Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Caso d'uso: creazione di un'applicazione di intelligence medica con dati aumentati sui pazienti
L'intelligenza artificiale generativa può aiutare ad aumentare l'assistenza ai pazienti e la produttività del personale migliorando le funzioni cliniche e amministrative. L'analisi delle immagini basata sull'intelligenza artificiale, come l'interpretazione delle ecografie, accelera i processi diagnostici e migliora la precisione. Può fornire informazioni critiche a supporto di interventi medici tempestivi.
Quando si combinano modelli di intelligenza artificiale generativi con grafici di conoscenza, è possibile automatizzare l'organizzazione cronologica delle cartelle cliniche elettroniche dei pazienti. Ciò consente di integrare i dati in tempo reale provenienti dalle interazioni medico-paziente, dai sintomi, dalle diagnosi, dai risultati di laboratorio e dall'analisi delle immagini. Ciò fornisce al medico dati completi sui pazienti. Questi dati aiutano il medico a prendere decisioni mediche più accurate e tempestive, migliorando sia gli esiti dei pazienti che la produttività degli operatori sanitari.
Panoramica della soluzione
L'intelligenza artificiale può potenziare medici e medici sintetizzando i dati dei pazienti e le conoscenze mediche per fornire informazioni preziose. Questa soluzione Retrieval Augmented Generation (RAG) è un motore di intelligence medica che utilizza un set completo di dati e conoscenze dei pazienti derivanti da milioni di interazioni cliniche. Sfrutta la potenza dell'intelligenza artificiale generativa per creare informazioni basate sull'evidenza per migliorare l'assistenza ai pazienti. È progettato per migliorare i flussi di lavoro clinici, ridurre gli errori e migliorare gli esiti dei pazienti.
La soluzione include una funzionalità di elaborazione delle immagini automatizzata basata su. LLMs Questa funzionalità riduce il tempo che il personale medico deve dedicare manualmente alla ricerca di immagini diagnostiche simili e all'analisi dei risultati diagnostici.
L'immagine seguente mostra i vantaggi end-to-end-workflow di questa soluzione. Utilizza Amazon Neptune, Amazon AI, SageMaker OpenSearch Amazon Service e un modello base in Amazon Bedrock. Per l'agente di recupero del contesto che interagisce con il Medical Knowledge Graph di Neptune, puoi scegliere tra un agente Amazon Bedrock e un LangChain agente.
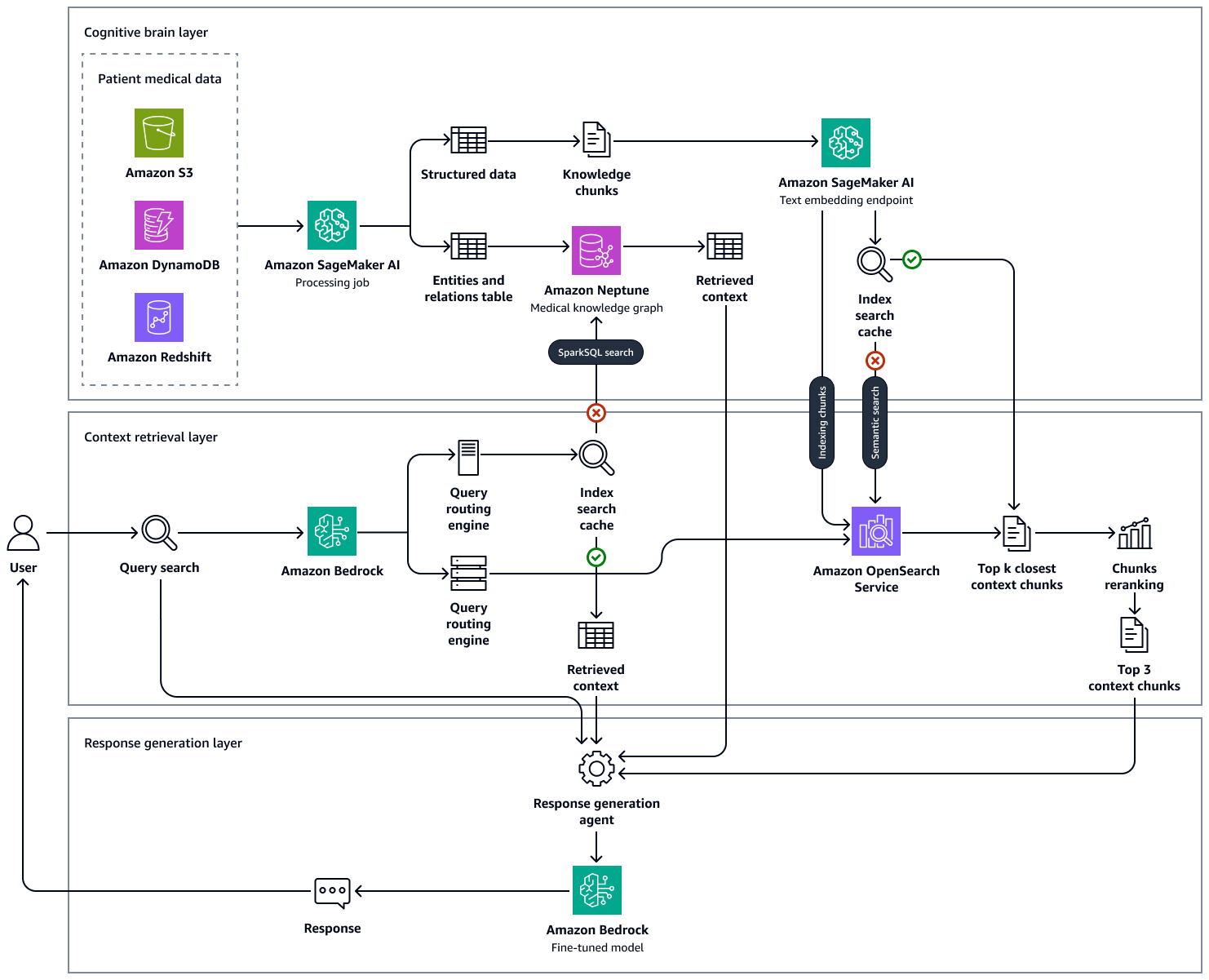
Nei nostri esperimenti con esempi di domande mediche, abbiamo osservato che le risposte finali generate dal nostro approccio utilizzando il Knowledge Graph gestito in Neptune OpenSearch, il database vettoriale che ospita la knowledge base clinica e Amazon LLMs Bedrock erano fondate sulla fattualità e sono molto più accurate riducendo i falsi positivi e aumentando i veri positivi. Questa soluzione può generare informazioni basate sull'evidenza sullo stato di salute del paziente e mira a migliorare i flussi di lavoro clinici, ridurre gli errori e migliorare gli esiti dei pazienti.
La creazione di questa soluzione prevede i seguenti passaggi:
Fase 1: Scoperta dei dati
Esistono molti set di dati medici open source che puoi utilizzare per supportare lo sviluppo di una soluzione sanitaria basata sull'intelligenza artificiale. Uno di questi set di dati è il set di dati MIMIC-IV, un set
È inoltre possibile utilizzare un set di dati che fornisca riepiloghi delle dimissioni dei pazienti annotati e anonimi, appositamente curati per scopi di ricerca. Un set di dati riepilogativi sulle dimissioni può aiutarvi a sperimentare l'estrazione delle entità, consentendovi di identificare le entità mediche chiave (come condizioni, procedure e farmaci) dal testo. Fase 2: Creazione di un grafico delle conoscenze medichein questa guida viene descritto come utilizzare i dati strutturati estratti dai set di dati riassuntivi MIMIC-IV e sulle dimissioni per creare un grafico delle conoscenze mediche. Questo grafico della conoscenza medica funge da spina dorsale per sistemi avanzati di interrogazione e supporto decisionale per gli operatori sanitari.
Oltre ai set di dati basati su testo, puoi utilizzare set di dati di immagini. Ad esempio, il set di dati Musculoskeletal Radiographs (MURA), che è un database completo di immagini radiografiche a più viste
Fase 2: Creazione di un grafico delle conoscenze mediche
Per qualsiasi organizzazione sanitaria che desideri creare un sistema di supporto decisionale basato su un'enorme base di conoscenze, una sfida fondamentale è individuare ed estrarre le entità mediche presenti nelle note cliniche, nelle riviste mediche, nei riepiloghi delle dimissioni e in altre fonti di dati. È inoltre necessario acquisire le relazioni temporali, i soggetti e le valutazioni di certezza da queste cartelle cliniche per utilizzare efficacemente le entità, gli attributi e le relazioni estratti.
Il primo passo consiste nell'estrarre concetti medici dal testo medico non strutturato utilizzando un prompt in pochi passaggi per un modello base, come Llama 3 in Amazon Bedrock. Il prompt Few-shot si verifica quando si fornisce a un LLM un numero limitato di esempi che dimostrano l'attività e l'output desiderato prima di chiedergli di eseguire un'attività simile. Utilizzando un estrattore di entità mediche basato su LLM, è possibile analizzare il testo medico non strutturato e quindi generare una rappresentazione strutturata dei dati delle entità con conoscenze mediche. È inoltre possibile memorizzare gli attributi del paziente per l'analisi e l'automazione a valle. Il processo di estrazione dell'entità include le seguenti azioni:
-
Estrai informazioni su concetti medici, come malattie, farmaci, dispositivi medici, dosaggio, frequenza dei farmaci, durata del farmaco, sintomi, procedure mediche e relative caratteristiche clinicamente rilevanti.
-
Acquisisci le caratteristiche funzionali, come le relazioni temporali tra le entità estratte, i soggetti e le valutazioni di certezza.
-
Espandi i vocabolari medici standard, come i seguenti:
-
Codici della classificazione internazionale delle malattie, decima revisione, modifica clinica (ICD-10-CM
) -
Termini tratti da Medical
Subject Headings (MeSH) -
Concetti tratti dalla nomenclatura sistematizzata della medicina,
termini clinici (SNOMED CT)
-
Riassumi le note di dimissione e ricava informazioni mediche dalle trascrizioni.
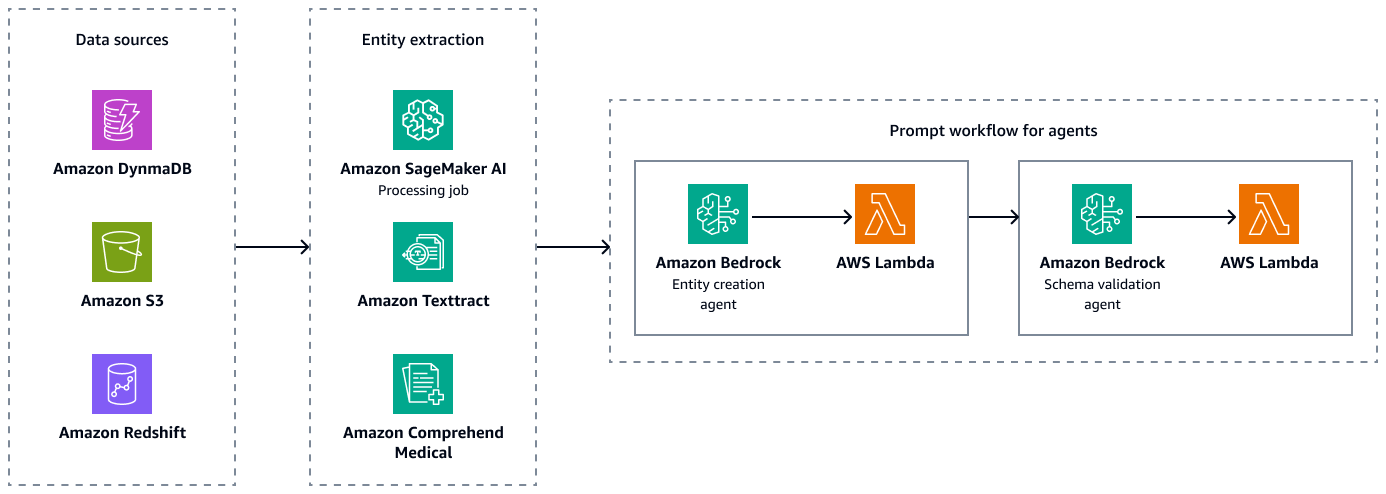
La figura seguente mostra le fasi di estrazione delle entità e di convalida dello schema per creare combinazioni accoppiate valide di entità, attributi e relazioni. Puoi archiviare dati non strutturati, come riepiloghi delle dimissioni o note sui pazienti, in Amazon Simple Storage Service (Amazon S3). Puoi archiviare dati strutturati, come dati di pianificazione delle risorse aziendali (ERP), cartelle cliniche elettroniche dei pazienti e sistemi informativi di laboratorio, in Amazon Redshift e Amazon DynamoDB. Puoi creare un agente per la creazione di entità Amazon Bedrock. Questo agente può integrare servizi, come le pipeline di estrazione dei dati Amazon SageMaker AI, Amazon Textract e Amazon Comprehend Medical, per estrarre entità, relazioni e attributi dalle fonti di dati strutturate e non strutturate. Infine, utilizzi un agente di convalida dello schema Amazon Bedrock per assicurarti che le entità e le relazioni estratte siano conformi allo schema grafico predefinito e mantengano l'integrità delle connessioni nodo-edge e delle proprietà associate.
Dopo l'estrazione e la convalida delle entità, delle relazioni e degli attributi, puoi collegarli per creare una subject-object-predicate tripletta. Questi dati vengono importati in un database grafico di Amazon Neptune, come illustrato nella figura seguente. I database grafici sono ottimizzati per archiviare e interrogare le relazioni tra gli elementi di dati.
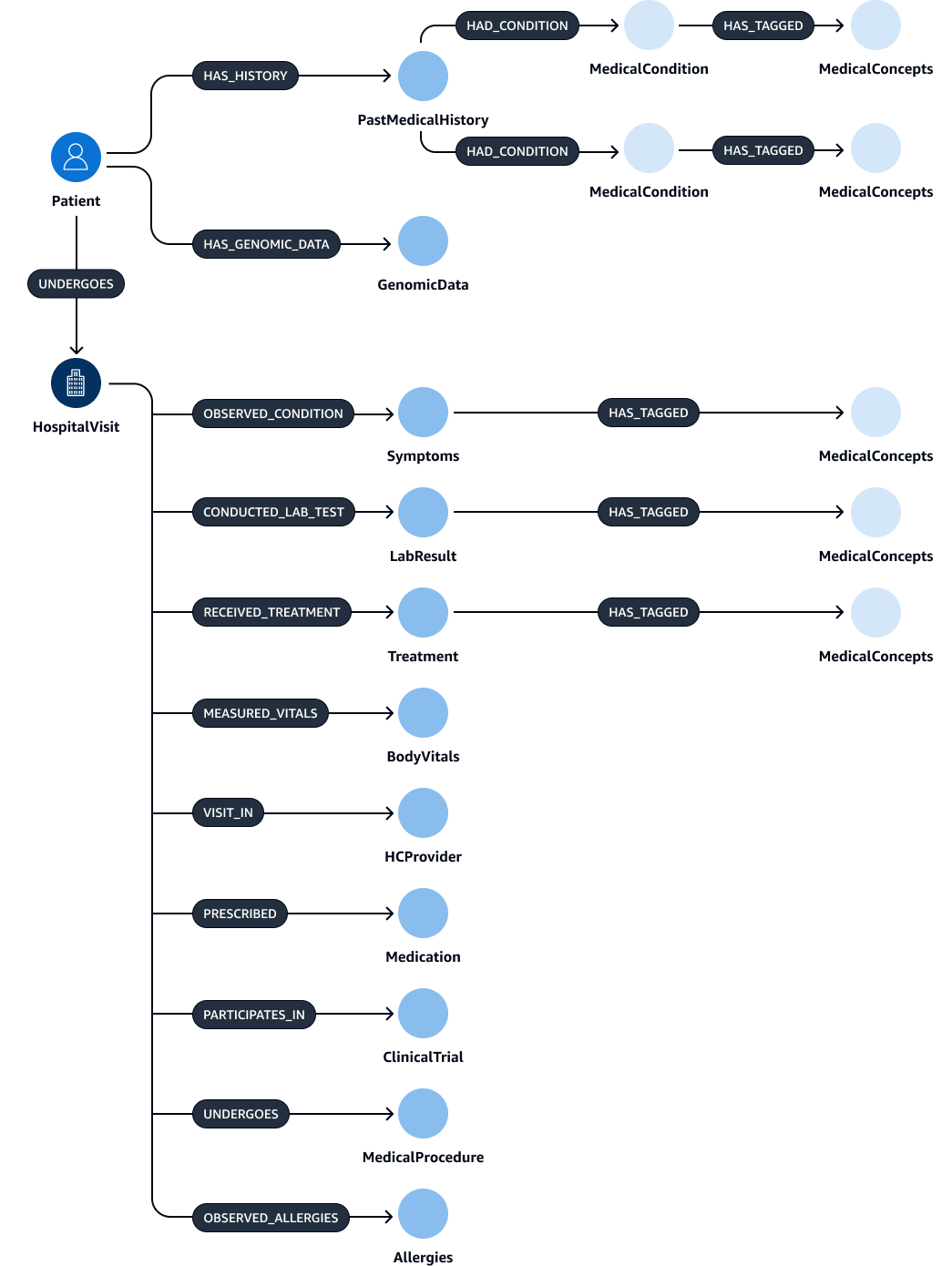
È possibile creare un grafico della conoscenza completo con questi dati. Un Knowledge GraphHospitalVisitPastMedicalHistory,Symptoms,Medication,MedicalProcedures, eTreatment.
Nelle tabelle seguenti sono elencate le entità e i relativi attributi che è possibile estrarre dalle note di discarica.
| Entità | Attributes |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
La tabella seguente elenca le relazioni che le entità possono avere e gli attributi corrispondenti. Ad esempio, l'Patiententità potrebbe connettersi all'HospitalVisitentità con la [UNDERGOES] relazione. L'attributo per questa relazione èVisitDate.
| Entità oggetto | Relazione | Entità oggetto | Attributes |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Nessuno |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Nessuna |
|
|
|
Nessuna |
|
|
|
Nessuna |
|
|
|
Nessuno |
Fase 3: Creazione di agenti di recupero del contesto per interrogare il grafico delle conoscenze mediche
Dopo aver creato il database dei grafici medici, il passaggio successivo consiste nella creazione di agenti per l'interazione con i grafici. Gli agenti recuperano il contesto corretto e richiesto per la richiesta inserita da un medico o da un medico. Esistono diverse opzioni per configurare questi agenti che recuperano il contesto dal Knowledge Graph:
Agenti Amazon Bedrock per l'interazione con i grafici
Gli agenti Amazon Bedrock funzionano perfettamente con i database grafici di Amazon Neptune. Puoi eseguire interazioni avanzate tramite i gruppi di azioni Amazon Bedrock. Il gruppo di azioni avvia il processo chiamando una AWS Lambda funzione, che esegue le query OpenCypher di Neptune.
Per interrogare un Knowledge Graph, è possibile utilizzare due approcci distinti: esecuzione diretta delle query o interrogazione con incorporamento del contesto. Questi approcci possono essere applicati indipendentemente o combinati, a seconda del caso d'uso specifico e dei criteri di classificazione. Combinando entrambi gli approcci, è possibile fornire un contesto più completo all'LLM, che può migliorare i risultati. Di seguito sono riportati i due approcci di esecuzione delle query:
-
Esecuzione diretta delle query Cypher senza incorporamenti: la funzione Lambda esegue le query direttamente su Neptune senza alcuna ricerca basata sugli incorporamenti. Di seguito è riportato un esempio di questo approccio:
MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason = 'Acute Diabetes' AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation -
Esecuzione di query Direct Cypher utilizzando la ricerca di incorporamento: la funzione Lambda utilizza la ricerca di incorporamento per migliorare i risultati delle query. Questo approccio migliora l'esecuzione delle query incorporando gli incorporamenti, che sono rappresentazioni vettoriali dense di dati. Gli incorporamenti sono particolarmente utili quando la query richiede una somiglianza semantica o una comprensione più ampia che vada oltre le corrispondenze esatte. È possibile utilizzare modelli preformati o personalizzati per generare incorporamenti per ogni condizione medica. Di seguito è riportato un esempio di questo approccio:
CALL { WITH "Acute Diabetes" AS query_term RETURN search_embedding(query_term) AS similar_reasons } MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason IN similar reasons AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformationIn questo esempio, la
search_embedding("Acute Diabetes")funzione recupera condizioni semanticamente simili al «diabete acuto». Ciò aiuta la query a trovare anche pazienti affetti da condizioni come il prediabete o la sindrome metabolica.
L'immagine seguente mostra come gli agenti di Amazon Bedrock interagiscono con Amazon Neptune per eseguire una query Cypher su un grafico delle conoscenze mediche.
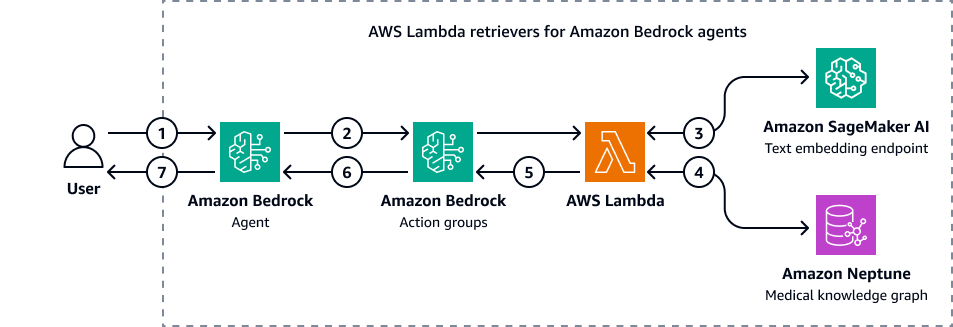
Il diagramma mostra il flusso di lavoro seguente:
-
L'utente invia una domanda all'agente Amazon Bedrock.
-
L'agente Amazon Bedrock trasmette le variabili del filtro di domanda e input ai gruppi di azione Amazon Bedrock. Questi gruppi di azioni contengono una AWS Lambda funzione che interagisce con l'endpoint di incorporamento di testi di Amazon SageMaker AI e il grafico delle conoscenze mediche di Amazon Neptune.
-
La funzione Lambda si integra con l'endpoint di incorporamento del testo SageMaker AI per eseguire una ricerca semantica all'interno della query OpenCypher. Converte la query in linguaggio naturale in una query OpenCypher utilizzando la funzione sottostante LangChain agenti.
-
La funzione Lambda interroga il Neptune Medical Knowledge Graph per trovare il set di dati corretto e riceve l'output dal Neptune Medical Knowledge Graph.
-
La funzione Lambda restituisce i risultati da Neptune ai gruppi di azioni Amazon Bedrock.
-
I gruppi di azione Amazon Bedrock inviano il contesto recuperato all'agente Amazon Bedrock.
-
L'agente Amazon Bedrock genera la risposta utilizzando la query originale dell'utente e il contesto recuperato dal knowledge graph.
LangChain agenti per l'interazione con i grafici
È possibile integrare LangChain con Neptune per consentire interrogazioni e recuperi basati su grafici. Questo approccio può migliorare i flussi di lavoro basati sull'intelligenza artificiale utilizzando le funzionalità del database grafico di Neptune. La personalizzazione LangChain il retriever funge da intermediario. Il modello base di Amazon Bedrock può interagire con Neptune utilizzando sia query Cypher dirette che algoritmi grafici più complessi.
Puoi utilizzare il retriever personalizzato per perfezionare il modo in cui LangChain l'agente interagisce con gli algoritmi del grafico di Neptune. Ad esempio, è possibile utilizzare few-shot prompting, che consente di personalizzare le risposte del modello di base in base a modelli o esempi specifici. Puoi anche applicare filtri identificati da LLM per rifinire il contesto e migliorare la precisione delle risposte. Ciò può migliorare l'efficienza e la precisione dell'intero processo di recupero quando si interagisce con dati grafici complessi.
L'immagine seguente mostra come una personalizzazione LangChain agent orchestra l'interazione tra un modello di base Amazon Bedrock e un grafico della conoscenza medica di Amazon Neptune.
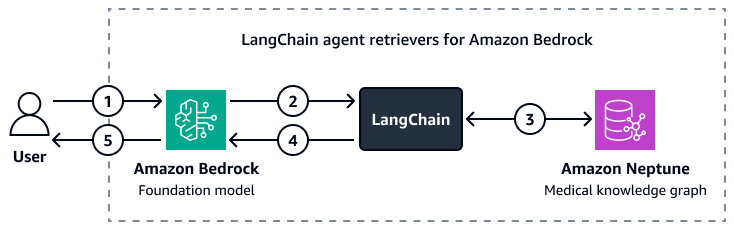
Il diagramma mostra il flusso di lavoro seguente:
-
Un utente invia una domanda ad Amazon Bedrock e al LangChain agente.
-
Il modello di base Amazon Bedrock utilizza lo schema Neptune, fornito da LangChain agente, per generare una query per la domanda dell'utente.
-
Il LangChain l'agente esegue la query sul grafico delle conoscenze mediche di Amazon Neptune.
-
Il LangChain agent invia il contesto recuperato al modello di base Amazon Bedrock.
-
Il modello di base Amazon Bedrock utilizza il contesto recuperato per generare una risposta alla domanda dell'utente.
Fase 4: creazione di una knowledge base di dati descrittivi in tempo reale
Successivamente, si crea una knowledge base di note descrittive sulle interazioni medico-paziente in tempo reale, valutazioni di immagini diagnostiche e rapporti di analisi di laboratorio. Questa knowledge base è un database vettoriale.
Utilizzo di una base di conoscenze mediche del Service OpenSearch
Amazon OpenSearch Service è in grado di gestire grandi volumi di dati medici ad alta dimensione. È un servizio gestito che facilita la ricerca ad alte prestazioni e l'analisi in tempo reale. È adatto come database vettoriale per applicazioni RAG. OpenSearch Il servizio funge da strumento di backend per gestire grandi quantità di dati non strutturati o semistrutturati, come cartelle cliniche, articoli di ricerca e note cliniche. Le sue funzionalità avanzate di ricerca semantica consentono di recuperare informazioni contestualmente rilevanti. Ciò lo rende particolarmente utile in applicazioni come i sistemi di supporto alle decisioni cliniche, gli strumenti per la risoluzione delle domande dei pazienti e i sistemi di gestione delle conoscenze sanitarie. Ad esempio, un medico può trovare rapidamente i dati pertinenti sui pazienti o gli studi di ricerca che corrispondono a sintomi o protocolli di trattamento specifici. Questo aiuta i medici a prendere decisioni basate sulla maggior parte delle informazioni up-to-date pertinenti.
OpenSearch Il servizio può scalare e gestire l'indicizzazione e l'interrogazione dei dati in tempo reale. Ciò lo rende ideale per ambienti sanitari dinamici in cui l'accesso tempestivo a informazioni accurate è fondamentale. Inoltre, dispone di funzionalità di ricerca multimodali ottimali per le ricerche che richiedono input multipli, come immagini mediche e note mediche. Quando si implementano le applicazioni OpenSearch Service for Healthcare, è fondamentale definire campi e mappature precisi per ottimizzare l'indicizzazione e il recupero dei dati. I campi rappresentano i singoli dati, come le cartelle cliniche dei pazienti, le anamnesi e i codici diagnostici. Le mappature definiscono il modo in cui questi campi vengono archiviati (nel modulo di incorporamento o nel modulo originale) e come vengono interrogati. Per le applicazioni sanitarie, è essenziale stabilire mappature che contengano vari tipi di dati, inclusi dati strutturati (come i risultati dei test numerici), dati semistrutturati (come le note dei pazienti) e dati non strutturati (come le immagini mediche)
In OpenSearch Service, è possibile eseguire query di ricerca neurale
Creazione di un'architettura RAG
Puoi implementare una soluzione RAG personalizzata che utilizza agenti Amazon Bedrock per interrogare una knowledge base medica in Service. OpenSearch A tale scopo, crei una AWS Lambda funzione in grado di interagire e interrogare Service. OpenSearch La funzione Lambda incorpora la domanda di input dell'utente accedendo a un endpoint di incorporamento di testo SageMaker AI. L'agente Amazon Bedrock trasmette parametri di query aggiuntivi come input alla funzione Lambda. La funzione interroga la knowledge base medica di OpenSearch Service, che restituisce i contenuti medici pertinenti. Dopo aver configurato la funzione Lambda, aggiungila come gruppo di azioni all'interno dell'agente Amazon Bedrock. L'agente Amazon Bedrock prende l'input dell'utente, identifica le variabili necessarie, passa le variabili e la domanda alla funzione Lambda e quindi avvia la funzione. La funzione restituisce un contesto che aiuta il modello di base a fornire una risposta più accurata alla domanda dell'utente.
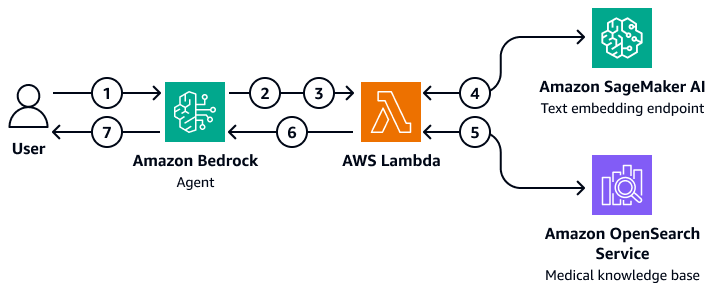
Il diagramma mostra il flusso di lavoro seguente:
-
Un utente invia una domanda all'agente Amazon Bedrock.
-
L'agente Amazon Bedrock seleziona il gruppo di azioni da avviare.
-
L'agente Amazon Bedrock avvia una AWS Lambda funzione e le trasmette i parametri.
-
La funzione Lambda avvia il modello di inserimento del testo di Amazon SageMaker AI per incorporare la domanda dell'utente.
-
La funzione Lambda passa il testo incorporato e parametri e filtri aggiuntivi ad Amazon OpenSearch Service. Amazon OpenSearch Service interroga la knowledge base medica e restituisce i risultati alla funzione Lambda.
-
La funzione Lambda restituisce i risultati all'agente Amazon Bedrock.
-
Il modello base dell'agente Amazon Bedrock genera una risposta basata sui risultati e restituisce la risposta all'utente.
Per le situazioni in cui sono necessari filtri più complessi, puoi utilizzare un filtro personalizzato LangChain recuperatore. Crea questo retriever configurando un client di ricerca vettoriale OpenSearch Service che viene caricato direttamente in LangChain. Questa architettura consente di passare più variabili per creare i parametri del filtro. Dopo aver configurato il retriever, usa il modello Amazon Bedrock e il retriever per configurare una catena di domande di recupero e risposta. Questa catena orchestra l'interazione tra il modello e il retriever passando l'input dell'utente e i potenziali filtri al retriever. Il retriever restituisce il contesto pertinente che aiuta il modello di base a rispondere alla domanda dell'utente.
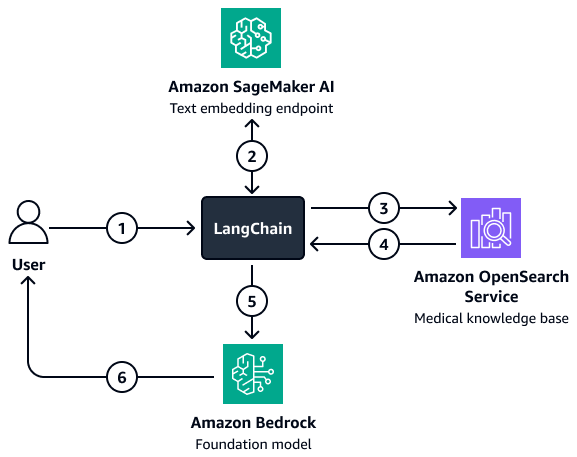
Il diagramma mostra il flusso di lavoro seguente:
-
Un utente invia una domanda al LangChain agente retriever.
-
Il LangChain retriever agent invia la domanda all'endpoint di incorporamento del testo Amazon SageMaker AI per incorporare la domanda.
-
Il LangChain retriever agent passa il testo incorporato ad Amazon OpenSearch Service.
-
Amazon OpenSearch Service restituisce i documenti recuperati al LangChain agente retriever.
-
Il LangChain retriever agent passa la domanda dell'utente e il contesto recuperato al modello Amazon Bedrock Foundation.
-
Il modello di base genera una risposta e la invia all'utente.
Fase 5: Utilizzo LLMs per rispondere a domande mediche
I passaggi precedenti consentono di creare un'applicazione di intelligence medica in grado di recuperare le cartelle cliniche di un paziente e riepilogare i farmaci pertinenti e le potenziali diagnosi. Ora crei il livello di generazione. Questo livello utilizza le funzionalità generative di un LLM in Amazon Bedrock, come Llama 3, per aumentare l'output dell'applicazione.
Quando un medico inserisce una query, il livello di recupero del contesto dell'applicazione esegue il processo di recupero dal Knowledge Graph e restituisce i record principali relativi all'anamnesi, ai dati demografici, ai sintomi, alla diagnosi e agli esiti del paziente. Dal database vettoriale, recupera anche note descrittive sull'interazione medico-paziente in tempo reale, approfondimenti sulla valutazione delle immagini diagnostiche, riassunti dei rapporti di analisi di laboratorio e approfondimenti da un enorme corpus di ricerche mediche e libri accademici. Questi principali risultati recuperati, la richiesta del medico e i prompt (che sono personalizzati per selezionare le risposte in base alla natura della domanda), vengono quindi passati al modello base di Amazon Bedrock. Questo è il livello di generazione della risposta. Il LLM utilizza il contesto recuperato per generare una risposta alla domanda del medico. La figura seguente mostra il end-to-end flusso di lavoro dei passaggi di questa soluzione.
Puoi utilizzare un modello di base pre-addestrato in Amazon Bedrock, come Llama 3, per una serie di casi d'uso che l'applicazione di intelligence medica deve gestire. Il LLM più efficace per una determinata attività varia a seconda del caso d'uso. Ad esempio, un modello pre-addestrato potrebbe essere sufficiente per riassumere le conversazioni tra paziente e medico, cercare tra i farmaci e le storie dei pazienti e recuperare informazioni dai set di dati medici interni e dalle conoscenze scientifiche. Tuttavia, potrebbe essere necessario un LLM ottimizzato per altri casi d'uso complessi, come valutazioni di laboratorio in tempo reale, raccomandazioni sulle procedure mediche e previsioni degli esiti dei pazienti. È possibile perfezionare un LLM addestrandolo su set di dati di dominio medico. Requisiti sanitari e delle scienze della vita specifici o complessi guidano lo sviluppo di questi modelli perfezionati.
Per ulteriori informazioni sulla messa a punto di un LLM o sulla scelta di un LLM esistente che sia stato formato sui dati del dominio medico, vedi Utilizzo di modelli linguistici di grandi dimensioni per i casi d'uso nel settore sanitario e delle scienze della vita.
Allineamento al Well-Architected AWS Framework
La soluzione si allinea a tutti e sei i pilastri del AWS Well-Architected
-
Eccellenza operativa: l'architettura è disaccoppiata per un monitoraggio e un aggiornamento efficienti. Agenti Amazon Bedrock e ti AWS Lambda aiutano a distribuire e ripristinare rapidamente gli strumenti.
-
Sicurezza: questa soluzione è progettata per rispettare le normative sanitarie, come l'HIPAA. Puoi anche implementare la crittografia, il controllo granulare degli accessi e i guardrail di Amazon Bedrock per proteggere i dati dei pazienti.
-
Affidabilità: i servizi AWS gestiti, come Amazon OpenSearch Service e Amazon Bedrock, forniscono l'infrastruttura per l'interazione continua dei modelli.
-
Efficienza delle prestazioni: la soluzione RAG recupera rapidamente i dati pertinenti utilizzando la ricerca semantica ottimizzata e le query Cypher, mentre un router agente identifica i percorsi ottimali per le query degli utenti.
-
Ottimizzazione dei costi: il pay-per-token modello dell'architettura Amazon Bedrock e RAG riduce i costi di inferenza e pre-formazione.
-
Sostenibilità: l'utilizzo dell'infrastruttura e dell' pay-per-tokenelaborazione serverless riduce al minimo l'utilizzo delle risorse e migliora la sostenibilità.
