Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Elaborazione di query SQL in Amazon Redshift
Amazon Redshift instrada una query SQL inviata attraverso il parser e l'ottimizzatore in modo da sviluppare un piano di query. Quindi il motore di esecuzione traduce il piano di query in un codice che invia ai nodi di calcolo per l'esecuzione. Prima di progettare un piano di query, è fondamentale capire come funziona l'elaborazione delle query.
Pianificazione di query e flusso di lavoro di esecuzione
Il diagramma seguente fornisce una panoramica di alto livello del flusso di lavoro di pianificazione ed esecuzione delle query.
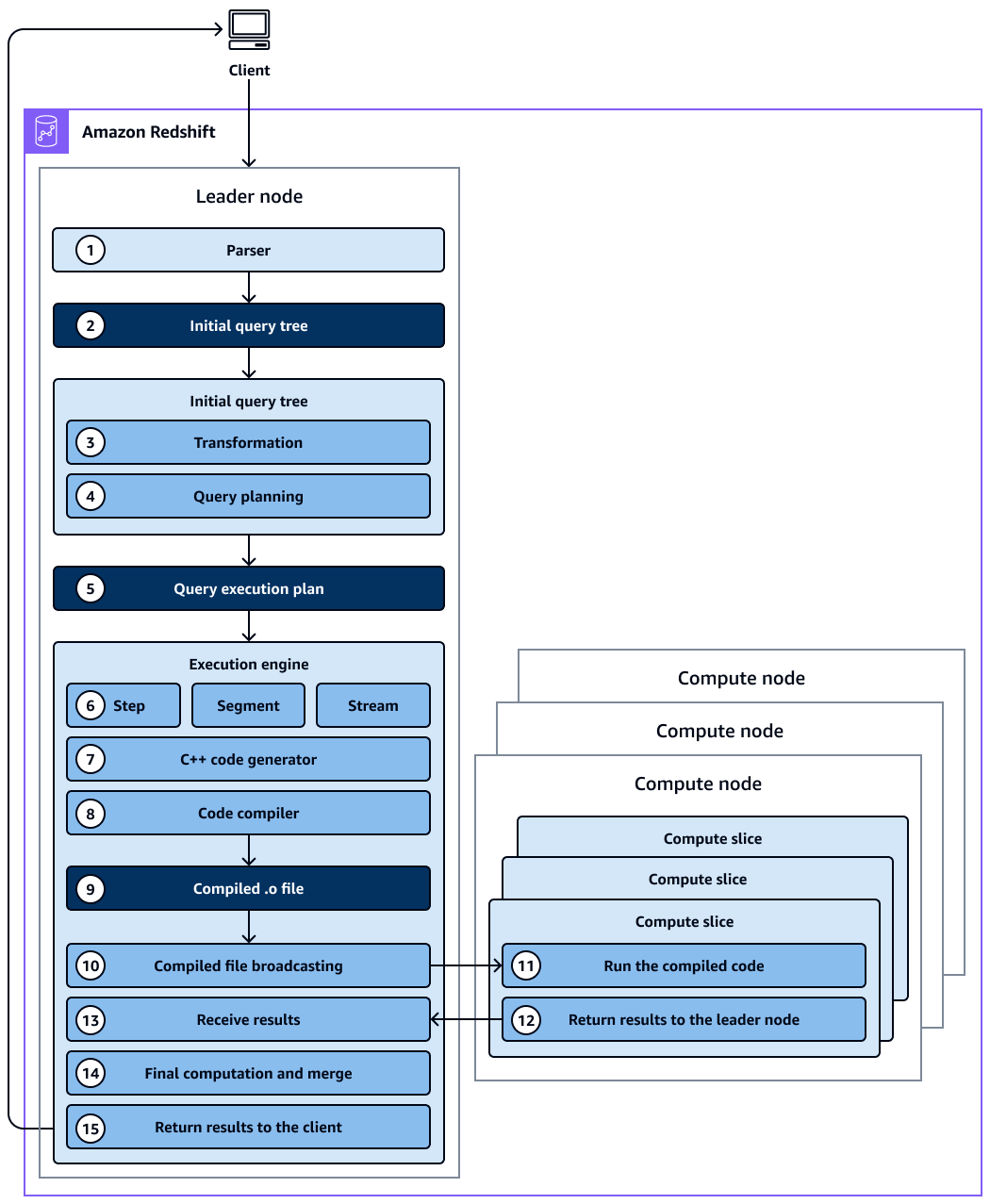
Il diagramma mostra il flusso di lavoro seguente:
-
Il nodo leader del cluster Amazon Redshift riceve la query e analizza l'istruzione SQL.
-
Il parser produce un albero di query iniziale che è una rappresentazione logica della query originale.
-
L'ottimizzatore delle query prende l'albero delle query iniziale e lo valuta, analizza le statistiche delle tabelle per determinare l'ordine di unione e la selettività dei predicati e, se necessario, riscrive la query per massimizzarne l'efficienza. A volte una singola query può essere scritta come diverse istruzioni dipendenti in background.
-
L'ottimizzatore genera un piano di query (o più di uno, se la fase precedente ha prodotto più query) per l'esecuzione con le prestazioni migliori. Il piano di query specifica opzioni di esecuzione come ordine di esecuzione, operazioni di rete, tipi di join, ordine di join, opzioni di aggregazione e distribuzioni di dati.
-
Un piano di interrogazione contiene informazioni sulle singole operazioni necessarie per eseguire una query. Puoi utilizzare il comando
EXPLAINper visualizzare il piano di query. Il piano di query è uno strumento fondamentale per l'analisi e l'ottimizzazione di query complesse. -
L'ottimizzatore delle query invia il piano di query al motore di esecuzione. Il motore di esecuzione verifica la corrispondenza del piano compilato nella cache del piano di interrogazione e utilizza la cache compilata (se trovata). Altrimenti, il motore di esecuzione traduce il piano di query in passaggi, segmenti e flussi:
-
I passaggi sono singole operazioni che avvengono durante l'esecuzione delle query. Le fasi sono identificate da un'etichetta (ad esempio
scan,dist,hjoin, omerge). Un gradino è l'unità più piccola. È possibile combinare i passaggi in modo che i nodi di calcolo possano eseguire una query, un join o un'altra operazione sul database. -
Un segmento si riferisce a un segmento di una query e combina diversi passaggi che possono essere eseguiti da un unico processo. Un segmento è l'unità di compilazione più piccola eseguibile da una slice di nodo di calcolo. Una sezione è l'unità di elaborazione parallela in Amazon Redshift.
-
Uno stream è una raccolta di segmenti da suddividere tra le slice del nodo di calcolo disponibili. I segmenti di un flusso vengono eseguiti in parallelo su sezioni di nodi. Pertanto, lo stesso passaggio dello stesso segmento viene eseguito anche in parallelo in più slice.
-
-
Il generatore di codice riceve il piano tradotto e genera una funzione C++ per ogni segmento.
-
La funzione C++ generata viene compilata dalla GNU Compiler Collection e convertita in un file O ().
.o -
Il codice compilato (file O) viene eseguito. I codici compilati vengono eseguiti più velocemente rispetto ai codici interpretati e utilizzano una minore capacità di elaborazione.
-
Il file O compilato viene quindi trasmesso ai nodi di calcolo.
-
Ogni nodo di calcolo è composto da diverse sezioni di calcolo. Le sezioni di calcolo eseguono i segmenti di query in parallelo. Amazon Redshift sfrutta la comunicazione di rete, la memoria e la gestione del disco ottimizzate per trasmettere risultati intermedi da una fase del piano di query all'altra. Ciò aiuta anche a velocizzare l'esecuzione delle query. Considera i seguenti aspetti:
-
I passaggi 6, 7, 8, 9, 10 e 11 si verificano una volta per ogni stream.
-
Il motore crea i segmenti eseguibili per uno stream e li invia ai nodi di calcolo.
-
Una volta completati i segmenti di uno stream precedente, il motore genera i segmenti per lo stream successivo. In questo modo, il motore riesce ad analizzare cosa è successo nel flusso precedente (ad esempio, se le operazioni erano basate su disco), al fine di influenzare la generazione di segmenti nel prossimo flusso.
-
-
Al termine, i nodi di calcolo restituiscono i risultati della query al nodo leader per l'elaborazione finale. Il nodo leader unisce i dati in un unico set di risultati e risolve qualsiasi ordinamento o aggregazione richiesti.
-
Il nodo leader restituisce i risultati al client.
Il diagramma seguente mostra il flusso di lavoro di esecuzione di flussi, segmenti, fasi e sezioni di nodi di calcolo. Ricorda:
-
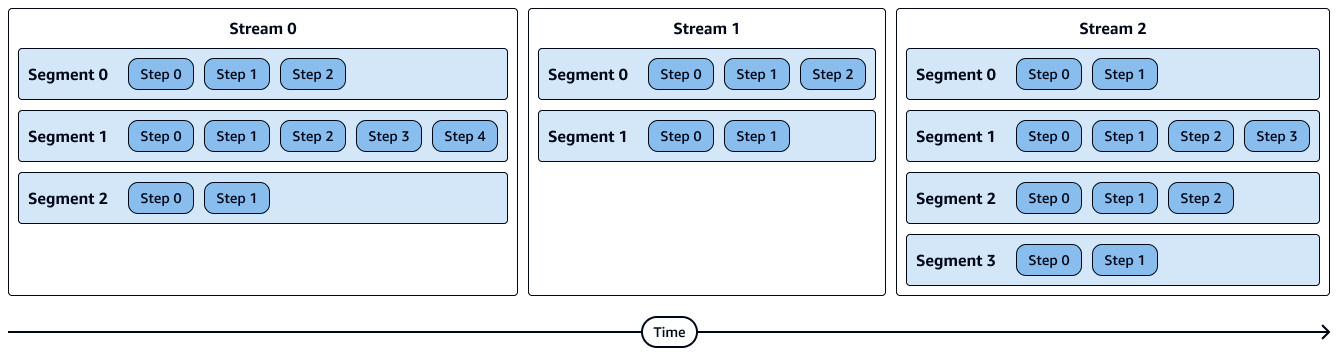
I passaggi di un segmento vengono eseguiti in sequenza.
-
I segmenti di un flusso vengono eseguiti in parallelo.
-
Gli stream vengono eseguiti in sequenza.
-
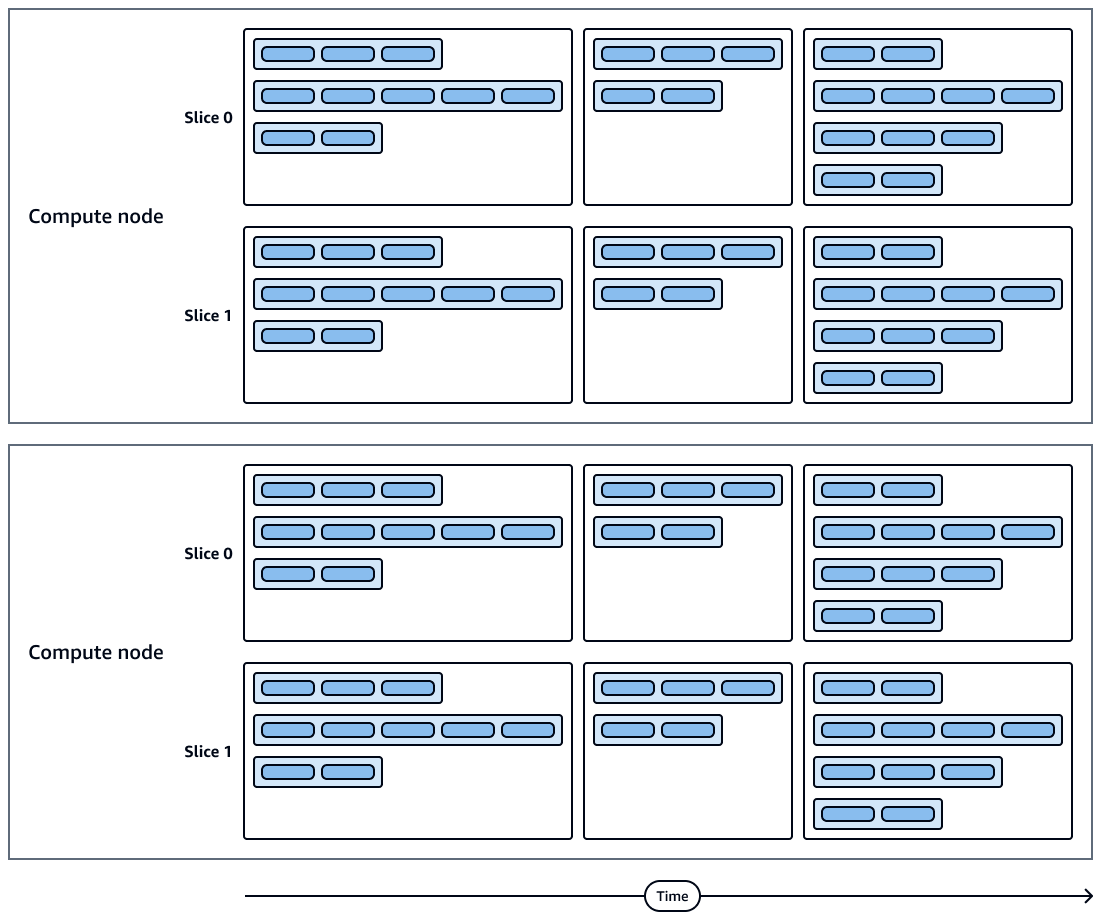
Le sezioni del nodo di calcolo vengono eseguite in parallelo.
Il diagramma seguente mostra una rappresentazione visiva di flussi, segmenti e passaggi. Ogni segmento contiene più passaggi e ogni stream contiene più segmenti.
Il diagramma seguente mostra una rappresentazione visiva delle esecuzioni di query e delle porzioni dei nodi di calcolo. Ogni nodo di calcolo contiene più sezioni, flussi, segmenti e passaggi.
Ulteriori considerazioni
Per quanto riguarda l'elaborazione delle query, si consiglia di considerare quanto segue:
-
Il codice compilato nella cache viene condiviso tra le sessioni sullo stesso cluster, quindi le esecuzioni successive della stessa query saranno più rapide, spesso anche con parametri diversi.
-
Quando esegui il benchmark delle tue query, ti consigliamo di confrontare sempre i tempi per la seconda esecuzione di una query, poiché il primo tempo di esecuzione include il sovraccarico della compilazione del codice. Per ulteriori informazioni, consulta i fattori di prestazione delle query nella guida Query best practice per Amazon Redshift.
-
I nodi di calcolo potrebbero restituire alcuni dati al nodo leader durante l'esecuzione delle query, se necessario. Ad esempio, se si dispone di una sottoquery con una
LIMITclausola, il limite viene applicato al nodo leader prima che i dati vengano ridistribuiti nel cluster per un'ulteriore elaborazione.
