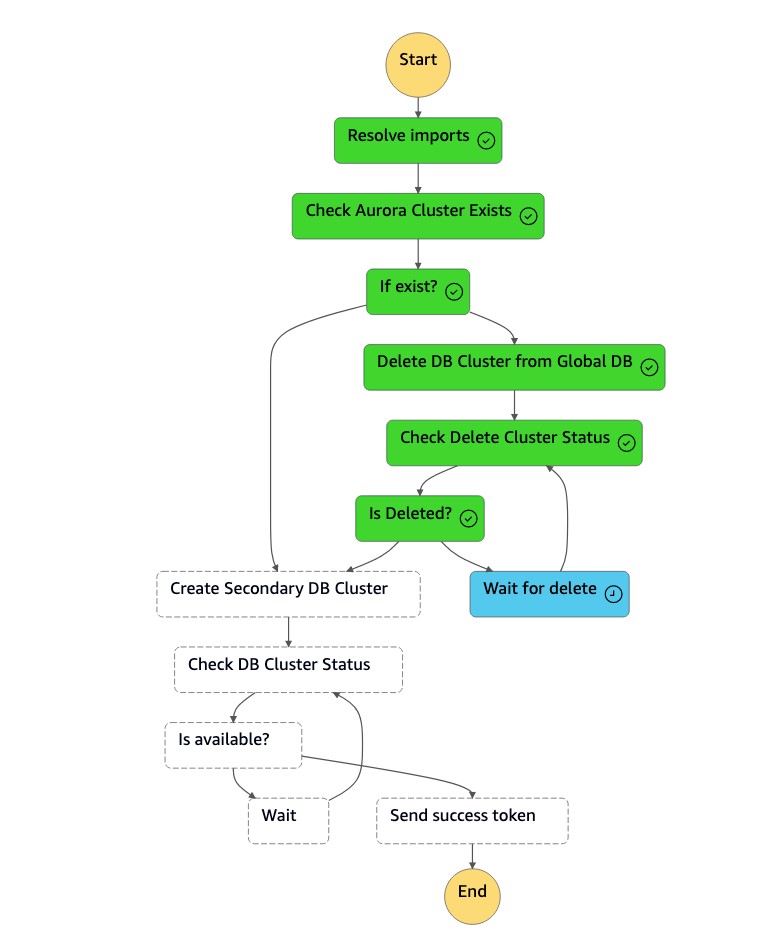
-
Dopo l'eliminazione del cluster (
dbcluster-01), la macchina a stati crea un nuovo cluster (dbcluster-01) insieme all'istanza DB e si unisce al database globale Aurora come cluster secondario per servire carichi di lavoro di sola lettura.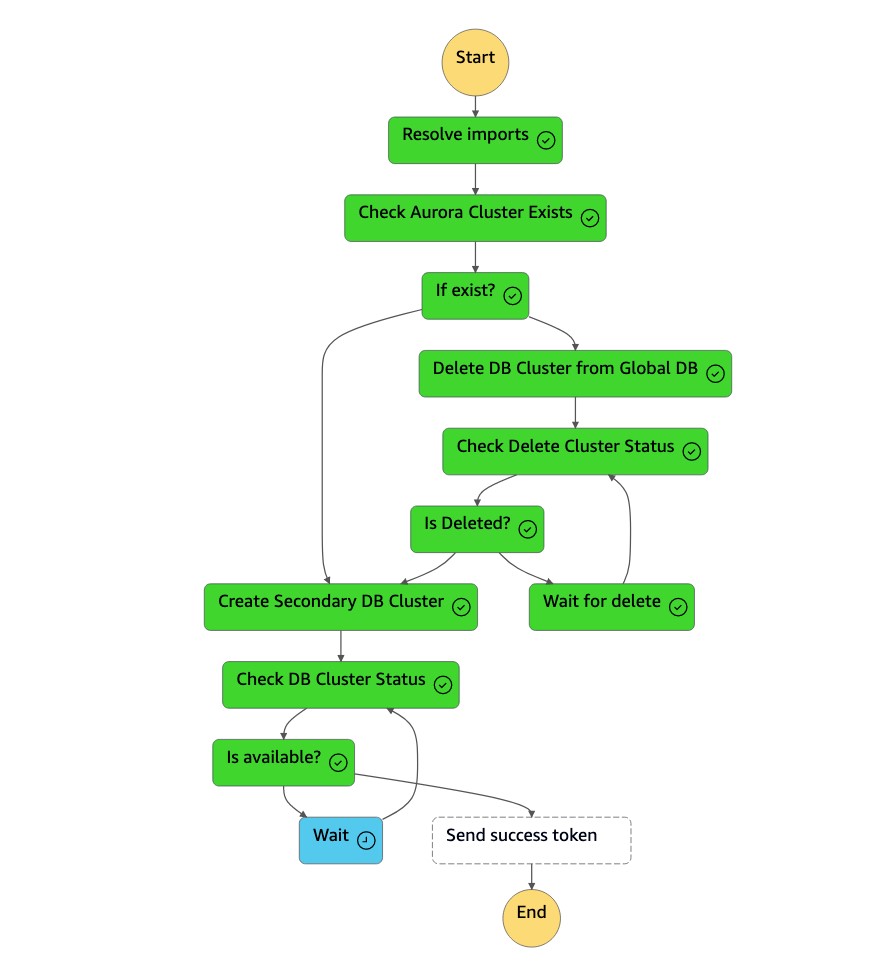
-
Una volta che il cluster secondario è disponibile, la
dr-orchestrator-stepfunction-create-Aurora-Secondary-clustermacchina a stati viene completata e invia un token di successo alla macchina aDR Orchestrator Failbackstati.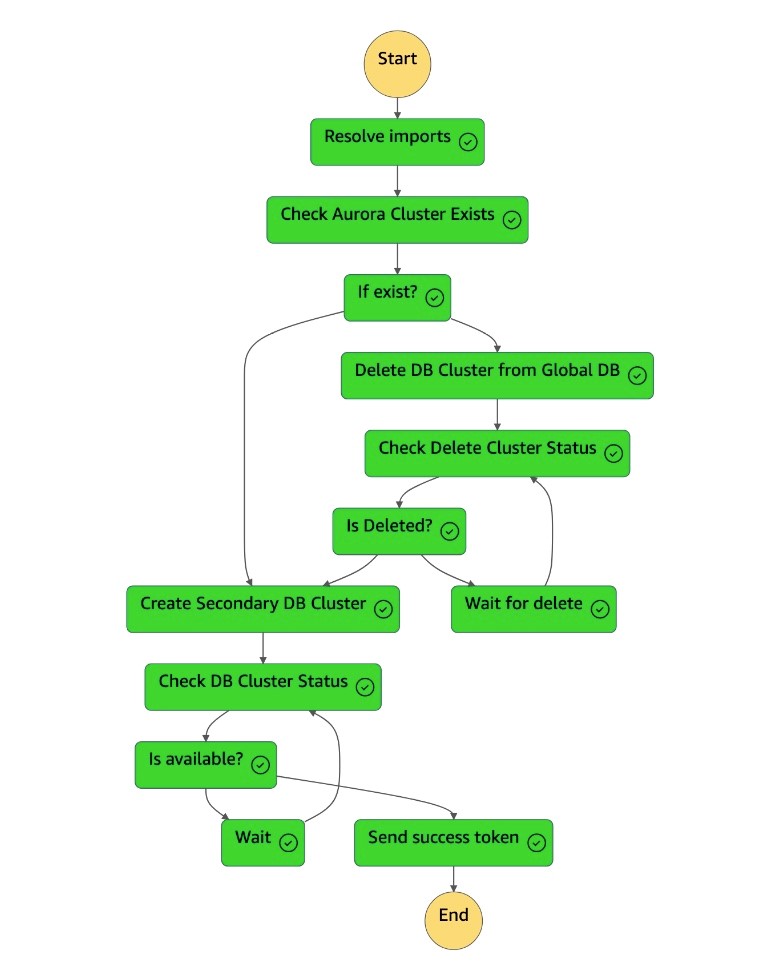
-
La
dr-orchestrator-stepfunction-FAILBACKmacchina a stati è completata.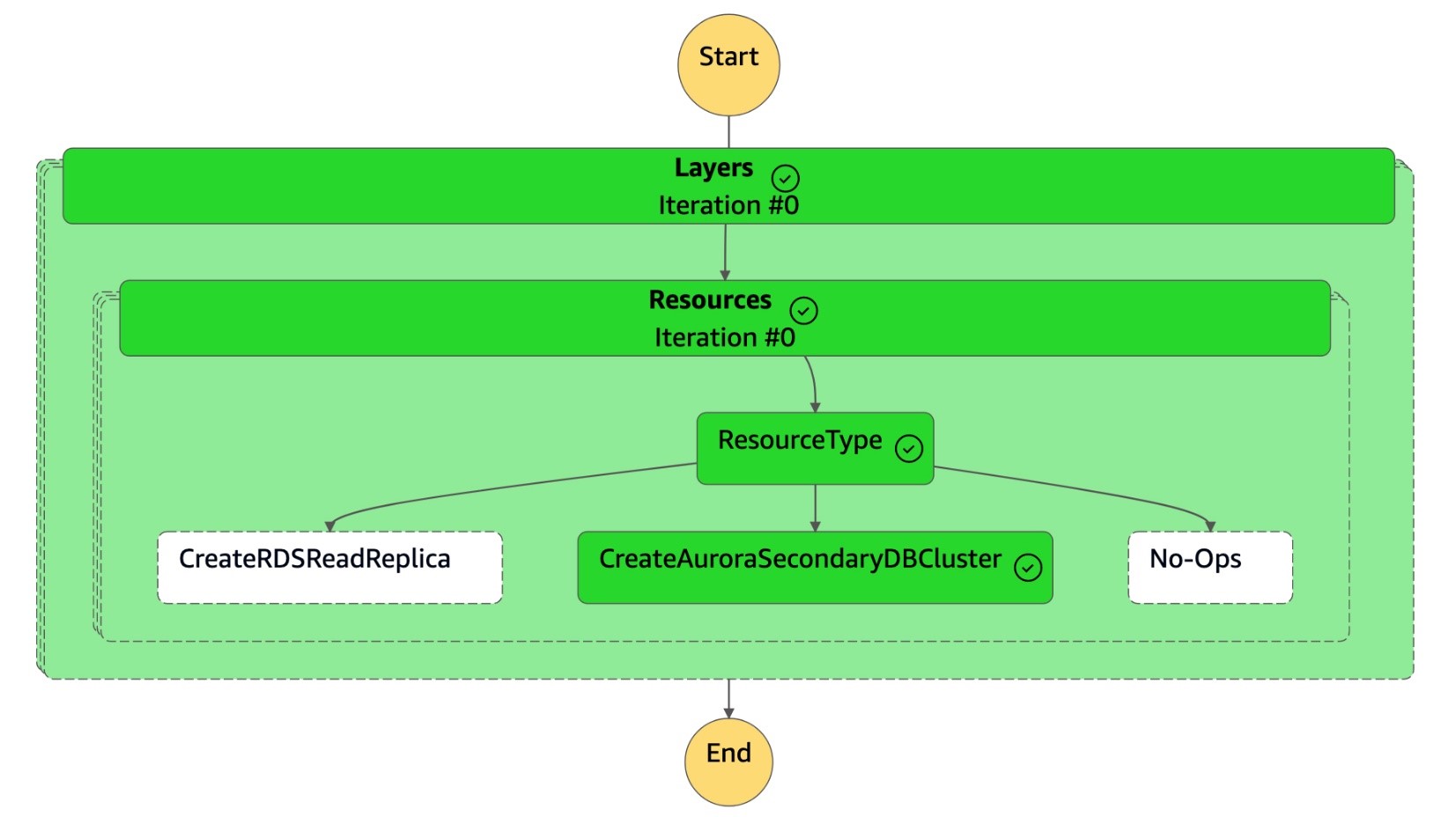
-
Puoi verificare il database globale Aurora sulla console Amazon RDS.
