Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Preparazione e pulizia dei dati
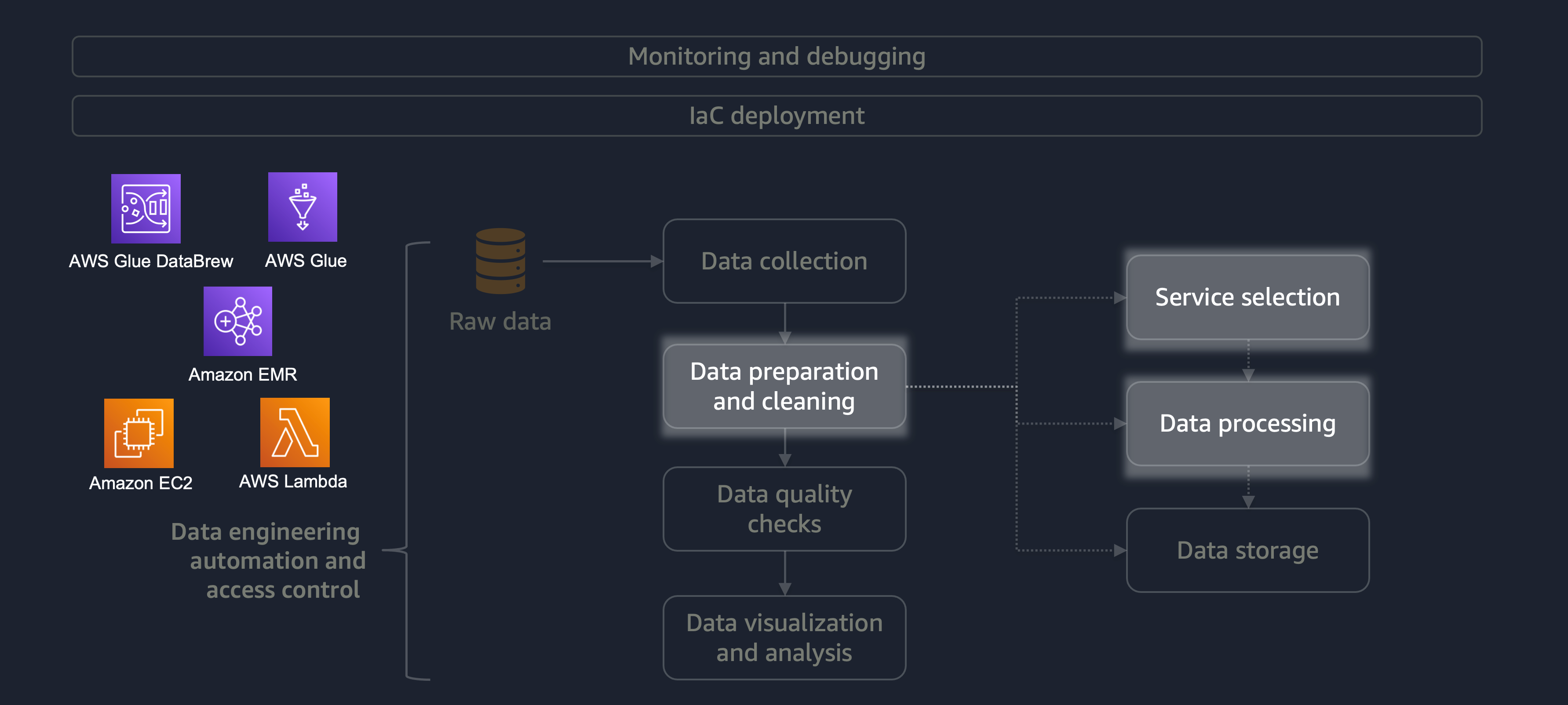
La preparazione e la pulizia dei dati sono una delle fasi più importanti ma più dispendiose in termini di tempo del ciclo di vita dei dati. Il diagramma seguente mostra come la fase di preparazione e pulizia dei dati si inserisce nel ciclo di vita dell'automazione del data engineering e del controllo degli accessi.
Ecco alcuni esempi di preparazione o pulizia dei dati:
-
Mappatura delle colonne di testo ai codici
-
Ignorare le colonne vuote
-
Riempimento di campi dati vuoti con
0None, o'' -
Anonimizzazione o mascheramento delle informazioni di identificazione personale (PII)
Se hai un carico di lavoro di grandi dimensioni con una varietà di dati, ti consigliamo di utilizzare Amazon EMR oDataFrame DynamicFrame Inoltre, puoi usare AWS Glue DataBrew
Per carichi di lavoro più piccoli che non richiedono un'elaborazione distribuita e possono essere completati in meno di 15 minuti, consigliamo di utilizzare AWS
È essenziale scegliere il servizio AWS giusto per la preparazione e la pulizia dei dati e comprendere i compromessi associati alla scelta. Ad esempio, considera uno scenario in cui scegli tra AWS Glue e Amazon EMR. DataBrew AWS Glue è ideale se il lavoro ETL è poco frequente. Un lavoro poco frequente viene svolto una volta al giorno, una volta alla settimana o una volta al mese. Puoi inoltre presumere che i tuoi data engineer siano esperti nella scrittura del codice Spark (per i casi d'uso dei big data) o nello scripting in generale. Se il lavoro è più frequente, eseguire costantemente AWS Glue può diventare costoso. In questo caso, Amazon EMR offre funzionalità di elaborazione distribuite e offre sia una versione serverless che una basata su server. Se i tuoi data engineer non hanno le competenze giuste o se devi fornire risultati rapidamente, questa DataBrew è una buona opzione. DataBrew può ridurre lo sforzo di sviluppo del codice e accelerare il processo di preparazione e pulizia dei dati.
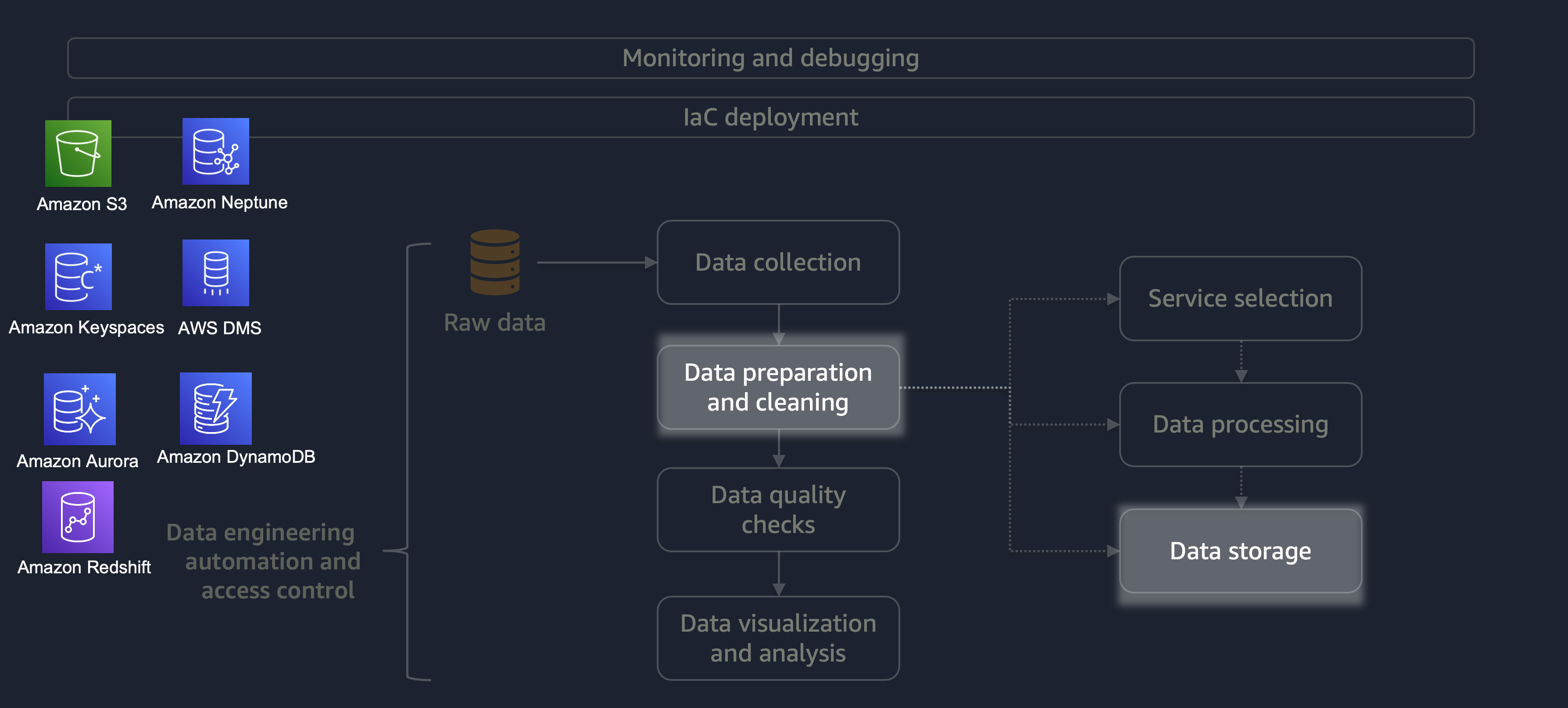
Una volta completata l'elaborazione, i dati del processo ETL vengono archiviati su AWS. La scelta dello storage dipende dal tipo di dati con cui hai a che fare. Ad esempio, potresti lavorare con dati non relazionali come dati grafici, dati di coppie chiave-valore, immagini, file di testo o dati strutturati relazionali.
Come illustrato nel diagramma seguente, puoi utilizzare i seguenti servizi AWS per lo storage dei dati:
-
Amazon S3
archivia dati non strutturati o dati semistrutturati (ad esempio file, immagini e video di Apache Parquet). -
Amazon Neptune
archivia set di dati grafici su cui è possibile interrogare utilizzando SPARQL o GREMLIN. -
Amazon Keyspaces (per Apache Cassandra)
archivia set di dati compatibili con Apache Cassandra. -
Amazon Aurora
archivia set di dati relazionali. -
Amazon DynamoDB
archivia dati chiave-valore o documento in un database NoSQL. -
Amazon Redshift
archivia i carichi di lavoro per i dati strutturati in un data warehouse.
Utilizzando il servizio giusto con le configurazioni corrette, è possibile archiviare i dati nel modo più efficiente ed efficace. Ciò riduce al minimo lo sforzo necessario per il recupero dei dati.
