Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Copertura e precisione dei documenti: nel dominio
Abbiamo confrontato le prestazioni predittive dei deep ensemble con il dropout applicato al momento del test, il dropout MC e una funzione softmax ingenua, come mostrato nel grafico seguente. Dopo l'inferenza, le previsioni con le maggiori incertezze sono state scartate a diversi livelli, ottenendo una copertura dati residua compresa tra il 10% e il 100%. Ci aspettavamo che l'insieme approfondito identificasse in modo più efficiente le previsioni incerte grazie alla sua maggiore capacità di quantificare l'incertezza epistemica, ovvero di identificare le aree nei dati in cui il modello ha meno esperienza. Ciò dovrebbe riflettersi in una maggiore precisione per i diversi livelli di copertura dei dati. Per ogni ensemble profondo, abbiamo utilizzato 5 modelli e applicato l'inferenza 20 volte. Per MC dropout, abbiamo applicato l'inferenza 100 volte per ogni modello. Abbiamo utilizzato lo stesso set di iperparametri e lo stesso modello di architettura per ogni metodo.
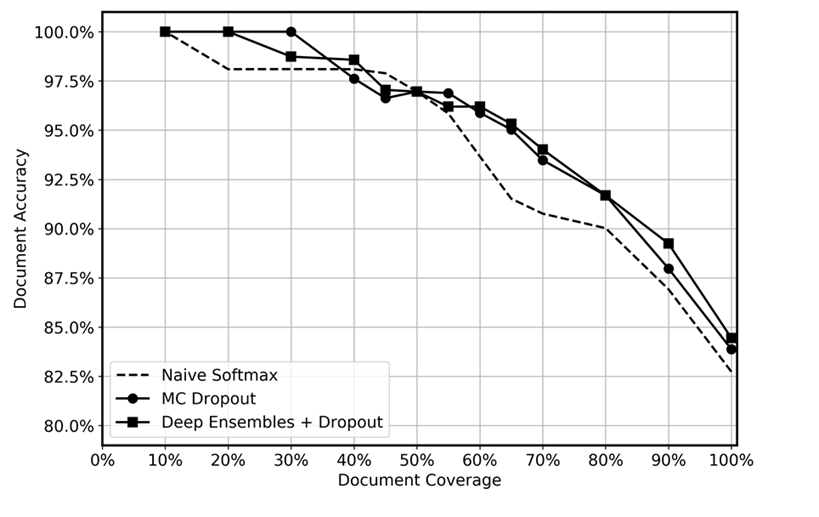
Il grafico sembra mostrare un leggero vantaggio nell'utilizzo di deep ensemble e MC dropout rispetto al softmax naïve. Ciò è particolarmente evidente nell'intervallo di copertura dei dati del 50-80%. Perché questo non è maggiore? Come accennato nella sezione sugli ensemble profondi, la forza degli insiemi profondi deriva dalle diverse traiettorie di perdita prese. In questa situazione, utilizziamo modelli preaddestrati. Sebbene ottimizziamo l'intero modello, la stragrande maggioranza dei pesi viene inizializzata dal modello preaddestrato e solo pochi livelli nascosti vengono inizializzati casualmente. Di conseguenza, ipotizziamo che l'addestramento preliminare di modelli di grandi dimensioni possa causare un'eccessiva fiducia a causa della scarsa diversificazione. Per quanto ne sappiamo, l'efficacia degli ensemble profondi non è mai stata testata in precedenza in scenari di transfer learning e riteniamo che questa sia un'area interessante per le ricerche future.
