Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Sfide di scalabilità comuni
Un data lake attraversa diverse fasi quando i suoi dati crescono dopo la distribuzione iniziale. Se non hai utilizzato un'architettura scalabile per progettare il tuo data lake, la tua organizzazione potrebbe incontrare delle sfide e rischiare di essere svantaggiata dalla crescita del data lake.
Le sezioni seguenti spiegano come la crescita di un tipico data lake possa causare problemi di scalabilità.
Implementazione iniziale del data lake
Il diagramma seguente mostra l'architettura di un data lake dopo la sua implementazione iniziale da parte della linea di business A.
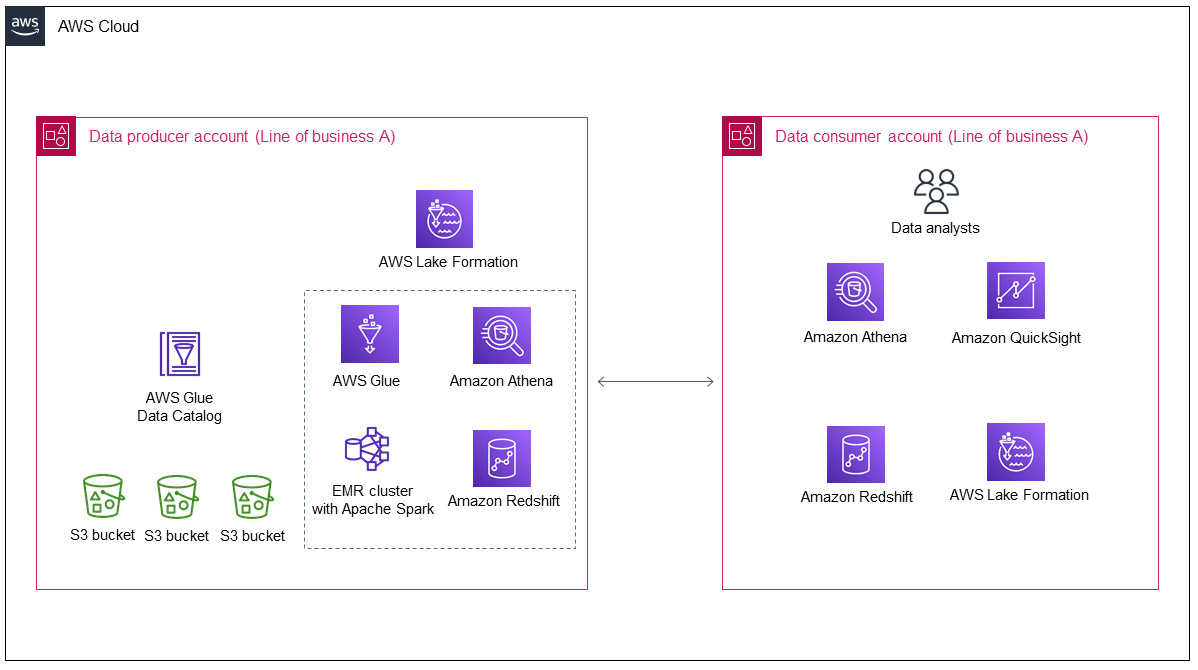
Il diagramma mostra i seguenti componenti:
-
L'account del produttore di dati raccoglie ed elabora i dati, archivia i dati elaborati e li prepara per il consumo.
-
I dati nell'account del produttore di dati vengono archiviati in bucket Amazon Simple Storage Service (Amazon S3), che possono avere più livelli di dati.
-
Puoi utilizzare AWS servizi per l'elaborazione dei dati (ad esempio, AWS Gluee Amazon EMR).
-
Il produttore di dati non solo produce e archivia dati nel data lake, ma deve anche decidere quali dati condividere con un consumatore di dati e come condividerli. AWS Lake Formation gestisce il data lake nell'account del produttore di dati, oltre a gestire la condivisione dei dati tra account dal produttore di dati al consumatore di dati.
-
L'account consumer di dati utilizza i dati condivisi dall'account del produttore di dati per casi d'uso aziendali specifici.
Aumentano i consumatori di dati
Il diagramma seguente mostra che più dati vengono immessi nel data lake quando i dati della Line of Business A crescono. Il data lake attira quindi più utenti di dati per sfruttare e ottenere valore dai dati.
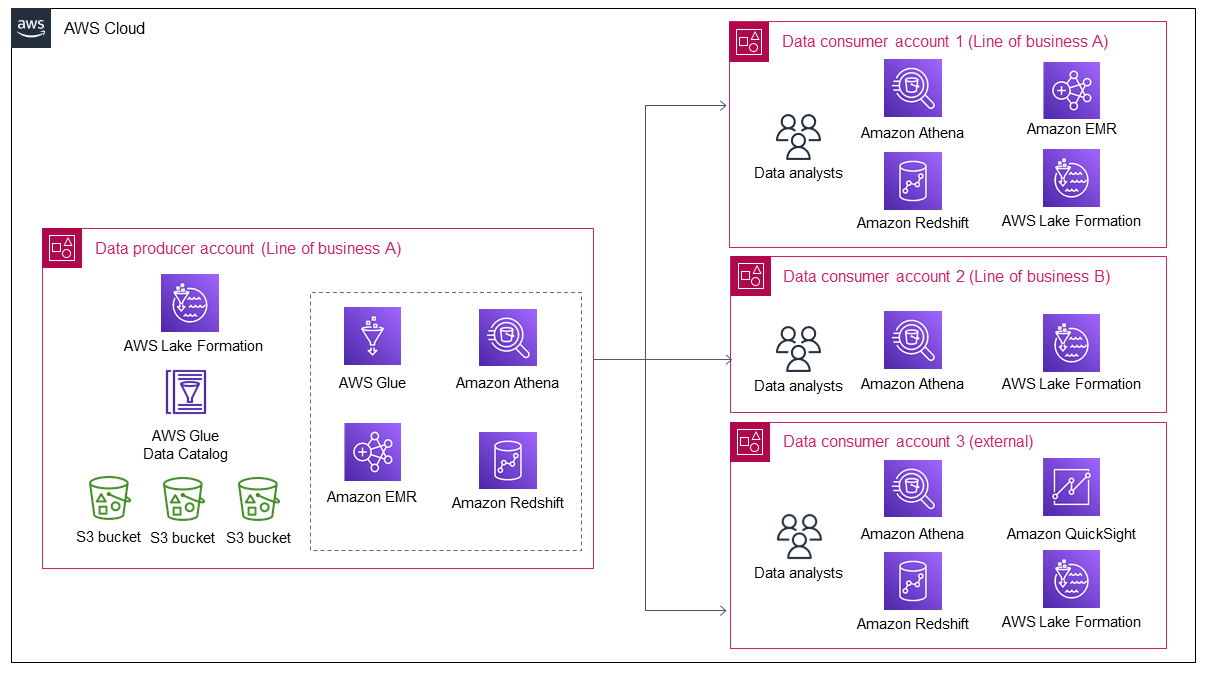
Il diagramma mostra come un'organizzazione generi valore quasi continuo da un asset di dati esistente e come ciò attiri sempre più consumatori di dati. Tuttavia, quando i consumatori di dati aumentano, il produttore di dati ha solo le seguenti due opzioni per far fronte a questa crescita:
-
Gestisci manualmente la condivisione e l'accesso ai dati da parte dei singoli consumatori di dati, il che non è un approccio scalabile.
-
Sviluppa un processo automatizzato o semiautomatico per la condivisione dei dati e la gestione dell'accesso ai dati. Sebbene questa possa essere un'opzione scalabile, richiede molto tempo e impegno per la progettazione e la creazione, poiché i consumatori di dati interni ed esterni hanno requisiti di controllo della sicurezza diversi. In futuro, saranno necessari anche tempi e sforzi aggiuntivi per eventuali miglioramenti della soluzione.
I produttori di dati aumentano
Il diagramma seguente mostra l'architettura del data lake quando più linee di business si uniscono come produttori di dati.
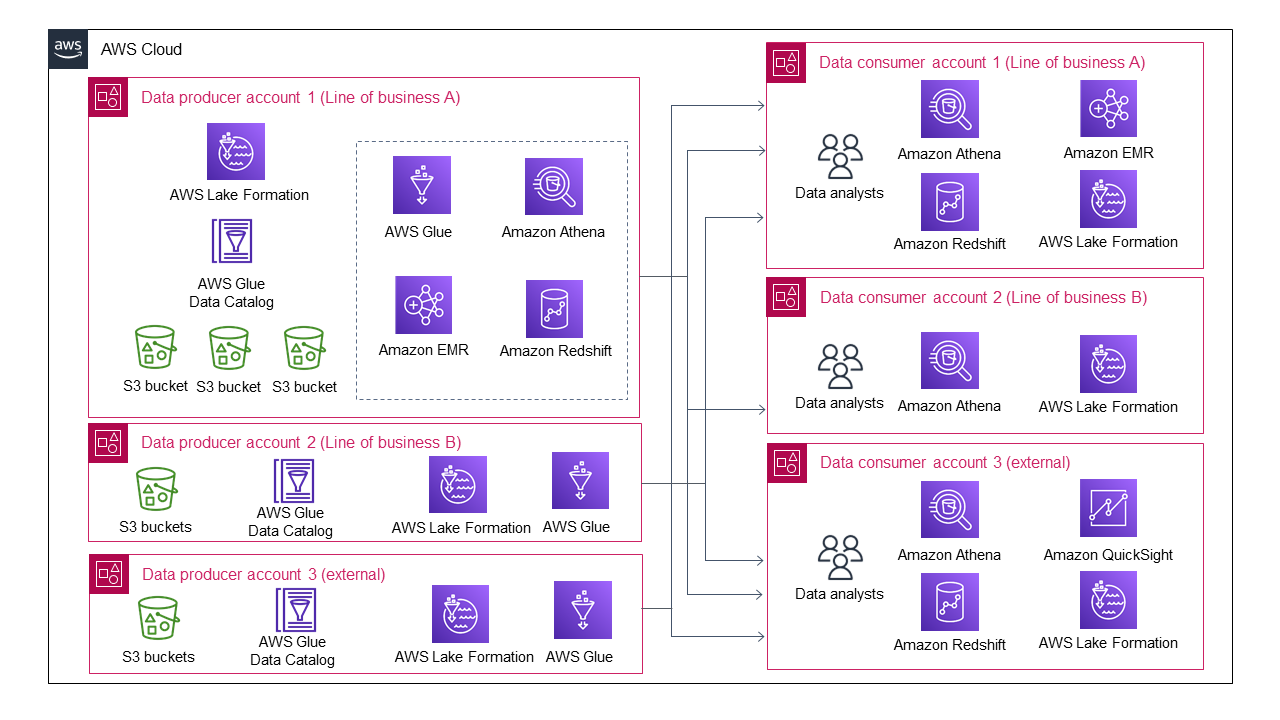
L'architettura del data lake diventa sempre più complicata, anche con solo tre produttori di dati e tre consumatori di dati.
Ogni produttore di dati deve gestire la condivisione e la gestione dell'accesso ai dati per più consumatori di dati. Non è realistico aspettarsi che tutti i produttori di dati sviluppino un processo automatizzato o semiautomatico per la condivisione dei dati e la gestione dell'accesso ai dati. Alcuni produttori di dati potrebbero scegliere di non condividere i propri dati e quindi evitare un sovraccarico di gestione insostenibile. Allo stesso modo, ogni consumatore di dati deve interagire con più produttori di dati per comprendere i diversi processi di consumo dei dati. Ciò significa che i singoli consumatori di dati devono affrontare un sovraccarico di gestione crescente per la gestione di diversi modelli di condivisione dei dati.
In molte organizzazioni, questo data lake causa problemi e non può crescere o scalare. Ciò potrebbe significare che l'organizzazione deve riprogettare e ricostruire il proprio data lake per eliminare il collo di bottiglia, che può costare molto tempo, risorse e denaro.
