Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esegui le query SQL di Amazon Redshift utilizzando Terraform
Sylvia Qi e Aditya Ambati, Amazon Web Services
Riepilogo
L'uso dell'infrastruttura come codice (IaC) per la distribuzione e la gestione di Amazon Redshift è una pratica prevalente all'interno. DevOps IaC facilita l'implementazione e la configurazione di varie risorse Amazon Redshift, come cluster, snapshot e gruppi di parametri. Tuttavia, IaC non si estende alla gestione di risorse di database come tabelle, schemi, viste e stored procedure. Questi elementi del database sono gestiti tramite query SQL e non sono supportati direttamente dagli strumenti IaC. Sebbene esistano soluzioni e strumenti per la gestione di queste risorse, potresti preferire non introdurre strumenti aggiuntivi nel tuo stack tecnologico.
Questo modello delinea una metodologia che utilizza Terraform per distribuire le risorse del database Amazon Redshift, tra cui tabelle, schemi, viste e stored procedure. Il modello distingue tra due tipi di query SQL:
Query non ripetibili: queste query vengono eseguite una sola volta durante la distribuzione iniziale di Amazon Redshift per stabilire i componenti essenziali del database.
Query ripetibili: queste query sono immutabili e possono essere rieseguite senza influire sul database. La soluzione utilizza Terraform per monitorare le modifiche nelle query ripetibili e applicarle di conseguenza.
Per maggiori dettagli, consulta la procedura dettagliata della soluzione in Informazioni aggiuntive.
Prerequisiti e limitazioni
Prerequisiti
È necessario disporre di un dispositivo attivo Account AWS e installare quanto segue sul computer di distribuzione:
AWS Command Line Interface (AWS CLI)
Un AWS CLI profilo configurato con le autorizzazioni di Amazon Redshift read/write
Terraform versione 1.6.2
o successiva
Limitazioni
Questa soluzione supporta un singolo database Amazon Redshift perché Terraform consente la creazione di un solo database durante la creazione del cluster.
Questo modello non include test per convalidare le modifiche alle query ripetibili prima di applicarle. Si consiglia di incorporare tali test per una maggiore affidabilità.
Per illustrare la soluzione, questo modello fornisce un file di esempio che utilizza un
redshift.tffile di stato Terraform locale. Tuttavia, per gli ambienti di produzione, si consiglia vivamente di utilizzare un file di stato remoto con un meccanismo di blocco per una maggiore stabilità e collaborazione.Alcuni Servizi AWS non sono disponibili in tutti. Regioni AWS Per la disponibilità per regione, vedi Servizi AWS per regione
. Per endpoint specifici, consulta Endpoints and quotas del servizio e scegli il link relativo al servizio.
Versioni del prodotto
Questa soluzione è stata sviluppata e testata sulla patch 179 di Amazon Redshift.
Repository di codice
Il codice per questo modello è disponibile nel repository GitHub amazon-redshift-sql-deploy-terraform
Architettura
Il diagramma seguente illustra come Terraform gestisce le risorse del database Amazon Redshift gestendo query SQL sia non ripetibili che ripetibili.
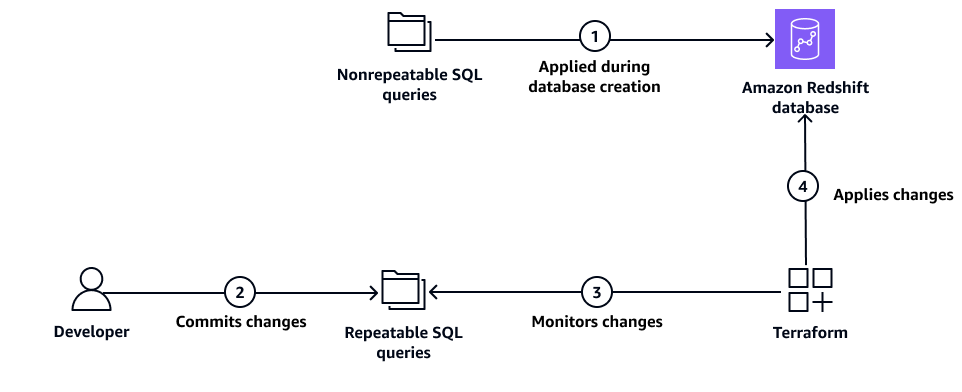
Il diagramma mostra i seguenti passaggi:
Terraform applica query SQL non ripetibili durante la distribuzione iniziale del cluster Amazon Redshift.
Lo sviluppatore apporta modifiche alle query SQL ripetibili.
Terraform monitora le modifiche nelle query SQL ripetibili.
Terraform applica query SQL ripetibili al database Amazon Redshift.
La soluzione fornita da questo modello è costruita sulla base del modulo Terraform per Amazon Redshiftterraform_data risorse, che richiamano uno script Python personalizzato per eseguire query SQL utilizzando l'operazione API Amazon Redshift. ExecuteStatement Di conseguenza, il modulo può eseguire le seguenti operazioni:
Distribuisci un numero qualsiasi di risorse del database utilizzando le query SQL dopo il provisioning del database.
Monitora continuamente le modifiche nelle query SQL ripetibili e applica tali modifiche utilizzando Terraform.
Per maggiori dettagli, consulta la procedura dettagliata della soluzione in Informazioni aggiuntive.
Strumenti
Servizi AWS
Amazon Redshift è un servizio di data warehouse su scala petabyte completamente gestito in. Cloud AWS
Altri strumenti
Best practice
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Clona il repository. | Per clonare il repository Git contenente il codice Terraform per il provisioning di un cluster Amazon Redshift, usa il seguente comando.
| DevOps ingegnere |
Aggiorna le variabili Terraform. | Per personalizzare la distribuzione del cluster Amazon Redshift in base ai tuoi requisiti specifici, aggiorna i seguenti parametri nel
| DevOps ingegnere |
Distribuisci le risorse utilizzando Terraform. |
| DevOps ingegnere |
(Facoltativo) Esegui query SQL aggiuntive. | Il repository di esempio fornisce diverse query SQL a scopo dimostrativo. Per eseguire le tue query SQL, aggiungile alle seguenti cartelle:
|
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Monitora la distribuzione delle istruzioni SQL. | Puoi monitorare i risultati delle esecuzioni SQL su un cluster Amazon Redshift. Per esempi di output che mostrano un'esecuzione SQL non riuscita e riuscita, consulta Esempi di istruzioni SQL in Informazioni aggiuntive. | DBA, ingegnere DevOps |
Eliminare le risorse. | Per eliminare tutte le risorse distribuite da Terraform, esegui il seguente comando.
| DevOps ingegnere |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Convalida i dati nel cluster Amazon Redshift. |
| DBA, AWS DevOps |
Risorse correlate
AWS documentazione
Altre risorse
Comando: apply
(documentazione Terraform)
Informazioni aggiuntive
Procedura dettagliata della soluzione
Per utilizzare la soluzione, è necessario organizzare le query SQL di Amazon Redshift in un modo specifico. Tutte le query SQL devono essere archiviate in file con estensione. .sql
Nell'esempio di codice fornito con questo modello, le query SQL sono organizzate nella seguente struttura di cartelle. È possibile modificare il codice (sql-queries.tfesql-queries.py) per utilizzarlo con qualsiasi struttura adatta al proprio caso d'uso specifico.
/bootstrap |- Any # of files |- Any # of sub-folders /nonrepeatable |- Any # of files |- Any # of sub-folders /repeatable /udf |- Any # of files |- Any # of sub-folders /table |- Any # of files |- Any # of sub-folders /view |- Any # of files |- Any # of sub-folders /stored-procedure |- Any # of files |- Any # of sub-folders /finalize |- Any # of files |- Any # of sub-folders
Data la struttura delle cartelle precedente, durante la distribuzione del cluster Amazon Redshift, Terraform esegue le query nel seguente ordine:
/bootstrap/nonrepeatable/repeatable/finalize
La /repeatable cartella contiene quattro sottocartelle:,, e. /udf /table /view /stored-procedure Queste sottocartelle indicano l'ordine in cui Terraform esegue le query SQL.
Lo script Python che esegue le query SQL è. sql-queries.py Innanzitutto, lo script legge tutti i file e le sottocartelle di una specifica directory di origine, ad esempio il parametro. sql_path_bootstrap Quindi lo script esegue le query richiamando l'operazione dell'API Amazon ExecuteStatementRedshift. Potresti avere una o più query SQL in un file. Il seguente frammento di codice mostra la funzione Python che esegue istruzioni SQL archiviate in un file su un cluster Amazon Redshift.
def execute_sql_statement(filename, cluster_id, db_name, secret_arn, aws_region): """Execute SQL statements in a file""" redshift_client = boto3.client( 'redshift-data', region_name=aws_region) contents = get_contents_from_file(filename), response = redshift_client.execute_statement( Sql=contents[0], ClusterIdentifier=cluster_id, Database=db_name, WithEvent=True, StatementName=filename, SecretArn=secret_arn ) ...
Lo script Terraform sql-queries.tf crea le risorse terraform_data che richiamano lo script.sql-queries.py Esiste una terraform_data risorsa per ciascuna delle quattro cartelle:/bootstrap,, e. /nonrepeatable /repeatable /finalize Il seguente frammento di codice mostra la terraform_data risorsa che esegue le query SQL nella cartella. /bootstrap
locals { program = "${path.module}/sql-queries.py" redshift_cluster_name = try(aws_redshift_cluster.this[0].id, null) } resource "terraform_data" "run_bootstrap_queries" { count = var.create && var.run_nonrepeatable_queries && (var.sql_path_bootstrap != "") && (var.snapshot_identifier == null) ? 1 : 0 depends_on = [aws_redshift_cluster.this[0]] provisioner "local-exec" { command = "python3 ${local.program} ${var.sql_path_bootstrap} ${local.redshift_cluster_name} ${var.database_name} ${var.redshift_secret_arn} ${local.aws_region}" } }
È possibile controllare se eseguire queste query utilizzando le seguenti variabili. Se non desideri eseguire query insql_path_bootstrap,, o sql_path_nonrepeatable sql_path_repeatablesql_path_finalize, imposta i relativi valori su. ""
run_nonrepeatable_queries = true run_repeatable_queries = true sql_path_bootstrap = "src/redshift/bootstrap" sql_path_nonrepeatable = "src/redshift/nonrepeatable" sql_path_repeatable = "src/redshift/repeatable" sql_path_finalize = "src/redshift/finalize"
Durante l'esecuzioneterraform apply, Terraform considera la terraform_data risorsa aggiunta dopo il completamento dello script, indipendentemente dai risultati dello script. Se alcune query SQL hanno avuto esito negativo e desideri eseguirle nuovamente, puoi rimuovere manualmente la risorsa dallo stato Terraform ed eseguirle di nuovo. terraform apply Ad esempio, il comando seguente rimuove la run_bootstrap_queries risorsa dallo stato Terraform.
terraform state rm module.redshift.terraform_data.run_bootstrap_queries[0]
Il seguente esempio di codice mostra come la run_repeatable_queries risorsa monitora le modifiche nella repeatable cartella utilizzando l'hash sha256terraform apply
resource "terraform_data" "run_repeatable_queries" { count = var.create_redshift && var.run_repeatable_queries && (var.sql_path_repeatable != "") ? 1 : 0 depends_on = [terraform_data.run_nonrepeatable_queries] # Continuously monitor and apply changes in the repeatable folder triggers_replace = { dir_sha256 = sha256(join("", [for f in fileset("${var.sql_path_repeatable}", "**") : filesha256("${var.sql_path_repeatable}/${f}")])) } provisioner "local-exec" { command = "python3 ${local.sql_queries} ${var.sql_path_repeatable} ${local.redshift_cluster_name} ${var.database_name} ${var.redshift_secret_arn}" } }
Per perfezionare il codice, puoi implementare un meccanismo per rilevare e applicare le modifiche solo ai file che sono stati aggiornati all'interno della repeatable cartella, anziché applicare le modifiche a tutti i file indiscriminatamente.
Esempi di istruzioni SQL
L'output seguente mostra un'esecuzione SQL non riuscita, insieme a un messaggio di errore.
module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Executing: ["/bin/sh" "-c" "python3 modules/redshift/sql-queries.py src/redshift/nonrepeatable testcluster-1 db1 arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:/redshift/master_user/password-8RapGH us-east-1"] module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): src/redshift/nonrepeatable/table/admin/admin.application_family.sql module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Status: FAILED module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): SQL execution failed. module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Error message: ERROR: syntax error at or near ")" module.redshift.terraform_data.run_nonrepeatable_queries[0] (local-exec): Position: 244 module.redshift.terraform_data.run_nonrepeatable_queries[0]: Creation complete after 3s [id=ee50ba6c-11ae-5b64-7e2f-86fd8caa8b76]
L'output seguente mostra un'esecuzione SQL riuscita.
module.redshift.terraform_data.run_bootstrap_queries[0]: Provisioning with 'local-exec'... module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): Executing: ["/bin/sh" "-c" "python3 modules/redshift/sql-queries.py src/redshift/bootstrap testcluster-1 db1 arn:aws:secretsmanager:us-east-1:XXXXXXXXXXXX:secret:/redshift/master_user/password-8RapGH us-east-1"] module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): src/redshift/bootstrap/db.sql module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): ------------------------------------------------------------------- module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): Status: FINISHED module.redshift.terraform_data.run_bootstrap_queries[0] (local-exec): SQL execution successful. module.redshift.terraform_data.run_bootstrap_queries[0]: Creation complete after 2s [id=d565ef6d-be86-8afd-8e90-111e5ea4a1be]
