Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Addestra e distribuisci un modello ML personalizzato supportato da GPU su Amazon SageMaker
Ankur Shukla, Amazon Web Services
Riepilogo
L'addestramento e l'implementazione di un modello di machine learning (ML) supportato da un'unità di elaborazione grafica (GPU) richiedono una configurazione iniziale e l'inizializzazione di determinate variabili di ambiente per sfruttare appieno i vantaggi di NVIDIA. GPUs Tuttavia, configurare l'ambiente e renderlo compatibile con l' SageMaker architettura Amazon sul cloud Amazon Web Services (AWS) può richiedere molto tempo.
Questo modello ti aiuta ad addestrare e creare un modello ML personalizzato supportato da GPU utilizzando Amazon. SageMaker Fornisce i passaggi per addestrare e implementare un CatBoost modello personalizzato basato su un set di dati di Amazon Reviews open source. Puoi quindi analizzarne le prestazioni su un'istanza p3.16xlarge Amazon Elastic Compute Cloud EC2 (Amazon).
Questo modello è utile se la tua organizzazione desidera implementare modelli ML esistenti supportati da GPU su. SageMaker I data scientist possono seguire i passaggi di questo schema per creare contenitori supportati da GPU NVIDIA e implementare modelli ML su tali contenitori.
Prerequisiti e limitazioni
Prerequisiti
Un account AWS attivo.
Un bucket sorgente Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3) per archiviare gli artefatti e le previsioni del modello.
Comprensione delle istanze dei notebook e dei SageMaker notebook Jupyter.
Informazioni su come creare un ruolo AWS Identity and Access Management (IAM) con autorizzazioni di SageMaker ruolo di base, autorizzazioni di accesso e aggiornamento ai bucket S3 e autorizzazioni aggiuntive per Amazon Elastic Container Registry (Amazon ECR).
Limitazioni
Questo modello è destinato ai carichi di lavoro ML supervisionati con un codice di addestramento e distribuzione scritto in Python.
Architettura
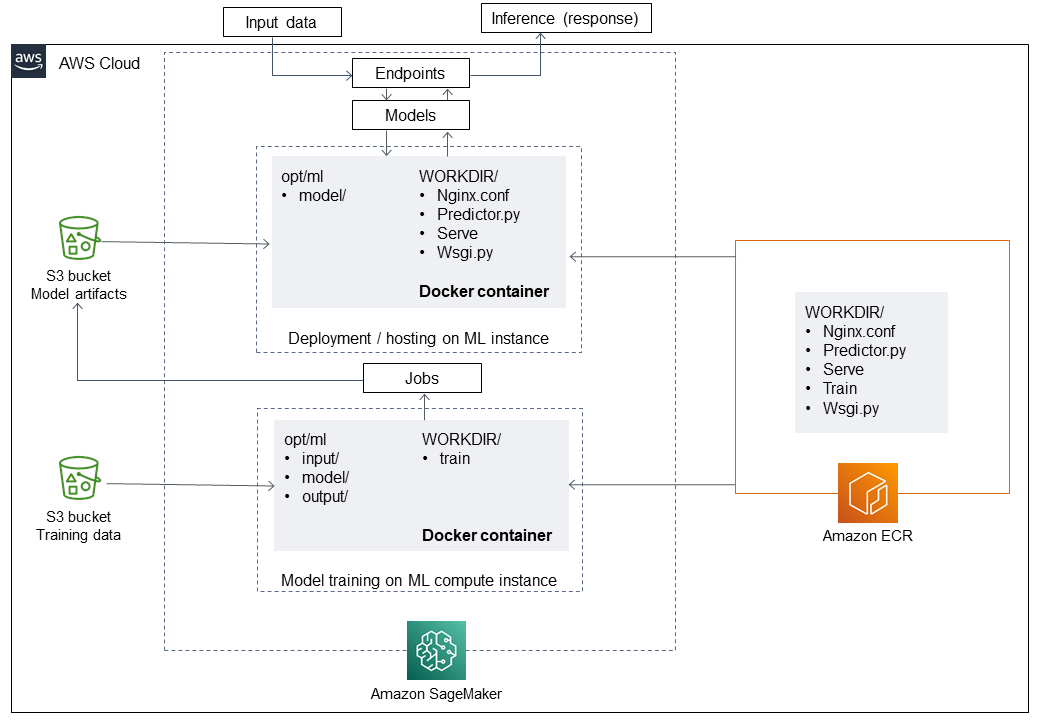
Stack tecnologico
SageMaker
Amazon ECR
Strumenti
Strumenti
Amazon ECR — Amazon Elastic Container Registry (Amazon ECR) è un servizio di registro di immagini di container gestito da AWS sicuro, scalabile e affidabile.
Amazon SageMaker: SageMaker è un servizio di machine learning completamente gestito.
Docker
: Docker è una piattaforma software per la creazione, il test e la distribuzione rapida di applicazioni. Python — Python
è un linguaggio di programmazione.
Codice
Il codice per questo modello è disponibile in GitHub Implementazione di un modello di classificazione delle recensioni con Catboost
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un ruolo IAM e allega le policy richieste. | Accedi alla Console di gestione AWS, apri la console IAM e crea un nuovo ruolo IAM. Collega al ruolo IAM le policy seguenti:
Per ulteriori informazioni su questo argomento, consulta Creare un'istanza notebook nella SageMaker documentazione di Amazon. | Data scientist |
Crea l'istanza del SageMaker notebook. | Apri la SageMaker console, scegli Istanze Notebook, quindi scegli Crea istanza Notebook. Per il ruolo IAM, scegli il ruolo IAM che hai creato in precedenza. Configura l'istanza del notebook in base ai tuoi requisiti, quindi scegli Crea istanza notebook. Per passaggi e istruzioni dettagliate, consulta Creare un'istanza notebook nella SageMaker documentazione di Amazon. | Data scientist |
Clonare il repository. | Apri il terminale nell'istanza del SageMaker notebook e clona il modello di classificazione GitHub Implementing a review con Catboost e SageMaker
| |
Avvia il notebook Jupyter. | Avvia il notebook | Data scientist |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Esegui i comandi nel notebook Jupyter. | Apri il notebook Jupyter ed esegui i comandi delle seguenti storie per preparare i dati per addestrare il tuo modello ML. | Data scientist |
Leggi i dati dal bucket S3. |
| Data scientist |
Preelabora i dati. |
NotaQuesto codice sostituisce i valori nulli in
| Data scientist |
Suddividi i dati in set di dati di addestramento, convalida e test. |
| Data scientist |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Prepara e invia l'immagine Docker. | Nel notebook Jupyter, esegui i comandi descritti nelle seguenti storie per preparare l'immagine Docker e inviarla ad Amazon ECR. | Ingegnere ML |
Crea un repository in Amazon ECR. |
| Ingegnere ML |
Crea un'immagine Docker localmente. |
| Ingegnere ML |
Esegui l'immagine Docker e inviala ad Amazon ECR. |
| Ingegnere ML |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un lavoro di ottimizzazione degli SageMaker iperparametri. | Nel notebook Jupyter, esegui i comandi descritti nelle seguenti storie per creare un processo di ottimizzazione degli SageMaker iperparametri utilizzando la tua immagine Docker. | Data scientist |
Crea uno stimatore. SageMaker | Crea uno SageMaker stimatore
| Data scientist |
Crea un lavoro HPO. | Crea un processo di ottimizzazione degli iperparametri (HPO) con intervalli di parametri e passa il treno e i set di convalida come parametri alla funzione.
| Data scientist |
Esegui il job HPO. |
| Data scientist |
Ricevi il lavoro di formazione con le migliori prestazioni. |
| Data scientist |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un SageMaker processo di trasformazione in batch sui dati di test per la previsione dei modelli. | Nel notebook Jupyter, esegui i comandi descritti nelle seguenti storie per creare il modello in base al processo di ottimizzazione degli SageMaker iperparametri e invia un processo di trasformazione in SageMaker batch sui dati di test per la previsione del modello. | Data scientist |
Create il modello. SageMaker | Crea un modello in SageMaker modello utilizzando il miglior lavoro di formazione.
| Data scientist |
Crea un processo di trasformazione in batch. | Crea un processo di trasformazione in batch sul set di dati di test.
| Data scientist |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Leggi i risultati e valuta le prestazioni del modello. | Nel notebook Jupyter, esegui i comandi delle seguenti storie per leggere i risultati e valutare le prestazioni del modello in base alle metriche dei modelli Area Under the ROC Curve (ROC-AUC) e Area Under the Precision Recall Curve (PR-AUC). Per ulteriori informazioni a riguardo, consulta i concetti chiave di Amazon Machine Learning nella documentazione di Amazon Machine Learning (Amazon ML). | Data scientist |
Leggi i risultati del processo di trasformazione in batch. | Leggi i risultati del processo di trasformazione in batch in un frame di dati.
| Data scientist |
Valuta le metriche delle prestazioni. | Valuta le prestazioni del modello su ROC-AUC e PR-AUC.
| Data scientist |
Risorse correlate
Informazioni aggiuntive
L'elenco seguente mostra i diversi elementi del Dockerfile che vengono eseguiti nell'immagine Build, run e push dell'immagine Docker in Amazon ECR epic.
Installa Python con aws-cli.
FROM amazonlinux:1 RUN yum update -y && yum install -y python36 python36-devel python36-libs python36-tools python36-pip && \ yum install gcc tar make wget util-linux kmod man sudo git -y && \ yum install wget -y && \ yum install aws-cli -y && \ yum install nginx -y && \ yum install gcc-c++.noarch -y && yum clean all
Installa i pacchetti Python
RUN pip-3.6 install --no-cache-dir --upgrade pip && \pip3 install --no-cache-dir --upgrade setuptools && \ pip3 install Cython && \ pip3 install --no-cache-dir numpy==1.16.0 scipy==1.4.1 scikit-learn==0.20.3 pandas==0.24.2 \ flask gevent gunicorn boto3 s3fs matplotlib joblib catboost==0.20.2
Installa CUDA e cuDNN
RUN wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run \ && chmod u+x cuda_9.0.176_384.81_linux-run \ && ./cuda_9.0.176_384.81_linux-run --tmpdir=/data --silent --toolkit --override \ && wget https://custom-gpu-sagemaker-image.s3.amazonaws.com/installation/cudnn-9.0-linux-x64-v7.tgz \ && tar -xvzf cudnn-9.0-linux-x64-v7.tgz \ && cp /data/cuda/include/cudnn.h /usr/local/cuda/include \ && cp /data/cuda/lib64/libcudnn* /usr/local/cuda/lib64 \ && chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* \ && rm -rf /data/*
Crea la struttura di directory richiesta per SageMaker
RUN mkdir /opt/ml /opt/ml/input /opt/ml/input/config /opt/ml/input/data /opt/ml/input/data/training /opt/ml/model /opt/ml/output /opt/program
Imposta le variabili di ambiente NVIDIA
ENV PYTHONPATH=/opt/program ENV PYTHONUNBUFFERED=TRUE ENV PYTHONDONTWRITEBYTECODE=TRUE ENV PATH="/opt/program:${PATH}" # Set NVIDIA mount environments ENV LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:$LD_LIBRARY_PATH ENV NVIDIA_VISIBLE_DEVICES="all" ENV NVIDIA_DRIVER_CAPABILITIES="compute,utility" ENV NVIDIA_REQUIRE_CUDA "cuda>=9.0"
Copia i file di addestramento e inferenza nell'immagine Docker
COPY code/* /opt/program/ WORKDIR /opt/program
