Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Abbandono scolastico di Monte Carlo
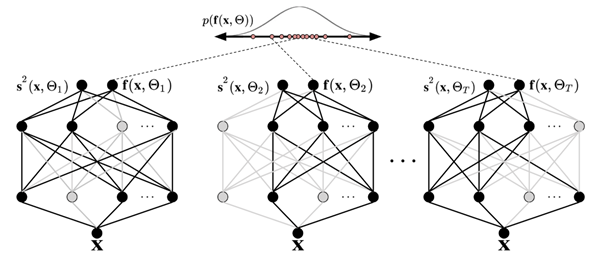
Uno dei modi più diffusi per stimare l'incertezza consiste nell'inferire distribuzioni predittive con reti neurali bayesiane. Per indicare una distribuzione predittiva, usa:
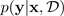
con obiettivi
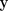
 , input e
, input e
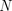 molti esempi
molti esempi
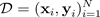 di formazione. Quando si ottiene una distribuzione predittiva, è possibile esaminare la varianza e scoprire l'incertezza. Un modo per apprendere una distribuzione predittiva richiede l'apprendimento di una distribuzione sulle funzioni o, in modo equivalente, di una distribuzione sui parametri (ovvero la distribuzione parametrica a posteriori).
di formazione. Quando si ottiene una distribuzione predittiva, è possibile esaminare la varianza e scoprire l'incertezza. Un modo per apprendere una distribuzione predittiva richiede l'apprendimento di una distribuzione sulle funzioni o, in modo equivalente, di una distribuzione sui parametri (ovvero la distribuzione parametrica a posteriori).
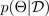
La tecnica di abbandono di Monte Carlo (MC) (Gal and Ghahramani 2016) offre un modo scalabile per apprendere una distribuzione predittiva. MC dropout funziona disattivando casualmente i neuroni in una rete neurale, che regolarizza la rete. Ogni configurazione dropout corrisponde a un campione diverso dalla distribuzione parametrica posteriore approssimativa:
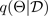
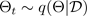
dove
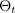 corrisponde a una configurazione dropout o, equivalentemente, a una simulazione ~, campionata dal parametro posteriore
approssimativo, come mostrato nella figura seguente. Il campionamento approssimativo a posteriori
consente l'integrazione Monte Carlo della verosimiglianza del modello, che rivela la distribuzione predittiva, nel modo seguente:
corrisponde a una configurazione dropout o, equivalentemente, a una simulazione ~, campionata dal parametro posteriore
approssimativo, come mostrato nella figura seguente. Il campionamento approssimativo a posteriori
consente l'integrazione Monte Carlo della verosimiglianza del modello, che rivela la distribuzione predittiva, nel modo seguente:
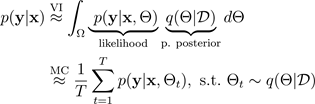
Per semplicità, si può presumere che la probabilità sia distribuita in modo gaussiano:
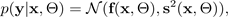
con la funzione gaussiana
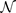 specificata dai
specificata dai
 parametri di media
parametri di media
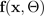 e varianza, generati dalle simulazioni del dropout di Monte Carlo BNN:
e varianza, generati dalle simulazioni del dropout di Monte Carlo BNN:
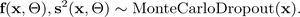
La figura seguente illustra MC dropout. Ogni configurazione di dropout produce un output diverso spegnendo e riaccendendo casualmente i neuroni (cerchi grigi) e riaccendendo (cerchi neri) ad ogni propagazione in avanti. Più passaggi in avanti con diverse configurazioni di dropout producono una distribuzione predittiva sulla media p (f (x, ø)).
Il numero di passaggi in avanti attraverso i dati dovrebbe essere valutato quantitativamente, ma 30-100 è un intervallo appropriato da considerare (Gal e Ghahramani 2016).
