Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Modelli di machine learning per la previsione della domanda di trasporto
L'immagine seguente mostra un esempio dei dati di addestramento. L'obiettivo è ciò che si desidera prevedere e le serie temporali correlate 1 e 2 sono caratteristiche di input rilevanti per prevedere l'obiettivo. I dati storici vengono utilizzati per l'addestramento e la convalida e l'utente trattiene un periodo dei dati storici per la convalida del modello.
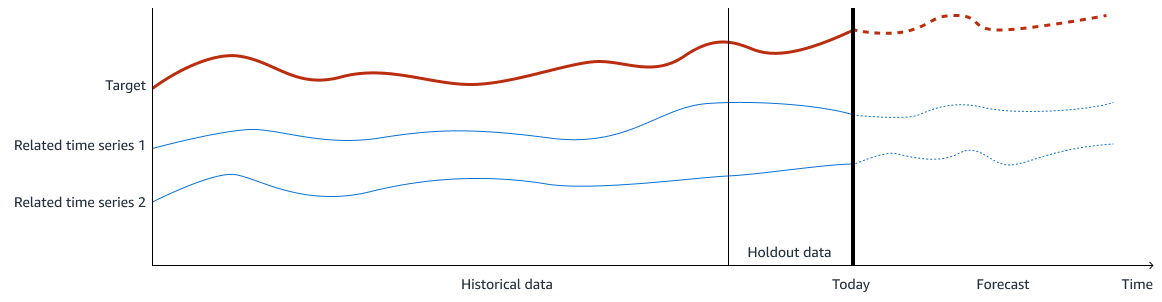
Nella previsione della domanda, l'output (o obiettivo) è il volume della domanda che si desidera prevedere. Le funzioni di input sono dati di serie temporali relativi all'output. Per addestrare un modello di machine learning a fare una previsione accurata del volume della domanda, nella soluzione sono necessari due modelli di machine learning. Il primo modello effettua una previsione delle serie temporali per le funzionalità di input, inclusi dati interni ed esterni. Il secondo modello effettua la previsione finale della domanda utilizzando tutte le funzionalità. Utilizzando questi due modelli insieme, è possibile acquisire in modo efficace sia l'andamento delle serie temporali che la relazione tra l'obiettivo e gli input.
Modello ML per la previsione delle funzionalità di input
Le funzionalità di input includono dati di serie temporali storiche interne ed esterne. Per fare previsioni per ogni feature, è possibile utilizzare un modello di serie temporali unidimensionale (1D). Sono disponibili vari algoritmi. Ad esempio, Prophet
Modello ML per la previsione della variabile target
Il modello ML per l'output, o il volume della domanda, è progettato per catturare la relazione tra tutte le funzionalità e l'output. È possibile utilizzare vari modelli di regressione supervisionata, ad esempio lassoridge regression, random forest e. XGBoost Quando si crea il modello e si individuano i parametri e gli iperparametri migliori, è possibile utilizzare i dati holdout. I dati holdout sono una parte di dati storici etichettati che viene trattenuta dal set di dati utilizzato per addestrare un modello di apprendimento automatico. È possibile utilizzare i dati holdout per valutare le prestazioni del modello confrontando le previsioni con i dati di holdout.
