Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ridimensionamento della temperatura
Nei problemi di classificazione, si presume che le probabilità previste (output softmax) rappresentino la vera probabilità di correttezza per la classe prevista. Tuttavia, anche se questa ipotesi potrebbe essere stata ragionevole per i modelli una decina di anni fa, non è vero per i moderni modelli di rete neurale (Guo et al. 2017). La perdita di connessione tra le probabilità di previsione del modello e la fiducia delle previsioni del modello impedirebbe l'applicazione dei moderni modelli di rete neurale nei problemi del mondo reale, come nei sistemi decisionali. Conoscere con precisione il punteggio di affidabilità delle previsioni dei modelli è una delle impostazioni di controllo del rischio più critiche necessarie per la creazione di applicazioni di machine learning affidabili e affidabili.
I moderni modelli di rete neurale tendono ad avere architetture di grandi dimensioni con milioni di parametri di apprendimento. La distribuzione delle probabilità di previsione in tali modelli è spesso altamente inclinata a 1 o 0, il che significa che il modello è troppo sicuro e il valore assoluto di queste probabilità potrebbe essere privo di significato. (Questo problema è indipendente dal fatto che lo squilibrio di classe sia presente nel set di dati.) Negli ultimi dieci anni sono stati sviluppati diversi metodi di calibrazione per la creazione di un punteggio di confidenza di previsione attraverso fasi di post-elaborazione per ricalibrare le probabilità ingenue del modello. Questa sezione descrive un metodo di calibrazione chiamatoscaling della temperatura, che è una tecnica semplice ma efficace per ricalibrare le probabilità di previsione (Guo et al. 2017). Il ridimensionamento della temperatura è una versione a parametro singolo di Platt Logistic Scaling (Platt 1999).
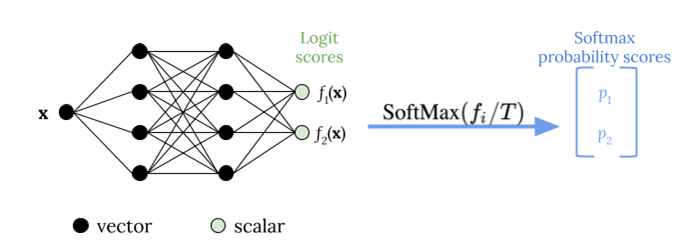
Il ridimensionamento della temperatura utilizza un unico parametro scalareT > 0, doveTè la temperatura, per ridimensionare i punteggi di logit prima di applicare la funzione softmax, come illustrato nella figura riportata di seguito. Perché lo stessoTviene utilizzato per tutte le classi, l'output softmax con scaling ha una relazione monotonica con output non scalato. QuandoT= 1, si recupera la probabilità originale con la funzione softmax predefinita. In modelli troppo sicuri in cuiT > 1, le probabilità ricalibrate hanno un valore inferiore alle probabilità originali e sono distribuite in modo più uniforme tra 0 e 1.
Il metodo per ottenere una temperatura ottimaleTper un modello addestrato consiste nel ridurre al minimo la probabilità di log negativa per un set di dati di convalida bloccato.
Si consiglia di integrare il metodo di scaling della temperatura come parte del processo di addestramento del modello: Una volta completato l'allenamento del modello, estrarre il valore della temperaturaTutilizzando il set di dati di convalida, quindi ridimensionando i valori di logit utilizzandoTnella funzione softmax. Sulla base di esperimenti in attività di classificazione testuale che utilizzano modelli basati su BERT, la temperaturaTdi solito scala tra 1,5 e 3.
Nella figura seguente viene illustrato il metodo di scaling della temperatura, che applica il valore della temperaturaTprima di passare il punteggio logit alla funzione softmax.
Le probabilità calibrate per scala della temperatura possono rappresentare approssimativamente il punteggio di affidabilità delle previsioni del modello. Questo può essere valutato quantitativamente creando un diagramma di affidabilità (Guo et al. 2017), che rappresenta l'allineamento tra la distribuzione dell'accuratezza prevista e la distribuzione delle probabilità di previsione.
Il ridimensionamento della temperatura è stato anche valutato come un modo efficace per quantificare l'incertezza predittiva totale nelle probabilità calibrate, ma non è robusto nel catturare l'incertezza epistemica in scenari come derive di dati (Ovadia et al. 2019). Considerando la facilità di implementazione, si consiglia di applicare il ridimensionamento della temperatura all'output del modello di deep learning per creare una soluzione robusta per quantificare le incertezze predittive.
