Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esegui la migrazione dei dati Hadoop su Amazon S3 utilizzando Migrator WANdisco LiveData
Tony Velcich, Amazon Web Services
Riepilogo
Questo modello descrive il processo di migrazione dei dati di Apache Hadoop da un Hadoop Distributed File System (HDFS) ad Amazon Simple Storage Service (Amazon S3). Utilizza WANdisco LiveData Migrator per automatizzare il processo di migrazione dei dati.
Prerequisiti e limitazioni
Prerequisiti
Nodo edge del cluster Hadoop in cui LiveData verrà installato Migrator. Il nodo deve soddisfare i seguenti requisiti:
Specifiche minime: 4 CPUs, 16 GB di RAM, 100 GB di spazio di archiviazione.
Rete minima 2 Gbps.
Porta 8081 accessibile sul nodo perimetrale per accedere all' WANdisco interfaccia utente.
Java 1.8 a 64 bit.
Librerie client Hadoop installate sul nodo perimetrale.
Capacità di autenticarsi come superutente HDFS
(ad esempio, «hdfs»). Se Kerberos è abilitato sul cluster Hadoop, sul nodo edge deve essere disponibile un keytab valido che contenga un principal adatto per il superutente HDFS.
Un account AWS attivo con accesso a un bucket S3.
Un collegamento AWS Direct Connect stabilito tra il cluster Hadoop locale (in particolare il nodo perimetrale) e AWS.
Versioni del prodotto
LiveData Migrator 1.8.6
WANdisco Interfaccia utente (OneUI) 5.8.0
Architettura
Stack di tecnologia di origine
Cluster Hadoop locale
Stack tecnologico Target
Amazon S3
Architettura
Il diagramma seguente mostra l'architettura della soluzione LiveData Migrator.
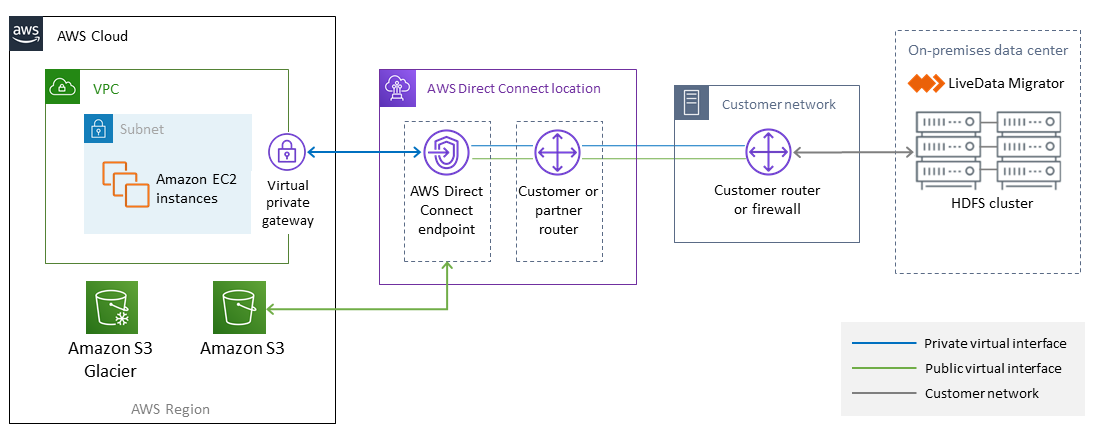
Il flusso di lavoro è composto da quattro componenti principali per la migrazione dei dati da HDFS locali ad Amazon S3.
LiveData Migrator
: automatizza la migrazione dei dati da HDFS ad Amazon S3 e risiede su un nodo perimetrale del cluster Hadoop. HDFS
: un file system distribuito che fornisce un accesso ad alta velocità ai dati delle applicazioni. Amazon S3
: un servizio di storage di oggetti che offre scalabilità, disponibilità dei dati, sicurezza e prestazioni. AWS Direct Connect: un servizio che stabilisce una connessione di rete dedicata dai data center locali ad AWS.
Automazione e scalabilità
In genere si creano più migrazioni in modo da poter selezionare contenuti specifici dal file system di origine per percorso o directory. È inoltre possibile migrare i dati su più file system indipendenti contemporaneamente definendo più risorse di migrazione.
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Accedere all'account AWS. | Accedi alla Console di gestione AWS e apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/ | Esperienza AWS |
Crea un bucket S3. | Se non disponi già di un bucket S3 esistente da utilizzare come storage di destinazione, scegli l'opzione «Create bucket» sulla console Amazon S3 e specifica il nome del bucket, la regione AWS e le impostazioni del bucket per bloccare l'accesso pubblico. AWS e ti WANdisco consigliamo di abilitare le opzioni di accesso pubblico a blocchi per il bucket S3 e di configurare le politiche di accesso ai bucket e di autorizzazione degli utenti per soddisfare i requisiti della tua organizzazione. Un esempio di AWS è fornito all'indirizzo https://docs.aws.amazon.com/AmazonS3/ latest/dev/example - walkthroughs-managing-access-example 1.html. | Esperienza AWS |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Scarica il programma di installazione di LiveData Migrator. | Scarica il programma di installazione di LiveData Migrator e caricalo sul nodo edge di Hadoop. Puoi scaricare una versione di prova gratuita di Migrator all'indirizzo /aws.amazon. LiveData https://www2.wandisco.com/ldm-trial. You can also obtain access to LiveData Migrator from AWS Marketplace, at https:/ com/marketplace/pp/B07B8. SZND9 | Amministratore Hadoop, proprietario dell'applicazione |
Installa LiveData Migrator. | Usa il programma di installazione scaricato e installa LiveData Migrator come superutente HDFS su un nodo perimetrale del tuo cluster Hadoop. Vedi la sezione «Informazioni aggiuntive» per i comandi di installazione. | Amministratore Hadoop, proprietario dell'applicazione |
Controlla lo stato di LiveData Migrator e di altri servizi. | Controlla lo stato di LiveData Migrator, Hive migrator e WANdisco UI utilizzando i comandi forniti nella sezione «Informazioni aggiuntive». | Amministratore Hadoop, proprietario dell'applicazione |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Registra il tuo account LiveData Migrator. | Accedi all' WANdisco interfaccia utente tramite un browser Web sulla porta 8081 (sul nodo edge Hadoop) e fornisci i tuoi dati per la registrazione. Ad esempio, se esegui LiveData Migrator su un host denominato myldmhost.example.com, l'URL sarebbe: http://myldmhost.example.com:8081 | Proprietario dell'applicazione |
Configura lo storage HDFS di origine. | Fornisci i dettagli di configurazione necessari per lo storage HDFS di origine. Ciò includerà il valore «fs.defaultFS» e un nome di archiviazione definito dall'utente. Se Kerberos è abilitato, fornite la posizione principale e keytab da utilizzare per Migrator. LiveData Se NameNode HA è abilitato sul cluster, fornisci un percorso ai file core-site.xml e hdfs-site.xml sul nodo perimetrale. | Amministratore Hadoop, proprietario dell'applicazione |
Configura lo storage Amazon S3 di destinazione. | Aggiungi lo storage di destinazione come tipo S3a. Fornisci il nome di storage definito dall'utente e il nome del bucket S3. Inserisci «org.apache.hadoop.fs.s3a.Simple AWSCredentials Provider» per l'opzione Credentials Provider e fornisci l'accesso AWS e le chiavi segrete per il bucket S3. Saranno inoltre necessarie proprietà S3a aggiuntive. Per i dettagli, consulta la sezione «Proprietà S3a» nella documentazione di LiveData Migrator all'indirizzo docs/command-reference/# 3a. https://docs.wandisco.com/live-data-migrator/ filesystem-add-s | AWS, proprietario dell'applicazione |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Aggiungi esclusioni (se necessario). | Se desideri escludere set di dati specifici dalla migrazione, aggiungi le esclusioni per lo storage HDFS di origine. Queste esclusioni possono essere basate sulla dimensione del file, sui nomi dei file (basati su modelli regex) e sulla data di modifica. | Amministratore Hadoop, proprietario dell'applicazione |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea e configura la migrazione. | Crea una migrazione nella dashboard dell' WANdisco interfaccia utente. Scegli la sorgente (HDFS) e la destinazione (il bucket S3). Aggiungi nuove esclusioni che hai definito nel passaggio precedente. Seleziona l'opzione «Sovrascrivi» o «Ignora se le dimensioni corrispondono». Crea la migrazione quando tutti i campi sono completi. | Amministratore Hadoop, proprietario dell'applicazione |
Avvia la migrazione. | Nella dashboard, seleziona la migrazione che hai creato. Fai clic per avviare la migrazione. Puoi anche avviare una migrazione automaticamente scegliendo l'opzione di avvio automatico al momento della creazione della migrazione. | Proprietario dell'applicazione |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Imposta un limite di larghezza di banda di rete tra l'origine e la destinazione. | Nell'elenco Archiviazioni sulla dashboard, seleziona lo spazio di archiviazione di origine e seleziona «Gestione della larghezza di banda» nell'elenco di raggruppamento. Deseleziona l'opzione illimitata e definisci il limite e l'unità di larghezza di banda massimi. Scegli «Applica». | Proprietario dell'applicazione, Networking |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Visualizza le informazioni sulla migrazione utilizzando l' WANdisco interfaccia utente. | Utilizza l' WANdisco interfaccia utente per visualizzare le informazioni su licenza, larghezza di banda, archiviazione e migrazione. L'interfaccia utente fornisce anche un sistema di notifica che consente di ricevere notifiche su errori, avvisi o tappe importanti dell'utilizzo. | Amministratore Hadoop, proprietario dell'applicazione |
Interrompi, riprendi ed elimina le migrazioni. | È possibile impedire a una migrazione di trasferire contenuti verso la destinazione impostando lo stato STOPPED. Le migrazioni interrotte possono essere riprese. È inoltre possibile eliminare le migrazioni nello stato STOPPED. | Amministratore Hadoop, proprietario dell'applicazione |
Risorse correlate
WANdisco LiveData Dimostrazione di Migrator
(video)
Informazioni aggiuntive
LiveData Installazione di Migrator
Potete usare i seguenti comandi per installare LiveData Migrator, supponendo che il programma di installazione si trovi nella vostra directory di lavoro:
su – hdfs chmod +x livedata-migrator.sh && sudo ./livedata-migrator.sh
Verifica dello stato di LiveData Migrator e degli altri servizi dopo l'installazione
Usa i seguenti comandi per controllare lo stato di LiveData Migrator, Hive migrator e UI: WANdisco
service livedata-migrator status service hivemigrator status service livedata-ui status
