Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Catalogo centralizzato
Il diagramma seguente mostra come il catalogo centralizzato collega i produttori di dati e i consumatori di dati nel data lake.
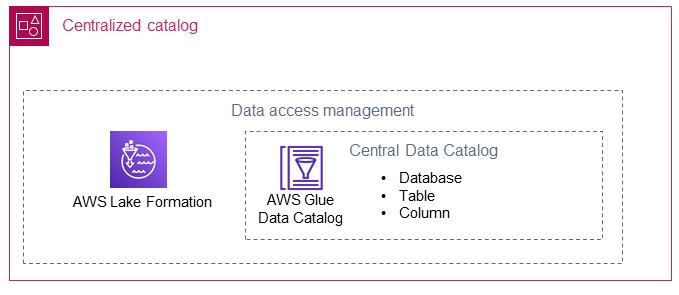
Il catalogo centralizzato archivia e gestisce il catalogo di dati condiviso per gli account dei produttori di dati. Il catalogo centralizzato ospita anche i metadati tecnici dei dati condivisi (ad esempio, il nome della tabella e lo schema) ed è il luogo in cui i consumatori di dati possono accedere ai dati.
I consumatori di dati possono accedere ai dati di più produttori di dati nel catalogo centralizzato e possono quindi combinare questi dati con i propri dati per un'ulteriore elaborazione. L'utilizzo di un catalogo centralizzato elimina la necessità per i consumatori di dati di connettersi direttamente con diversi produttori di dati e riduce il sovraccarico operativo.
Poiché il catalogo centralizzato offre visibilità sulla condivisione e sul consumo dei dati da parte dei produttori e dei consumatori di dati, può essere il luogo ideale per applicare le funzioni centralizzate di governance dei dati (ad esempio, il controllo degli accessi).
Le sezioni seguenti descrivono come il catalogo centralizzato utilizza e. AWS Lake Formation AWS Glue
AWS Lake Formation
AWS Lake Formationaiuta a creare database in un AWS Glue Data Catalog che puntano alle ubicazioni di più produttori di dati nel data lake. Viene creato un ruolo AWS Identity and Access Management (IAM) per Lake Formation nel catalogo centralizzato. Utilizzando Lake Formation, il catalogo centralizzato può condividere selettivamente le risorse di dati (ad esempio database, tabelle o colonne) con i consumatori di dati. Le risorse gestite da Lake Formation vengono condivise con i consumatori di dati utilizzando uno dei due metodi seguenti:
-
Metodo di risorse denominate: questo metodo condivide le risorse gestite tra gli account. È necessario specificare database, tabelle o nomi di colonne e una risorsa può essere condivisa con un'organizzazione, un'unità organizzativa (OU) o Account AWS. Per ridurre il sovraccarico di condivisione e gestione, si consiglia di condividere le risorse a livelli più elevati, ove possibile (ad esempio, in un'organizzazione o in un'unità organizzativa anziché in una Account AWS). Tuttavia, è necessario assicurarsi che questo approccio soddisfi i requisiti di controllo della sicurezza dei dati dell'organizzazione.
-
Nota: questo metodo è ideale per gli utenti di dati con un tipo di applicazione, in cui AWS i servizi utilizzano i dati del produttore di dati. Il requisito di accesso ai dati di questo tipo di consumatore di dati è basato sulle applicazioni, prescrittivo e relativamente statico.
-
-
Metodo di controllo degli accessi basato su tag Lake Formation (LF-TBAC): LF-TBAC è particolarmente utile per i consumatori di dati con un tipo di server dati. Tuttavia, le risorse con tag di Lake Formation possono attualmente essere condivise solo a Account AWS livello e non a livello di organizzazione o di unità organizzativa.
AWS Glue
È necessario creare database AWS Glue per ogni produttore di dati nel catalogo centralizzato. Poiché il catalogo centralizzato ospita i database AWS Glue di tutti i produttori di dati, devi assicurarti che il nome del database sia univoco per tutti i produttori di dati e che rifletta il produttore di dati e il relativo tipo di dati. Ad esempio, è possibile utilizzare la seguente struttura di denominazione del database: <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>— Il nome del produttore dei dati. -
<Environment>— L'ambiente del data lake, ad esempiodevper un ambiente di sviluppo,sitper un ambiente di test di integrazione di sistema oprodper un ambiente di produzione. -
<Data_Group>— Il nome del gruppo di dati utilizzato per separare i dati di un produttore di dati in gruppi logici. È possibile utilizzare il nome, l'ID o l'abbreviazione del sistema di origine come nome. La descrizione del database aiuta anche a descrivere il contenuto e lo scopo del database.
È possibile utilizzare un AWS Glue crawler sui dati del produttore di dati per mantenerne lo schema nel database centralizzato del catalogo. Se i dati vengono creati regolarmente sulla stessa frequenza da un produttore di dati, puoi utilizzare un solo crawler. AWS Glue In tutti gli altri casi, è necessario utilizzare più AWS Glue crawler per adattare frequenze di scansione diverse. A seconda del caso d'uso aziendale, il crawler può essere programmato per una frequenza predefinita o avviato da eventi.
Puoi anche mantenere lo schema della tabella AWS Glue chiamando l' AWS Glue API per creare o aggiornare lo schema. Sebbene ciò possa offrire flessibilità, sono necessari ulteriori sforzi per lo sviluppo e la manutenzione del codice. Assicurati di valutare il caso d'uso e il valore aziendale, quindi scegli l'opzione che soddisfa i tuoi requisiti e ha il minor costo generale.
